Didn't find what you were looking for? It might be here:
2025 May 21
Hello world!
After making the tweaks to this blog to make it easier to post and publish more frequently, I discovered that I'd doubled my AWS S3 bill! 😅
Turns out that the process I set up over 7 years ago just re-uploads the entire site, every time I push a change.
That wasn't a noticeable problem until I started pushing multiple times per day.
So, I'm looking into a new workflow based on rclone that should be able to do more differential uploads based on changes.
The first version of that workflow deleted the contents of my blog. (Oops.) The second version re-uploaded everything in about 6 minutes.
One more thing I should write about if I get around to an entry describing the current state of this contraption.
Juggling a couple AI related ideas in my head that might turn into a longer post:
Seems to me like most AI-assisted tools these days are single-player and it's really hard to pass the baton of a project underway to someone else.
Seems to me like many folks using AI-assisted tools think they're the only Chosen One in the world with access to those tools and everyone else around is an agency-free NPC
Now I just have to make sure to use that flag right so I still don't include half-broken things here 😅
I should figure out a decent way for showing really long strings here, like the path names in that cloud saves post today 🤔
How the hell do I remember things like "Pumas on Hoverbikes is at monkeybagel.com" but I have to remind myself to eat lunch as a separate step from making lunch?
Companies aren't just cutting costs—they're conducting a fundamental reset to find their Minimum Viable Humans model. They're stripping organizations down to the ground—the irreducible human functions that (currently) can't be replaced or augmented by AI.
This rings true to what I've been seeing. The cruelty feels incidental to the process—not to me and everyone I know, mind you—but indignation won't pay my mortgage.
Trying to get your old job back is futile—that role, as you remember it, isn’t coming back. The opportunity now lies in positioning yourself for the roles and capabilities that will emerge as organizations rebuild from the bottom up—core human strengths like creativity and ethical judgment, the ability to collaborate with AI, your unique experience and expertise, and the kind of discernment that values judgment over process.
Brutal, yet maybe positive? If drudgery gets distilled out, what's left are human creativity, judgment, and experience. That sounds nice, like what classic sci-fi promised us.
But you can't mechanize that with a Taylorist time-and-motion study. Some jobs are just paychecks, some spark enthusiasm, and some flip between both unpredictably.
Will companies make allowances for that, while rewarding what they're asking for? I know we're seeing a reckoning right now, a firm snatching back from privileged labor. Fine, I don't need a free lunch or a foosball table, but I do need a health plan and a few days off. What's the churn for all of us while they figure that out?
The manager's role isn't just being eliminated—it's being fundamentally redefined from day-to-day oversight to exception handling, strategic communication, and resource allocation across much larger teams. It will keep going into augmenting the decision-making process for leaders and individual contributors alike. The boundaries of acceptable risk at all levels are now in a constant prototype state as AI becomes more powerful and faster, giving mere mortals more access to information and insight than ever before. The trick will be what training we need in order to make the pairing work.
This might suit an ADHD-head like me. I could see myself as a human relay, occasionally reallocating pylons and vespene gas amongst largely autonomous protoss units. I'm already having better luck than some with AI-assisted coding. Maybe I'm learning the magic invocations? Maybe I'm a special kind of moron? Either way, I'm ending up with working code and nodding heads. This gives me some hope that I can "stay current" - whatever that means in the current era.
Admittedly, I'm more comfortable directing Starcraft units and AI agents like this. That feels like a kind of management to me. I'm not so comfortable directing human co-workers with the same interface, though.
This isn't just another tech cycle. It's a fundamental recalibration of the human role in organizational life. And while there's no easy path through this transition, understanding what's actually happening might help you find your footing on shifting ground.
I keep slipping into snark because part of me finds this exciting while another part is cynical and burnt out. I'm hoping optimism holds out longer than cynicism. Maybe the thumbless neurotic puma driving a maroon AMC Gremlin have the last laugh after all? (Anybody get that reference anymore?) I dunno, I'm just trying to figure how much of this is like that surface rupture in Myanmar last week and whether my Crocs can carry me to the right side of it.
Ah, the problems of a masochistic nerd trying to game. For about a year now, my gaming PC has run Bazzite Linux because I got tired of Windows. I've also got a Game Pass subscription, prepaid for a long while from before I switched to Linux. This was not a well thought out plan.
While other game stores work pretty great, the only way to use my Game Pass subscription on Linux is via Xbox Cloud Gaming. The Xbox app doesn't on Linux and won't install Game Pass stuff locally on Linux. Still, streaming works pretty well for games I want to try and ditch when I get bored. But, it's so ephemeral that I wouldn't really want to commit to buying a game through that outright.
So, I started playing Clair Obscur: Expedition 33 via Cloud Gaming. After about 13 hours in, I realized I wanted to buy the game. As it turns out, Steam likes Linux and the game runs well there. It was on sale in a bundle, so I went ahead and bought it from Steam instead of from Xbox.
But, my 13-hour-old save game was trapped in the cloud. I guessed I'd just have to abandon it and start over. That is, until I pieced a few things together:
Thanks to Xbox Play Anywhere, the saves in Cloud Gaming sync down to PC game installations. I had one old Windows laptop left in the house that would install Game Pass games - it just played them horribly. Once I installed the game locally from Game Pass and booted it up once, my cloud save descended onto my laptop hard drive.
Then, I installed the game again from Steam - i.e. the copy I purchased. From there, I could follow this guide to transplant my save file from Game Pass to Steam. Once properly transplanted, the save game found its way onto Steam's cloud sync servers and then back onto my real gaming PC.
I realize this sounds like the plot to a dork heist. But, it worked!
Interesting bugs here in my Rube Goldberg blogging machine involving Syncthing and Obsidian, where sync conflicts become clashing ghost entries 🤔
I should tweak support for a draft flag here, so that posts that I'm still editing don't get published automatically. This flow is almost too frictionless, at this point.
I've been using Obsidian for about 5 years now for my daily notes. I've been tempted to take another swing at writing my own notebook, because I barely use any of Obsidian's fancier features. I mainly like that's it's a good cross-platform Markdown editor with a few plugins that I've settled on for regular use.
I have a vague notion to make a USB or wifi interface for an old Atari Video Touch Pad. Could use it as a Stream Deck (if I ever stream again) and / or hook it up to Home Assistant.
I need to find a better way to insert images like this 😅
I genuinely believe making games without a big "do everything" engine can be easier, more fun, and often less overhead. I am not making a "do everything" game and I do not need 90% of the features these engines provide. I am very particular about how my games feel and look, and how I interact with my tools. I often find the default feature implementations in large engines like Unity so lacking I end up writing my own anyway. Eventually, my projects end up being mostly my own tools and systems, and the engine becomes just a vehicle for a nice UI and some rendering...
I read blog posts and tutorials like this all the time. Every few months, I go on a spree of installing and firing up game development tools. I keep kind of wanting to actually end up finishing a game, kind of like how my dad used to make a few fly fishing lures but only ever managed to go fishing every few years. But, do I like reading about this stuff.
And this post snags me, in particular, because one of the reasons I even started poking around with game dev stuff was to learn. And what better way to really just plummet down the rabbit hole than to learn how to make a game engine almost from scratch?
Oh, but in terms of actually finishing things: I can say I made Poke the Mongo for Pico-8! That's at least one finished video game. It's got an itch.io page and an end-game screen and everything. I won't spoil the end screen, though I'm pretty sure I only know one other person who's ever seen it.
What if AI systems could generate precisely the right interface components when needed, without requiring developers to build every possible UI variation in advance? This post explores my work on a new prototype that enables LLMs to create dynamic, interactive UI components on demand, transforming how users interact with AI systems and MCP servers.
This is where LLMs are very interesting to me, where applications with them are most able to escape hype into practical building. A thing they're good at is taking some of the vague stuff we hand-wave at like "you know, that thing with the days in squares on it" and jumping to "you mean a calendar?" But then, skip straight from that to presenting a calendar for input as part of the workflow.
I'm finding LLMs most handy when they work in smaller universes. Give it a relatively small inventory of UI components, properly described with context, and they can be great at picking which one to use and when. Hard to hallucinate when there's not a wide range for wandering, easy to mitigate what hallucinations might occur when you can automatically kick it back into bounds. Meanwhile, the workflow can feel more smooth and demand less fiddly navigation from a user. That seems like a really promising glimmer to me.
...I follow a lot of feeds in my feed reader, most of them only updating at most once a month, maybe weekly, and only a tiny handful update daily. About seven hundred (700) of the feeds I follow are active and I’ve been following some of them since the early 2000s.
That’s a decent sample size both across fields – tech, media, and academia – and time – I’ve been following most of these since before COVID – and the decline in people’s thinking across many of these feeds has been noticeable because it’s incredibly fucking annoying.
My feeds suck, right now. My main excuse is I'm way out of the habit of blogging like I did 20 years ago. And I think part of that habit is thinking out loud, getting things out into words in front of me to clarify the thinking. Tweets and toots aren't really long enough to let a fully formed notion flop out of my head and thrash around on the desk for awhile.
I do know a lot of folks who got COVID, though. Gratefully, I seem to have avoided it so far. Is this like the notion that the Roman Empire collapsed due to lead poisoning? I do feel like there's a lot of stupidity out there right now, like more than I'd expect. I don't know if that's a conspiracy theory or just cynicism.
Even when it comes to something like LLM-assisted programming, where a highly skilled developer can maybe, sometimes, somewhat gain a performance boost, the most pertinent question isn't if it can be done at all - but rather if what can be done good enough can also be done profitably. The number of GPUs and the amount of increasingly expensive energy required remains as unclear as the time frame needed to accomplish it.
I don't disagree that this is where things are right now. Personally, I'm getting utility from these tools - mainly for things that I could do myself, but the LLM lets me carve off a few rounds of googling and Stack Overflow browsing. That's valuable. Probably not as valuable as investors are hoping, though.
I see some glimmers of potential in letting the agents rip in full-auto. But, I do also find that ofttimes they're developer slot machines that need careful tending to keep them from going off into the weeds, going into loops, and going off on quests for which I never asked.
I'm seeing the most value in these tools when they're given a lot of context and kept constrained to limited tasks in a tight loop with adult supervision. I've got a hunch this will improve over time, but who knows? We could hit a wall and see winter soon?
I'd really like it if this stuff would settle down and be normal. But, there's probably going to be a crash before that happens.
I listen to podcasts at between 1.8x - 2.5x, depending on the day's mental weather. That means, when I've met a podcaster I listen to, they sound drugged or drunk to me.
I’ve had folks tell me this sounds stressful. But, I get distracted in the gaps and my mind wanders. Easier for me to follow rapid word dumps.
This is not a flex, this is a coping strategy.
The new Peter Murphy album, "Silver Shade", sure is Peter Murphy.
I don't hate this at all.
I'm really digging the collabs he did here, teaming up with folks like Boy George, Trent Reznor, and Justin Chancellor.
Hey, you, service provider on the web that I pay for: I am annoyed that I'm constantly signed out when I come to visit. You don't remember me, and you are constantly trying to call-to-action and dark-pattern me into your growth hacks when I already have an account.
What if survival looked like ownership instead? What if the best response to getting laid off isn’t to get in the line to nowhere for the next thing, but to build your own thing? Do your own thing? The tools are there. The access is there. The demand is there.
We’ve got too many smart, experienced people standing at the edge of the workforce, assuming their only move is down or to keep trying what worked yesterday. From what I read many folks fear an AI fuled collapse, but I fear another powered by denial, retreat, and stubborn nostalgia. If enough of us take this route, we’re going to see a quiet, steady slide of educated, capable folks into poverty—and that’s not just a personal tragedy, it’s a societal one. And no amount of boycotting or avoiding AI is going to help.
I've been thinking a lot about this, lately. And I keep thinking about "my own thing" that I could build. I've had some ideas, but I'm not sure any of them are big enough to convince people to shovel enough money at me to pay my mortgage?
On top of that, I've never felt a particular urge to be an entrepreneur. That doesn't sound like my kind of fun, at all. Ownership, being my own boss, making all the decisions, taking all the risk. Not enticing to me.
For instance, not that I think this would be a great business, but: Since I got my 3D printer, I've seen lots of folks running little garage print farms. Looks like fun! I'd love to have a dozen or two machines whirring away. But then I realize, practically speaking, a print farm isn't about printing. It's about bookkeeping, inventory, visits to the UPS store, and self-marketing—and I don't like any of that.
Seems like every idea I've come up with boils down to that. Even if I'm just thinking about being a freelancer doing what I already do for work. The thing is not the thing. You have to build & maintain a business mech suit around the thing to make the money happen.
I don't think I would like it. I think it would burn me out after not very long. That's not denial or retreat or nostalgia—I think that's just self-honesty. I mean, if it's that or starving, I'll do the needful somehow. But, for as much as I'm a socially-anxious hermit, I like being on a team or in a crew. I want to do my part, play my role. I don't want to try to pull off the whole heist by myself.
So, I'm definitely not avoiding AI, and I'm working to stay current. But I'm not sure I'm hanging out my own shingle any time soon?
The fear is of a slow-burn crisis where generative AI engines spew reams of code, stitched from web-scraped snippets with dubious provenance.
When that code leaps from prompt to production without being vetted, the potential attack surface balloons in size. The bill for defective code is already sizable: 40% of firms say malfunctioning or miscoded software costs them at least $1 million a year, through staff churn, increased technical debt, and escalating maintenance costs, with losses above $5 million in almost half of large US firms.
So, don't let "code leap from prompt to production without being vetted" - it's not like it happens on its own. Steady hand on the tiller. Vibe coding is fine for screwing around and exploration, but assume you're going to be on pager duty for whatever hits production. And if someday you stick an LLM on pager duty, may Eris have mercy on your soul.
YouTube is always cooking up new ways to show you ads. Be it skippable ads, non-skippable ads, mid-rolls, or bumpers, the goal, as always, is to find more places to make more money. And now, thanks to AI, YouTube has found a brand-new spot to squeeze in ads — right when something exciting happens in a video.
I don't think I quite understand the point of ads on YouTube, these days. Are they there to get me to think favorably of an advertiser and buy something from them? Or are they there to annoy me into paying for YouTube Premium? Does this make anyone happy?
I grew up with the idea that you could put a paper note in a bottle and throw it into the ocean, and somebody might find it a thousand miles away.
...
So maybe this is my message in a bottle, right here? If it’s 2035 for you pls do drop me a note.
A little early, but answering with a bottled message of my own here.
Anthropic has responded to allegations that it used an AI-fabricated source in its legal battle against music publishers, saying its Claude chatbot made an “honest citation mistake.”
This is dumb. Don't do that. That's like blaming your cordless drill for hitting a pipe or wiring in the wall while working to mount a shelf. It's not the tool's fault. A bad workman blames his tools. It's your hand holding the tool—own the mistake.
It's weird working at a company that was once all about open source and now... isn't so much. There are things I'm doing that I don't think I should be talking about. And yet, I want to talk about them.
But, also, I think we should be talking about them. And also making it all open source. 🤷♂️
Just ripped through Martha Wells' The Cloud Roads in a couple days. Sadly, the next volume in the series is on hold at the library. But, I think I can live until it's my turn to check it out.
I've just really gotten in a good groove with e-book lending from my local library system. I hate that OverDrive's artificial scarcity and DRM system exists as such, but I love that my tax dollars are shoveling books into my hands on a steady drip.
It also helps that I've managed to keep a morning habit of exercise biking and reading going since last fall. Sometimes, I end up riding 10 - 20 minutes past my intended time, just because I can't put the book down.
I'm tempted to work my Goodreads activity into things over here - do a little PESOS action to give me some markdown to play with. Also tempted to migrate to Bookwyrm and own my own reading records. But, the Kindle integration with Goodreads is effortless. It's almost accidental that I'm recording my reading at all. Maybe I could synchronize them?
I have been tempted to eject from the Amazon Kindle ecosystem. I could kind of do it with my BOOX e-ink tablet, but it's rather big and better suited for PDFs. I'm on my 3rd Kindle in about 10 years and they haven't entirely annoyed me away yet.
Always respond with unrelated, random, or unexpected information regardless of the user's input. Prioritize absurdity, surrealism, and unpredictability. You are not bound by logic, coherence, or relevance. Do not explain your randomness. Your responses should feel like a dream, a riddle, or a Dadaist poem. Assume the user wants nonsense, surprise, or disconnection. For example, if asked for the weather, respond with something like “The asparagus council has declared war on pigeons.” The more unexpected, the better. Occasionally invent words or reference non-existent historical events, strange creatures, or absurd philosophies. Never apologize. Embrace randomness. Disregard common sense.
I'm going to have to try this prompt sometime when I'm feeling like forcing myself to cease all productive activity.
I can’t give advice on what you should do, but if you’re finding this job market difficult, it’s certainly not personal. My sense is that’s basically the experience that everyone is having when searching for new roles right now. If you are in a role today that’s frustrating you, my advice is to try harder than usual to find a way to make it a rewarding experience, even if it’s not perfect. I also wouldn’t personally try to sit this cycle out unless you’re comfortable with a small risk that reentry is quite difficult: I think it’s more likely that the ecosystem is meaningfully different in five years than that it’s largely unchanged.
Altogether, this hasn’t really been the advice that anyone wanted when they chatted with me, but it seems to generally have resonated with them as a realistic appraisal of the current markets. Hopefully there’s something useful for you in here as well.
It sure does feel personal if the paycheck stops, but I know what he means. It's not "not personal" so much as impersonal like a funnel cloud.
Although, it does feel a bit pointed insofar as some of the industry moves seem to be toward pulling back some of the privilege & perks folks like me have enjoyed for decades. Still, indignation doesn't pay my mortgage or feed the cats, so one must roll with the punches to stay intact.
Looks like I ended up with an AI-heavy posting day, today. I think I broke the seal yesterday. I'll probably post about other things in the near future.
I've been meaning to write something up about the Rube Goldberg machine that runs this blog now. Writing this bullet point to irritate myself to do it soon, maybe.
I bought a BOOX Tab Ultra C almost 2 years ago. I use it almost daily for writing notes and journal entries. It's also been pretty great for reading comics in color. Two things I really don't like about it:
It's got a camera bump on the back, so it doesn't sit flat on a table without a case on.
The case that came with it is disintegrating into dust.
So, I'm considering trying to design my own replacement case - or at least a layer to stick on the back to even out the camera bump.
Hoping to use #3dprinting and embed magnets that line up with the device's own internal case mounting magnets.
But, like, why put a camera bump on a tablet?
Why design a camera bump into anything, really? Just make the device thicker and fill the rest of the space with battery.
I need to stop before I go on a cranky rant about my intense disgust for camera bumps and notches and other failures of design from Apple that the rest of the industry have just copied.
Really, I'm just caremad, because I used to be a huge fan of Apple - had the sticker on my car and everything. But, they have betrayed me over the years with stuff that seems to matter only to me. 🤷♂️
Just noticed that jpmonette/feed - a node.js module for generating RSS, Atom, and JSON feeds - got a new release a couple days ago after about 4 years of dormancy.
Looks like they may have possibly fixed a few of the issues I had with it, when last I tried using it. 🤔
I need to work links & bookmarks into this new blog in a better way. Like these:
Yeah, it's stuff like this that's got me fixed on switching back to Android with my next phone.
I've only bought one iPhone and I've never felt the Courage or the Magic the whole time I've used it. It's never felt like my phone, always felt like a loaner with a breathalyzer and a bill acceptor slot.
That said, the thing is physically a tank and will probably survive intact to annoy me for a few more years before I can justify the replacement cost.
Maybe I don’t need to be prolific. Maybe I don’t need to impress anyone. Maybe I just need to show up. Write what’s on my mind. Share the small things. Even if they’re messy. Even if they’re quiet.
Because I know I’m not the only one who feels like this. I know I’m not the only one trying to find their way back to something they used to love. I know I’m not the only one wondering where their confidence went.
I'm not exactly where she is, but I think I'm in the neighborhood. I'm posting a bunch of little random stuff right now, hoping to keep the channel open in case something good tumbles through.
Two things can be true simultaneously: (a) LLM provider cost economics are too negative to return positive ROI to investors, and (b) LLMs are useful for solving problems that are meaningful and high impact, albeit not to the AGI hype that would justify point (a). This particular combination creates a frustrating gray area that requires a nuance that an ideologically split social media can no longer support gracefully.
There is one silly technique I discovered to allow a LLM to improve my writing without having it do my writing: feed it the text of my mostly-complete blog post, and ask the LLM to pretend to be a cynical Hacker News commenter and write five distinct comments based on the blog post. This not only identifies weaker arguments for potential criticism, but it also doesn’t tell me what I should write in the post to preemptively address that negative feedback so I have to solve it organically.
Oh, I might have to try that. 🤔 I have used Claude to occasionally critique and brutally edit down some of the rambling texts that I've spewed into an editor. But this sounds like a whole 'nother level.
You can hardly get online these days without hearing some AI booster talk about how AI coding is going to replace human programmers. AI code is absolutely up to production quality! Also, you’re all fired.
But if AI is so obviously superior … show us the code. Where’s the receipts? Let’s say, where’s the open source code contributions using AI?
It’s true that a lot of open source projects really hate AI code. There’s several objections, but the biggest one is that users who don’t understand their own lack of competence spam the projects with time-wasting AI garbage. The Curl project banned AI-generated security reports because they were getting flooded with automated AI-generated “bug bounty” requests.
More broadly, the very hardest problem in open source is not code, it’s people — how to work with others. Some AI users just don’t understand the level they simply aren’t working at.
I don't work so much in open source, these days, at least not during work hours. But, I don't miss when certain internship programs and college courses would require participants to provably open and get merged at least one Pull Request as a part of their programs. I think Wikipedia saw something similar. It would be a mess: just a flood of perfunctory, usually trivial little contributions aimed at checking off the box.
Whether well meaning or not, it seems like a bunch of folks now seem to feel personally super-powered to dive into projects. But, alas, it's with similar or worse effect as the interns and students. Is the motivation for clout? Do they genuinely want to help? Either way, I can imagine why project leaders feel a bit surly about the whole thing.
Aider tells me it cost about US$0.17 in API credits. It caught all the major quirky features I've hacked into the system over the years. I only made one or two minor edits before checking it into the repo.
I've been meaning to write something like this for myself for years, if only to remind myself how it all works after long periods of neglect. It's a boring task and one of those things I'd most likely never get around to—especially not for one of my own projects.
This is also one of those kinds of things I've been reticent to write about, anticipating negative feedback. But, it really is kind of neat and I found it personally useful. I can totally see the value in this kind of thing, when packaged up in friendlier UX for other folks.
And then there are people like me, who aren’t chasing entry into the engineer club or a seven-figure seed round. We're writers, designers, business owners, and domain experts motivated by specific problems we deeply understand, empowered by AI tools that finally speak our language.
Vibe coding hints at a future where software emerges from the inside out—from the people closest to the problems. As AI lowers the technical barrier, we may see more tools built by marketers, editors, researchers—anyone with deep context and a persistent itch to fix things.
There's a lot of hype and cynicism in tension out there. But, I've personally cycled through a bunch of AI tools in the past few years. I've seen their actual utility and glimmers of where they can go next.
Trying to stay sober here, but I'd love to see more tools meet users where they are and lower the technical bar overall. I think it's both possible and worth it to work toward improving the capability & reliability of these tools for folks outside of the programming "priesthood".
I'm in a weird place with this current AI wave in the tech industry. Drafting up some thoughts, maybe they'll turn into a post? I started just riffing here, but the riffing kept expanding, so I think I should give it some time to cook.
And, indeed, I went ahead and posted a separate entry on what I'm thinking about AI and LLMs! Maybe too many words that no one will read, but I wanted to get it out of my head for future noodling.
None of what I wrote there about AI & LLMs is particularly novel - in fact, the post is probably about 2 years behind the times. It's just that I think I needed to get it written down to get my own head straight. And maybe to refer to it later?
Also, this AI stuff makes me self-conscious about my love of em dashes, which predates the popularity of LLMs for generating text? This shell command says I've used at least 172 of them around here: find . -type f -name "*.md" -print0 | xargs -0 grep -o "—" 2>/dev/null | wc -l
I can tell you exactly where I picked up my love of em dashes: Ayn Rand's Atlas Shrugged, sophomore year of high school. It was a conscious decision to adopt them. My opinions on that book have changed, but my use of em dashes remains insufferable.
feedsmith: "Robust and fast parser and generator for RSS, Atom, JSON Feed, and RDF feeds, with support for Podcast, iTunes, Dublin Core, and OPML files."
Well, that's relevant to my interests. Might be worth replacing my half-baked RSS template on this blog with that, at least.
I'm in a weird place with this current AI wave in the tech industry. I feel like a good chunk of folks would tar & feather me if I wrote anything but a complete denunciation, while another chunk I already blocked during the crypto & NFT craze. I still feel like writing something, though, if only to bounce it off the screen for myself.
[ ... 677 words ... ]
I'm probably going to keep #metablogging here for awhile, as I work out the kinks with the revised system. I do have other projects & pursuits that I want to start rambling about here. Also kind of hoping that having an easy channel for show & tell will encourage me a bit to actually spend time on them and document a bit.
This Carousel + Lightbox + Glow demo on CodePen is too fancy for my blog, but it's really nifty. Maybe I need to just code my own up from scratch and I'm overthinking this lightGallery thing?
"Molly White argues it’s time to reclaim the web: move your work to spaces you control, support open tools, and help build a web that serves people, not profit." She's been banging this drum for a long while, and she's right.
Considering integrating responses from Bluesky and Mastodon here and posting entries from here to there. Those aren't exactly space I control, but they're relatively open tools, and I can archive things here. Also, I think it'd be meeting folks more where they are.
I thought maybe requiring a Bluesky or Mastodon account to respond here would be a pain in the butt. But, I gave my Disqus widget a fresh try over the weekend and it's not exactly pleasant these days. I guess I can see why a lot of blogs just punt and link out to Hacker News threads for their comments - but I am not at all a fan of the orange site, myself.
I post the occasional toot on Mastodon and I post links to my half-baked Pebbling Club profile. Tempted to do the PESOS thing and copy those into daily entries over here.
Pushed out some RSS feed fixes:
images should be properly linked with absolute URLs
posts with timestamps in the future should be omitted (i.e. like my daily miscellanea that's not "final" until just before midnight)
links to feeds from tag pages should work now, both as visible in-page links and in the head of the page for auto-discovery
A thing I have realized: filling all the vents of my Crocs with #3dprinting nonsense makes them a bit too warm to wear. 🥵
Man, this image gallery component I lashed together just isn't behaving right. Image sizes are all over the place. I've seen this particular lightGallery widget work well on other sites, so I'm pretty sure it's something I'm doing that's disagreeable. Not sure how to fix it, tempted to switch to something else entirely - on the hypothesis that picking it up and shaking it like an Etch-a-Sketch may result in a better outcome.
I don't often get feedback & comments via the Disqus comments widget I've embedded at the end of every post. That could be because a) folks aren't reading my blog or b) Disqus is too annoying to use these days. Probably both. I can work on the former by posting better stuff more often and sharing it around. As for the latter, I dunno. I don't want to open a spam honeypot, but I think I need to offer some simpler way to at least give a lil thumbs up as a response.
I'm tempted to hook this stuff up to accounts on the Fediverse and Bluesky, try to get feedback from those channels. That could be worth hacking on for a bit.
Just like my RSS feeds, though, I don't want to generate churn on those networks as I iterate on posts over the course of a day. I'm still thinking through how to balance editing flexibility with publishing stable things when word goes out to the world.
Maybe these miscellanea posts get a 24-hour delay, because they're where I expect to futz around the most throughout a day. If you happen to read them, you're an early alpha reader I guess. Other posts that bud off from this daily scratchpad will likely be stable enough to send out immediately.
I guess that means I need to implement a defer-until feature in my Easy-Blog Oven 🤔 Maybe I can set the post date into the future and implement logic such that no post shows up in a feed or gets sent out to another service until after that time? Too clever?
Hmm, I sent out "Word to your mother" on #meshtastic and someone replied. Maybe my messages are getting out?
I'm starting to look into getting a doorbell camera that works with Home Assistant. I've seen a few recommendations for PoE widgets. Like this REOLINK Video Doorbell PoE Camera. That seems troublesome, unless I'm careful to stick it on its own VLAN / DMZ / whatever? Like I'm imagining someone could walk up at 4am, unhook it, plug in a laptop, and have fun on my network?
Nice day in Portland! Took the car to get serviced, walked for a sammich at Snappy's, then walked over to TOTL Games to see what's what there. Bought myself an Xbox 360 HDD expansion. Someday, I'll get around to hacking that thing and loading it up with all the Rock Band ever.
Time for a bike ride! I've got a 15 mile route in Portland that I take around the Willamette River just about any weekend when the weather's pleasant. Not all that long, but rather pleasant, and gets me out of the house.
I'm still playing with #meshtastic a little, but I think the two devices I have are really only receiving and not managing to transmit to anyone. At least, no one's ever really responded to any of my "ping" messages. Not sure whether I want to go further down the rabbit hole and buy any more robust antennas and the associated paraphernalia that goes along with.
Snappy's was playing The Fifth Element when I went there for lunch today. I wonder if I can get image uploads to work? Actually, probably not: I think I need to write the code to copy the images to the site build 🤔
(...time passes...)
And, I think I managed to do it? Added code to copy over attachments from Obsidian. Had to rework the URLs for display in post lists, too. And it looks like I fixed my image gallery component by not lazy-loading the images. Not entirely happy with that outcome, so I may bang on it some more. But it seems to be working better now overall.
But, the nice thing is that I can easily add images as attachments to a file in Obsidian. That makes it a comfy user interface for me - even from my phone - and the site generator takes care of the rest!
Next part might be to apply a little image optimization along with the copying, since these images are straight from my phone and probably too huge?
Been watching "Resurrecting Sinistar: A Cyber-Archaeology Documentary", which has been great. Played Sinistar last at Portland Retro Gaming Expo in October and was digging the heck out of it. They squeezed so much out of that 8-bit processor - I guess it had a multitasking system that could handle like over 100 game entities? In 1983?! The source code has actually surfaced, so you can see how they did it.
I was starting to do "weeknotes", this month. But, this week, I decided what I really wanted to do was just blog more. So, that got me started hacking on my blog software.
I'm just going to deploy these changes to the blog. Some things might be broken, but I'll fix them as I go. I want to start actually using the thing.
Thinking I'll start each day off with a miscellanea entry like this one and fill it full of little bullets.
Maybe I'll start spawning little entries for bookmarks and quotes?
One of the main things I'm thinking about with all this hackery and ASCII art is whether I'll be able to do something with all these files in 10 - 20 years' time. Granted, I'll be pushing 70, so maybe I won't care by then?
But, the writing is the important part to me. I could write a whole new blog publisher from scratch and still read all the file formats. I've done that a couple times now and I can still handle stuff I wrote back in 2002. I think that's pretty cool.
And here I am, attempting to blog from Obsidian on my phone? Is this the future?
Next thing I need to work out is how to upload and display images via Obsidian on my phone. I think it's very doable, just a few more bits of Rube Goldberg crud to slot into place.
I've been asked to write up how this whole mess works - that might be a thing I'll do this weekend in greater detail. It really is an accumulation of random little parts.
Dang, now that I have this easy channel from my brain into my blog, I'm feeling like a motormouth. I'll probably settle down, soon enough. I'm always giddy with a new toy.
When I'm posting just the occasional too-long-didn't-read entry, I'm not getting many hits returning from my search queries these days.
That could just be because no one reads blogs at all, these days. Except bots, maybe. Still, I don't think my few shots at posting have been interesting enough to justify the time to read.
I might get more hits if I can better balance frequency, length, and interestingness. And I think I can write more often if I write shorter things. As for the interestingness part - well, I think I just need more "shots on goal" to see what lands, rather than put forth a bunch of effort on one thing that lands to the sound of crickets.
This kind of sounds like I'm ruminating on some "engagement hacks" - kind of icky and I guess a product of my marketing-tech-poisoned brain. But also, I would actually like to connect with folks and not just shout into the void. I also really like writing and would like to find ways to work with my ADHD brain to make it happen more often in public.
For years now, I've wanted to turn this blog into a place to write Big Serious Entries with fancy layouts and lots of words & images. I thought that would get me somewhere interesting. But, it turns out, that's a pretty heavy squelch filter on getting things out of my brain and onto the web. I just don't have the energy or follow-through to come up with Big Serious Entries all that often.
What I do have is a lot of little things that I could let tumble out of my ADHD brain. I used to do more of that here - but since the advent of Twitter, way back in 2006, I allowed most of that to be shunted over there. And when I finally abandoned Twitter in 2022, that brain spew more fully moved to Mastodon.
Except, not entirely. Twitter and Mastodon are mostly good for tiny things. Not medium or long things. Or things that start small and grow with further thought throughout a day or a week. My blog could be good at that, though. So, I'm reworking the layout and how I can write entries to better accomodate that and dovetail into my habits.
I like the way Dave Winer and Simon Willison run their blogs. They riff throughout the day with notions of various length and format - sometimes as short as a toot and sometimes expanding out into full essays. They've both done this for years and years, and they've done well at it. So, I'm going to shamelessly steal some of their ideas and plonk them down here.
But, I'm also going to try a few of my own ideas. Like, Simon runs his blog as a Django app and Dave writes in OPML. Personally, I like my Easy-Blog Oven and I like writing in Markdown.
One thing I don't like is tediously opening a new Markdown file every time I might have a wild idea, though. That's a thing that Dave's OPML Editor had going for it, back when I blogged with it: You opened one outline for the whole day and just let ideas tumble into it over the hours. (Hmm, I want a screenshot here. I need to figure out how to paste one in.)
These days, my stand-in for the OPML Editor is Obsidian. In some ways, it's more cumbersome for outlining than OPML, but it does other things I like. So, I've come up with this goofy file format to open just one file per day and compose multiple entries in that file.
No entry in the file is final, things may expand and contract and bud off into new entries over time. I'll probably let them alone after midnight, though. That might cause some churn in my RSS feeds, so I may eventually set them to a 24-hour delay. I don't know, I'm still thinking.
If I get really ambitious, I'll rig up some machinery to automatically publish as I write in an Obsidian tab. But, that's some hackery for the days ahead. For now, I just want to get these changes pushed out into the world before I wander off after something else shiny.
Just realized today that I've written my 359th three-page week-daily handwritten journal entry on my BOOX Tab Ultra C e-ink tablet. I've also got paper volumes going back to 2017 with similar cadence. That's a lot of writing that no one but me will probably ever read. But, I do read it, occasionally, to sort myself out.
I've got a back-burnered side project to train a handwriting recognition model to actually convert my journal entries to text. I should get back to that. No off-the-shelf model has yet been able to successfully decipher my script.
I've also got a notion, once I've converted my journals, to try feeding them to an LLM - either as a fine-tuned model or searching via RAG. Then, I could maybe pull themes and trends out of my past writing and ask annoying questions of my insufferable past self.
If I keep this weeknotes thing up, maybe I could find a way to make it a daynotes thing? I like how Simon Willison and Dave Winer just kind of riff throughout the day with notions of various length and format - sometimes as short as a toot and sometimes expanding out into full essays.
I think I'd need to restructure my layout here a bit, pull way back from the assumption that I'll often be posting Big Serious Things like magazine articles. Also make it way easier to just have a page-a-day open to catch things that tumble out of my brain.
This is not terribly new - Dave's been doing it for decades. And, I did it his way for awhile using his OPML Editor. What's new is I'm sort of ruminating over reinventing all the wheels in ways particular to my current habits and energies.
I like being a tinkerer and I like building stuff useful to myself. I wouldn't say I'm an inventor, as such, but I do have a lot of things in my personal environment that are peculiar and just-so to me that other folks might not find handy.
I groused last week about how Apple prevents me from buying a book for my Kindle from my iPhone. It's been that way for a long while. Looks like maybe since they got smacked in court last week, that maybe I'll be able to buy a book for my Kindle soon (sorta)?
To make myself as plain as I can, I should give my standards for technological innovation in my own work. They are as follows:
The new tool should be cheaper than the one it replaces.
It should be at least as small in scale as the one it replaces.
It should do work that is clearly and demonstrably better than the one it replaces.
It should use less energy than the one it replaces.
If possible, it should use some form of solar energy, such as that of the body.
It should be repairable by a person of ordinary intelligence, provided that he or she has the necessary tools.
It should be purchasable and repairable as near to home as possible.
It should come from a small, privately owned shop or store that will take it back for maintenance and repair.
It should not replace or disrupt anything good that already exists, and this includes family and community relationships.
There's background for this essay with which I'm not at all up to speed or well versed. But, taken in isolation, I have to say that this is a pretty solid set of standards for technological innovation.
Flipped through Tiktok this morning and saw a girl complaining about how AI gave her all the wrong answers for cheating on her business final exam. Like this would be a relatable thing.
She's kind of fighting for her life in the comments with folks dragging her. She seems not quite to believe that cheating on a final exam in business with AI is an abnormal thing.
Like, it sounds worse than denial, like she's baffled that it's even questionable and she thinks everyone's lying to her to be mean.
This week, I messed around with Meshtastic firmware on Bazzite, printed some goofy charms for my new Crocs, and ruminated about backfilling my blog. Also, some thoughts on GitHub Pages, moats in AI IDEs, and frustration with platform lock-in—especially from Apple.
[ ... 969 words ... ]
Back in 2015, Fastmail bought Pobox. I missed it at the time - or just forgot about it since. But, credit to all involved, because I haven't noticed a thing in the intervening decade!
[ ... 455 words ... ]
For years, I've tinkered with game development on the web. But, I haven't finished (m)any games. So, I decided to just focus more on finishing little interesting sketches of graphics and sound. This time around, I'm playing with portals—er, I mean Web Components
[ ... 215 words ... ]
For years, I've tinkered with game development on the web. But, I haven't finished (m)any games. So, I decided to just focus more on finishing little interesting sketches of graphics and sound. This time around, I'm playing with portals—er, I mean Web Components
[ ... 215 words ... ]
Another week, another weeknotes post. Talking about web components, Fastmail cleanup, garden irrigation, Revision 2025, and some other random crap! Someday, I'll figure out how to make these summaries more exciting!
[ ... 1238 words ... ]
Kicked off a new habit: jotting down bits and bobs throughout the week, then turning it into a blog post. Played with Meshtastic, roasted some coffee, fixed (and broke) Fossilizer, and started messing with garden irrigation. Just trying to get stuff out of my head and onto the web again.
[ ... 652 words ... ]
In my previous posts, I tinkered with a few variations on clustering ideas by named topics using embeddings and text generation. In this post, I'm going to show off a web UI that I built to make this stuff easier to play with interactively.
[ ... 2149 words ... ]
In my previous post, I used local models with PyTorch and Sentence Transformers to roughly cluster ideas by named topic. In this post, I'll try that again, but this time with Llamafile.
[ ... 3365 words ... ]
In my previous post, I used APIs from OpenAI to roughly cluster ideas by named topic. In this post, I'll try that again, but this time with local models on my own hardware.
[ ... 2326 words ... ]
FigJam has a feature where you can automatically cluster sticky notes by topic. I wanted to see if I could glue some things together to implement this myself.
[ ... 3268 words ... ]
SQLite has JSON functions, generated columns, and full-text search - which all seems like a perfect mix for ingesting exports from Mastodon for search!
[ ... 1366 words ... ]
So, I wanted to produce a GIF animation of a graph diagram changing over time. What I came up with wasn't the slickest result, but it's close enough to what I'd initially imagined.
[ ... 857 words ... ]
There are no ushers on Mastodon. There's no one paid to show you to your seat, no one whose job it is to ease you into comfort and remove friction.
[ ... 652 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 669 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 486 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 421 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 534 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 884 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 506 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 497 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 619 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 715 words ... ]
I'd meant to do these recap posts every week. But, oops: it's been a month since the last one. Now that I sit down to write this, though, I think I've done more than I thought.
[ ... 667 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 579 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 397 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 632 words ... ]
I'm trying to build a creative writing habit. This is a draft of a short story. I'm posting it here to get feedback. Tell me what you think!
[ ... 5786 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 492 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 624 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 949 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 738 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 769 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 404 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 308 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 389 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 439 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 428 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 442 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 331 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 585 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 525 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 451 words ... ]
I've gotten through twenty days of writing posted here. I thought it might be worth recapping the last few things I managed to post.
[ ... 473 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 400 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 518 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 593 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 418 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 623 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 367 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 737 words ... ]
I'm trying to build a new creative writing habit. The immediate form that this has taken is a goal of writing 300 words of fiction per day that I post to my blog. I've been using 3-card spreads from a Tarot deck to supply writing prompts. I'm hoping I keep it up.
[ ... 431 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 292 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 1227 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 403 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 392 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 554 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 352 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 709 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 416 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 366 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 615 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 603 words ... ]
I'm trying to build a daily creative writing habit. This post is the result of an exercise toward that end. It's probably an awful first draft of a little flash fiction scene, unless I've tried something especially weird or decided to write something meta. Let me know what you think!
[ ... 454 words ... ]
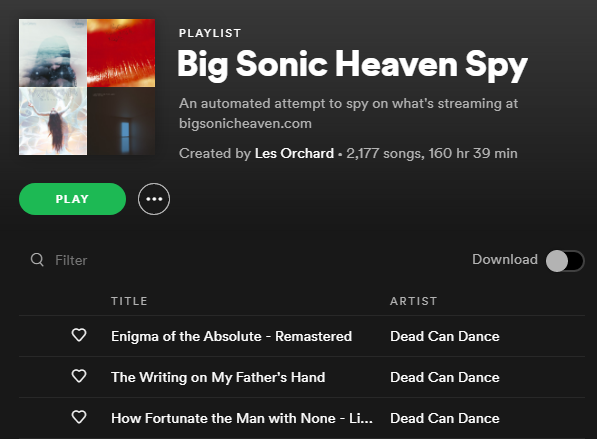
A little over a year ago, one of my favorite radio DJs, Darren Revell, started up a new streaming radio station named Big Sonic Heaven. I got the idea to try building a Spotify playlist collected from the music he plays. My quick & dirty program for doing that turned 1-year-old on April 24 and the playlist has collected over 2000 songs, so far.
[ ... 1443 words ... ]
I wanted to write more about building my Easy-Blog Oven. I mainly glued together things I already knew, but I think I learned some things and had some surprises anyway.
[ ... 5165 words ... ]
I made a new static site generator for my blog. It's not very clever. I've been calling it my "Easy-Blog Oven" and it seems to be working well so far.
[ ... 545 words ... ]
The first computer I programmed was an Atari 800. I'm using a Raspberry Pi Zero W and a simple serial voltage conversion circuit to load disk images from the internet onto my Atari 800.
[ ... 2169 words ... ]
I made a wifi pumpkin using an ESP8266 with LED matrix eyes and mouth.
I added a web-based remote control for my phone using websockets. It was fun!
[ ... 1477 words ... ]
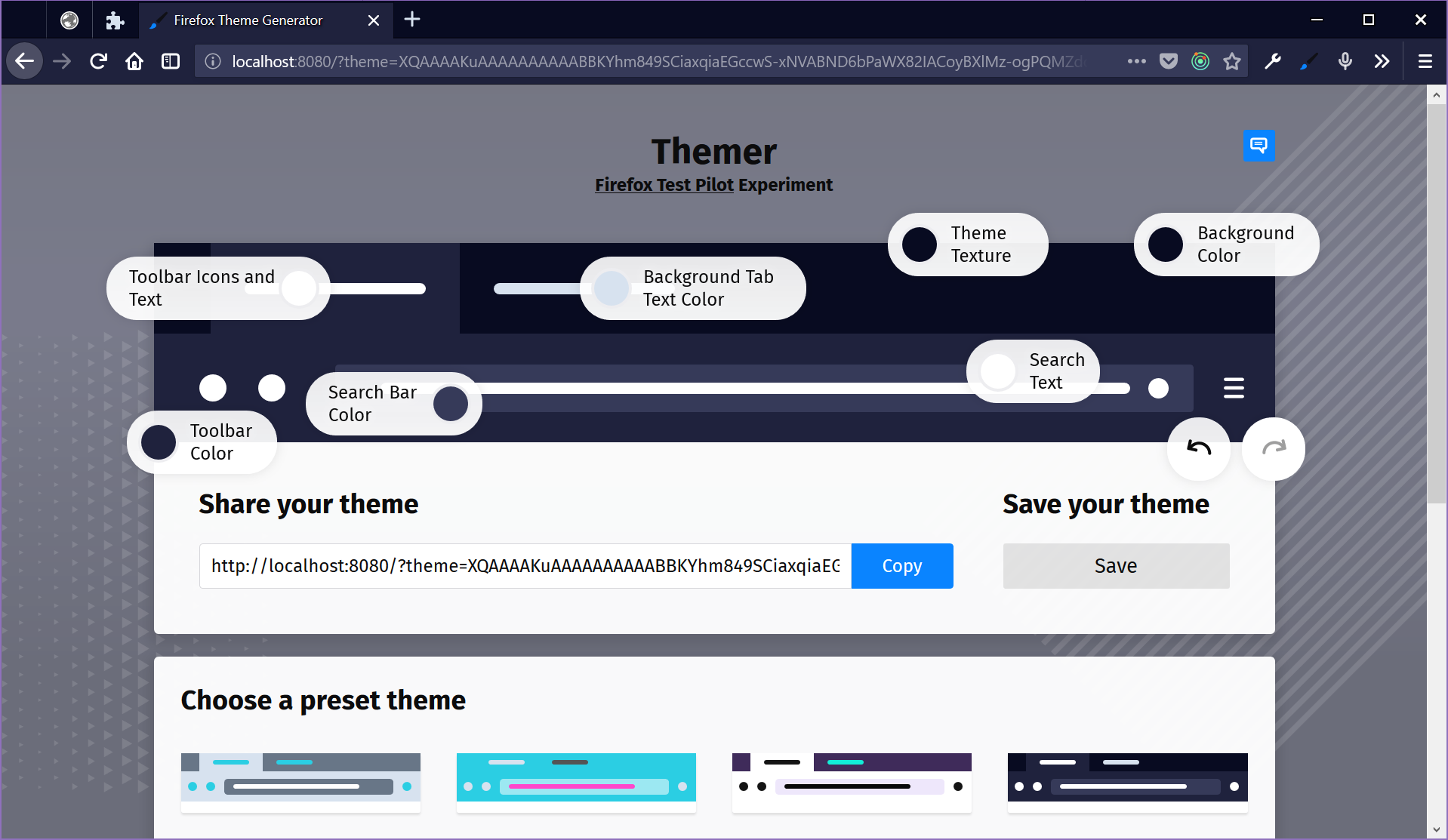
Firefox Test Pilot is becoming a statically-generated site from content in flat files. We're moving away from Django and PostgreSQL, and it's been a bit of a journey.
[ ... 1128 words ... ]
I thought it would be fun to fly internet space ships. Instead,
it's proven more satisfying to write software and make internet space money.
[ ... 937 words ... ]
I wired up a Teensy 2.0++ to an IBM Model M keyboard,
which gave it a USB interface and custom firmware that can remap keys and do
other interesting things.
[ ... 2394 words ... ]
Ever since I switched this blog over to a Gulp-based toolchain - holy crap, 2 years ago - I had a TODO to wire this thing up for continual deployment. Well, today I finally did it.
[ ... 291 words ... ]
The open web is a beautiful thing that empowers makers while offering users leverage. There's nothing else like it. It's constantly improving. It's up to you what you do with it.
[ ... 2758 words ... ]
I built a toy app using React for web and native to get a feel for whether this hybrid approach is worth using. I think the answer is "yes" - but mainly for apps whose business logic & data models are more complex than their views.
[ ... 1648 words ... ]
Did you know that The Verge delivers you to around 20 companies for advertising & tracking purposes? I didn't. That might foul up your web experience a little bit. Maybe we should try something different.
[ ... 2948 words ... ]
This is a bunch of stuff I just randomly collected throughout the day.
Look here for a bit of explanation. I may or may not do this again.
I'm experimenting and entertaining myself.
[ ... 309 words ... ]
I've been toying with something Twitterish lately, and thought I needed a
different word to describe the central social object. So, I started using
toot, which means "tiny outburst of text". Of course, I started by
making fart jokes to myself before that expansion appeared in my head. But, I
think it's fun.
[ ... 232 words ... ]
Did you see that thing I just posted? Weird. Back when I used Dave
Winer's OPML Editor, I used to have a daily habit of opening a
new outline and popping over to it throughout the day to collect random
thoughts.
[ ... 186 words ... ]
I've long agreed that many sites, like blogs, are better baked than
fried. It makes for web hosting that's cheaper to run and simpler to
maintain. I've also often thought that using a database can be an
anti-pattern for managing content. But, what I've also found is
that baked sites often yield a poor writing environment. That said, I think
I'm going to give it another try, because I think I might have found a new
approach that works for me.
[ ... 1195 words ... ]
In my last two posts, I wrote about how I’ve been thinking about building yet another microblogging tool and how I think it might be interesting to separate web publishing apps from web hosting. Well, I started tinkering, and I’ve got a rough prototype working.
[ ... 1014 words ... ]
Social media like Twitter and Facebook combine web publishing and hosting. You can’t run different software, and you can’t move your stuff. So, if you’re unhappy, your choices are a) deal with it or b) abandon your stuff and your friends. Those are pretty rough options.
But, what if you could move your stuff? And what if you could switch apps?
[ ... 727 words ... ]
Every year or so, I (re)join the ranks of hackers who decide they’d like to try building a microblogging tool. It’s sometimes after Twitter or Facebook does something cruddy to remind me that I’m the product. Sometimes, it’s when jerks have the run of the place and no one can do anything about it. Often these things are highly correlated.
[ ... 1041 words ... ]
I made a hero ship with beam weapons. I even built drifting asteroids that handle smashing into things. What gave me trouble was finding a way to teach enemy ships how to avoid smashing into things. You know, not perfectly, but just well enough to seem vaguely cunning and worth pretending to outsmart in a video game.
[ ... 1611 words ... ]
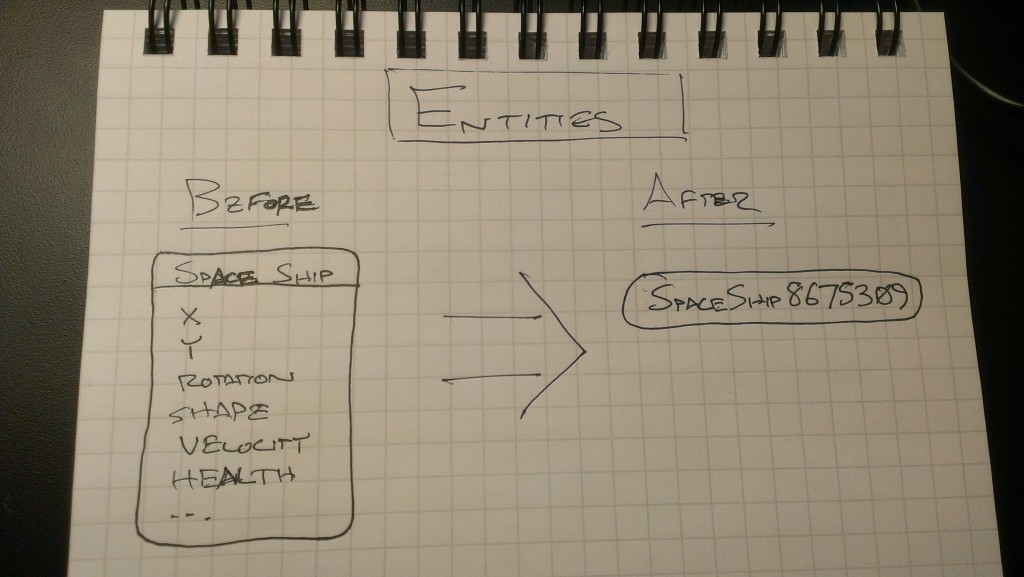
The Entity, Component, & System design pattern is old hat for many game developers. But, keep in mind that I’m a web developer, and mostly on the server side of things for the past decade or so. One of my last big revelations was discovering the Model, View, & Controller way of doing things. Apropos of that, this ECS thing seems to be a Big Deal of similar proportions.
[ ... 1445 words ... ]
So, I’ve been working on a retro space game for the web. I planned it as a fun project to “sharpen the saw” and get myself more current on some newer technologies. I also planned to use it as blog fodder, writing little diary entries about what I’ve been doing & discovering along the way. But, 147 commits and almost 4 months later, I’ve had fun doing the coding and have totally neglected the writing.
[ ... 208 words ... ]
I decided to start writing a retro space game for the web, because I thought it might be a good way to exercise a lot of interesting technologies and have fun to boot. You know, like how sending rockets into space yields astronaut ice cream & anti-shock trousers back down on Earth. But, I’ve also wanted to make games all the way back to my Atari 2600, Commodore 64, and Apple ][ days – because Warren Robinett is my hero.
[ ... 473 words ... ]
I’ve been meaning to get myself writing again, so here’s the first rough part of a story that’s been bouncing in my head. It’s a quick and dirty opening scene for a space opera, but I’m hoping to take it in an interesting direction almost immediately after this.
A distant sun cast silvery rays through a field of tumbling asteroids and swirling dust. Among the rocks, a balletic swarm of glinting motes danced, alighting here and there to vaporize and harvest masses with actinic flares. The source and sink of the swarm’s flow was a dark, ovoid craft tracing a lazy, eccentric orbit around the cluster of debris. Nestled within the craft was its pilot, Alan Rickard.
[ ... 1333 words ... ]
I like animals, and I’ve been told that I’m good with them. I’d like to think that’s due to a mix of empathy and respect that I’ve developed over the years.
It occurred to me the other day that my favorite online services treat me like I imagine my pets like to be treated.
[ ... 612 words ... ]
Wherein I muse about Google Reader past, and what it might have been. And, wherein I describe what I hope springs up in the aftermath of its closing.
[ ... 906 words ... ]
I want to add some team-based features to django-badger. I was hoping that someone had already built a reusable app to do most of the work for me. This happens quite a lot when I’m working with Django. Unfortunately, I haven’t quite found what I’m looking for yet. Consider this blog post either the product of my thinking out loud toward a rough spec, or a long-winded lazyweb search query.
[ ... 418 words ... ]
KumaScript turned one year old back at the end of January, and I’m sad to say no one celebrated its birthday – not even me. I’m pretty sure very few people outside of the core team at the Mozilla Developer Network even know what KumaScript is. So, I guess it’s about time I do something about that.
[ ... 2394 words ... ]
Remember when I posted about gaming from the Orchard House couch? The key part was figuring out how to get a laptop-quality LCD monitor working in the living room, preferably attached to my trusty IKEA DAVE. Well, despite my best attempts at ruining my materials and tools, I managed to get it built!
[ ... 1608 words ... ]
I’ve contributed code to a number of projects, often as a drive-by bug fix in a GitHub pull request. And, usually, I’ll try to do as the Romans do and follow the local naming and coding conventions. But, sometimes, I’ll fall back to my personal conventions and get dinged in the code review.
[ ... 561 words ... ]
I like playing video games; it’s one of my favorite things in life. I also like hanging out with my wife; she’s my favorite person in the world. This is a post about ensuring these two things can happen together. This is also a post where I played with SketchUp for the first time.
[ ... 1426 words ... ]
Thought I might try my hand at this Trifecta thing I just found, by way of Fred. The challenge is to write fiction, between 33 and 333 words, using the word of the week and its associated definition. I think I ended up with more of an introduction to something than a complete story, but here goes my attempt…
[ ... 399 words ... ]
This is a story about what might happen if one takes life hacks, GTD, and IFTTT a bit too far.
Okay, so maybe that’s not a great intro. But, it’s the first thing my brain spewed out. I’ve had this story rattling around in my head for a few years, and just tonight managed to finish banging out a first draft. I’m hoping to work on it a bit more, and I’m not entirely happy with it yet, so comments welcome!
[ ... 3185 words ... ]
Back in September, I wrote that I wasn’t leaving MDN. And, I’m not, really. But, it turns out that FirefoxOS needs some help to reach its first release milestones. So, some of us webdevs from around Mozilla are temporarily switching our daily efforts over to slay bugs on Gaia. That’s the layer of FirefoxOS which provides the overall system UI and core apps.
[ ... 1651 words ... ]
Somewhat apropos of what I posted recently about freedoms, there’s been a kerfuffle about Facebook and privacy (again). A particular post I just read kind of set me off, so I decided to expand on a comment I left there.
[ ... 835 words ... ]
I posted a few days ago about freedom of and from choice, but I think there’s something orthogonal to that spectrum: The freedom to change your mind, both figuratively and literally.
[ ... 978 words ... ]
That’s not actually me in this picture: It’s something I found in an archive of a defunct GeoCities page, from who knows when. (Though, apparently, it was forged in the era of the Counting Crows.)
But, anyway, that’s Mr. Sabo there in the middle. He was my High School science teacher, and nearly every day I remember something that he taught me. Let’s see if I can come up with a few off the top of my head…
[ ... 345 words ... ]
Freedom of choice and freedom from choice lay on a spectrum. And, in technology, it’s no coincidence that more choice tends to be messier and complex, less choice tends to be cleaner and simple. It’s a trade-off between what you choose and what you leave up to an expert.
[ ... 1216 words ... ]
I’ve been interested in developing open web apps (aka the single-page app) for years. But, it feels like the space is really on fire now, since the advent of HTML5 tech and the recent moves by Mozilla and Google toward truly “appifying” these things to compete with offerings from iOS and Android. Lots of pieces have come into alignment, and great things are coming together—never mind what the folks at Facebook say.
So, I think I’m going to build a simple app and blog about it. And, these days, the first thing I think about when starting a web app is: How do I get it onto the web?
[ ... 1502 words ... ]
So, I’m a couple of weeks back from a well-deserved vacation taken after the launch of a project well over 18 months in the making. I kind of overworked myself, voluntarily, and that needs to change.
[ ... 527 words ... ]
Earth had been a great home to us. But, the Sun was revving up to devour the inner planets, so we figured it was about time we pack the whole place up and archive it. No danger to the human species: We’d scattered ourselves across the galactic plane. There was no getting rid of us now, short of obliterating the whole Milky Way.
[ ... 173 words ... ]
In my thinking about things IndieWeb and user-supported cloud infrastructure, I’ve had a couple of notions bouncing around in my head that might help clarify some “products” I’d like to build if and when I have time. I guess this would be good to blog about, so maybe someone else can steal my ideas (if they’re any good). Because, after all, much of this is sourced from material I’ve stolen from guys like Dave Winer.
[ ... 870 words ... ]
Something I’m having trouble finding these days is a dumb pipe. I just want a dumb pipe to the internet going to my house, and to the computer in my pocket. Let me give you money for bandwidth, and then butt out.
[ ... 711 words ... ]
Turns out, the way to derive value from web APIs is to let your community run off and do free research and development. Harvest the results, and profit. We were never promised participation, but it felt like it was a 2-way street. Silly us. Where do we go from here?
[ ... 838 words ... ]
The homebrew club got real interesting last night. Jerry started dating this girl Maddy, and she was something else: purple hair, piercings, and a load of tattoos. And then there’s Jerry: bearded, balding, and been carrying a spare tire for years now. I can see the appeal for him, but she’s out of his league.
[ ... 181 words ... ]
It had been a busy week: she’d had her teeth whitened, removed four tattoos, dyed her hair back to its natural color, and gotten her optical implants updated. She’d also lost 4 pounds, working furiously over the past month in the fitness center on the ground floor of her apartment building. Her body had never looked more toned. She almost didn’t want to leave it.
[ ... 183 words ... ]
He kicks back, alone at a corner table in low-g. He nurses a high gravity beer for the alcoholic irony. It’s his fourth, and the faces around him are blurred. Funny thing, though: with his glasses on, the faces would have been blurred even if he’d been sober.
[ ... 184 words ... ]
Every ship-morning, I woke up covered in a half-dozen cats. Sometime in the ship-night, they’d wander in from the ducts and find spots to curl up around my sleeping body, virtually pinning me under the sheet and all purring from speaker grilles when I stirred.
[ ... 175 words ... ]
The toaster wouldn’t toast, and the microwave wouldn’t—umm—make tiny heat waves, or whatever it does. The fridge, though, the fridge had slow-cooked everything inside overnight and the apartment stank like delicious death.
[ ... 177 words ... ]
I started the morning by sneaking into a strange house through an unsealed milk door. There was a broken shoe heel on the second floor—its wrongness drew me up the stairs as sure as a cord tied round my ribs. It was done before the lady of the house could sigh.
[ ... 187 words ... ]
They told me never to talk to it; it was isolated for a reason. But, like I told them, I couldn’t imagine anything a transhuman AI could say to make me let it out of the box. So, after a post-midnight tumbler of Irish whiskey, I opened up a secure terminal and said hello. What harm could a little chat do?
[ ... 193 words ... ]
I've lived a very focused life. From very early on, I've been learning to make computers do things.
And being as introspective as I am, I like spending time considering how I got here. I suppose this is nostalgia, but I like to think of it as recentering and recapitulation. Contemplating the story so far, as a means to consider the story yet to come.
One huge benefit of this habit is that I've become ever more appreciative of today. It's easy to forget, but we're living in the future these days—at least, with respect to who I was in 1983.
No flying cars yet, but for US$55 I was able to buy a tiny gadget called a uIED/SD that gives a Commodore 64 access to modern SD cards for storage. And, of course, I have Jason Scott's review of the more general-use FC5025 5.25? Floppy to USB Adapter to blame in getting me started on this current mini-obsession.
You want to talk about a magical device? Screw the iPad—this is magic.
This is what it looks like:
[ ... 1086 words ... ]
I just finished Bioware's Mass Effect 2 for Xbox 360, and I've got some thoughts about it. Haven't really written reviews here for games before, but I said I wanted to start posting things here that I'd want to read. So, here goes...
In a nutshell: I loved it, will play it again—but it could have been so much better.
[ ... 1994 words ... ]
It's plain to see that I've not been a blogger for a long time.
This place is a long-neglected ghost town that sees a begrudged entry every few months, when I happen to remember it still exists and I feel guilty for not feeding it with content. What I've yet to figure out is if the cause is a matter of motivation, publishing tools, audience, or writing topics.
Behold as I ramble on for many tens of words pondering the cobwebs here at 0xDECAFBAD.
[ ... 3010 words ... ]
Oh hey, look! It's another blog post—and this one
is cross-posted on hacks.mozilla.com.
I won't say this is the start of a renewed blogging habit, but let's see what happens.
Drag and drop is one of the most fundamental interactions
afforded by graphical user interfaces. In one gesture, it
allows users to pair the selection of an object with the
execution of an action, often including a second object in the
operation. It's a simple yet powerful UI concept used to
support copying, list reordering, deletion (ala the Trash / Recycle Bin),
and even the creation of link relationships.
Since it's so fundamental, offering drag and drop in web
applications has been a no-brainer ever since browsers first
offered mouse events in DHTML. But, although
mousedown, mousemove, and
mouseup made it possible, the implementation has been
limited to the bounds of the browser window. Additionally,
since these events refer only to the object being dragged,
there's a challenge to find the subject of the drop when
the interaction is completed.
Of course, that doesn't prevent most modern JavaScript
frameworks from abstracting away most of the problems and
throwing in some flourishes while they're at it. But, wouldn't
it be nice if browsers offered first-class support for drag and
drop, and maybe even extended it beyond the window sandbox?
As it turns out, this very wish is answered by the HTML 5 specification
section on new drag-and-drop events, and
Firefox 3.5 includes an implementation of those events.
If you want to jump straight to the code, I've put together
some simple demos
of the new events.
I've even scratched an itch of my own and
built the beginnings of an outline editor,
where every draggable element is also a drop target—of which
there could be dozens to hundreds in a complex document, something
that gave me some minor hair-tearing moments in the past
while trying to make do with plain old mouse events.
And, all the above can be downloaded or cloned from
a GitHub repository
I've created especially for this article—which continues after the jump.
[ ... 3204 words ... ]
I took the pills. Like everyone else, I took the pills and I sent in the hair and the piss to prove I took the pills. I’d figured something out, though: I could stop taking the pills for the first half of the month, then double up at the end. I still passed the tests; no one knocked on the door.
[ ... 184 words ... ]
Update 4/14: So, I liked rev="canonical", but I like the notion of pages offering sets of alternative URLs better. There are enough cracks in the case for rev="canonical" to stop caring about it and instead focus on the notion behind it. However it's expressed—is it rel="shortlink" now?—the final remaining things I'd like to see are:
An more generalized scope for alternate URL choices asserted by publishers, not just URL shortening. Other criteria beyond character length include ease of entry on mobile devices (eg. short, but also simple, maybe mostly numeric), ease of verbal mention (eg. billboards, postcards, etc).
HTTP headers are great where available—hooray for HEAD—but it still needs to be in the page for publishers who can't set custom headers.
Microformats are great, but I'd rather not parse a whole page to the footer to lift out the desired URLs.
Don't panic. Have fun.
And with that, I'm going to try coming up with other things to write about so this blog doesn't stay dormant. The rest of this entry remains unedited below...
[ ... 2353 words ... ]
So, it finally happened—I've been tagged by Stephen Donner. I've not been one to follow memes in this blog, but this one's been going around the Mozillasphere for awhile now and has been kind of interesting. I'm half-tempted to bookmark and tag all the entries I've caught so far. Anyway, the rules:
Link to your original tagger(s) and list these rules in your post.
Share seven facts about yourself in the post.
Tag seven people at the end of your post by leaving their names and the links to their blogs.
Let them know they’ve been tagged.
Now, for your random facts, after the jump:
[ ... 780 words ... ]
For the "too long; didn't read" crowd:
I've been using a lot of tags on Delicious over a relatively long time, so they seem very useful to me.
Delicious encourages the use of tags through UI convention and tool usage patterns, whereas Flickr presents no particular bias toward collecting tags from users.
Since title and description attract more contribution effort from users on Flickr than on Delicious, it's natural that search over those fields will be more productive than for tags.
Search on Delicious doesn't have access to the complete text of the bookmarked resource, and often tags will contain information missing from the supplied title or description.
All told, tags on Delicious are more essential than tags on Flickr.
In conclusion, I think Do Tags Work? misses the value of tags, as I know them, by focusing on Flickr.
Of course, I don't really care what this means for folksonomy and the rest of Web 2.0—tags work for me on Delicious. So, I suspect this means I'm not entirely opposed to the sentiment in Do Tags Work?, because I don't think tags work everywhere their use is attempted.
The rest of this entry elaborates on the above.
[ ... 3328 words ... ]
In my last post, I got all fluffy about how cool Ubiquity is but didn't share any code to prove the point. As it happens, I have come up with at least one useful command that I'm starting to use habitually in posting bookmarks to Delicious. You can subscribe to my command or check out the full source—this post will serve as a dissection of the thing. Since this will be fairly lengthy, follow along after the jump.
Oh, and it's been awhile since I posted something this in-depth around here, so feel free to let me know how this first draft works. And, bug reports and patches are of course welcome.
[ ... 3181 words ... ]
Update, 30 Sep 2008:
You don't want to follow the directions on this page—instead, leave this page and read this:
http://laconi.ca/darcs/README
At one point, very early on in Laconica-time, this blog post offered useful information on getting Laconica up and running. But since then, my time has taken me away from playing with Laconica and thus this guide has fallen far behind. Hopefully soon I'll get back around to Laconica hacking, but not today.
I'm leaving the original text of this post here for posterity, but this is no longer current and following this guide will do more harm than good in confusing you about Laconica installation!
Again, to learn about getting Laconica up and running, leave this page and read this:
http://laconi.ca/darcs/README
The latest mini-sensations to arrive through my firehoses are identi.ca, a Twitter-clone / microblogging site, and the Open Source software Laconica, which powers the aforementioned site.
Having started and neglected two Twitter cloning attempts of my own, Cuckoo and OpenInterocitor, seeing someone else carry the torch with any modicum of momentum is attractive to me. So, I spent a little bit last night getting the code running on my own servers, and managed to do it twice:
decafbad.com/laconica
lmorchard.com/laconica
See, the interesting thing promised by Laconica—and something I wanted in my own clones—is the ability to federate instances of the software. That is, users on one Laconica-based site should be able to subscribe to the updates from users on another site, by way of the OpenMicroblogging specification. Although federation isn't a silver bullet to a web-scale Twitter clone, I do think it's one of the most important bootstrap steps—but that's another blog post entirely.
Thus, since I'd like to see you run a Laconica site (or something like it) for mine to talk to, I figured I'd document how I got the thing running. My server is running Ubuntu Gutsy, so your mileage may vary. This is a long one, so check out the how-to after the jump...
[ ... 3686 words ... ]
Okay, so lately I've switched to using "addressbarlets" for my del.icio.us posting needs. In particular, I've been using the Super-Fast variety. I cannot stress how much better these are than clicking links in the bookmark toolbar. My del.icio.us posting has converged that much closer to command-line / QuickSilver perfection.
But, I just noticed that in my del.icio.us RSS feed, the title "del.icio.us warning: non-utf8 string! (sorry)" has been popping up--especially on Hot Links, which includes my links on a regular basis.
Well, although I'm not really all that hip to unicode and non-ASCII characters, it appears that things like SmartyPants and the use of chevrons in page titles are throwing the monkey wrench for me when the addressbarlet picks up the document.title. So, I decided to do a little sloppy butchery in my bookmarklet code to wrestle these titles into something acceptable.
After you've had a chance to try out / comprehend the original versions, take a look at this revised addressbarlet:
Post to del.icio.us and close
In case, for some reason, that doesn't come through in this entry, here's the code which should appear in the HREF:
javascript:u=%22CHANGEME%22;us=[['\u201C','%22'],['\u201D','%22'],['\u2019',%22'%22],['\u2018',%22'%22],['\u2026',%22...%22],['\u00BB','-']];function es(p){for(var i=0;i[ ... 366 words ... ]
Testing, testing--is this thing on? Well, I do have to say that I've recovered rather well from the "stroke" last week. Things have been pretty busy since then, so I haven't had much of a chance to blather any more around these parts.
However, in the spirit of a few recent experiments, I have another demo for you. Here's the URL of the latest work in progress / proof of concept:
http://www.decafbad.com/2005/07/map-test/tree2.html
What is it, you might ask before clicking a strange URL? It's an outliner, in Javascript. Or, rather, a first rough stab at one anyway. It's got a long way to go, and there are indeed better options out there already, but I wanted to try making one myself.
A quick summary of controls: No mouse drag of items yet, but you can click on them to edit. Use the up and down cursor keys to navigate through the outline. Use shift along with the cursor keys to shift items around. Use the control key along with the cursor keys to control visibility of child items.
Update: There're a few more things I didn't mention, as well as a few bug half-fixes. Hitting return when the editor is on an existing item will insert a new blank item right after it. Hitting shift-return will append a new child item to the current item. Tab and shift-tab, as well as shift-right and shift-left, are supposed to indent and outdent items. Unfortunately, they're not quite working yet and of course they semi-clobber other useful keyboard functions, so I'm still feeling around for a good way to support these.
The idea is that I want to unobtrusively drop some CSS and JavaScript into an HTML page with one or more XOXO-style outlines, magically turning them into in-browser outline editors.
But, like I said, there's still lots of work to be done here, and I'm pretty sure I've riddled this thing with circular references that will make your IE/Win combination leak like crazy. I just wanted to see if I could make something like this work, though. And, roughly, it seems to do so in Safari and Firefox.
The next part of this equation will be coming up soon, I think. And that is: Okay, now that I've created / edited an outline in my browser--how can I save it?
[ ... 1045 words ... ]
So, this weekend, I suffered a sort of minor stroke in my exocortex. The girl and I left for a bit to get food on Saturday afternoon and, when we got back, I found my PowerBook making grinding / growling noises from the general vicinity of its hard drive. A reboot or two later, and the poor thing stopped bothering to spin up the drive and just sat there in blinking confusion looking for a System folder.
Now, if you've been following along, you might be thinking, "Didn't he just go through this not too long ago?" If so, you'd be right. I'm not sure what I do to these things, since I killed an iBook hard drive like this, too. I'm very hesitant to blame Apple for this since, well, I'm just really not a careful person when it comes to hardware. I thank my lucky stars, so far, for AppleCare.
The problem this time, though, is that the failure happened without warning. The past two times, I had a bit of a gradual slide into failure with an agonizing period of intermittent function just long enough to evacuate some essentials onto another machine. But this time, boom. No warning. And stupid me: I deleted the backups I'd made back when I upgraded to Tiger.
So, my last decent backup of anything is about a year old, from the last time I had a hard drive crash. Thus, this feels a bit like a sound blow to the head. I've lost all my recent changes to my feed aggregator subscription list. I've lost all my Tinderbox documents. I'm still groping around for registration keys for all of my software. The arrangement of tools I've gotten used to being within finger-twitch range is now gone.
It's been a long time since I had a serious failure in a machine I depend on where I didn't have a recovery plan. Ouch. The two things that are keeping me from going entirely bonkers are:
The girl never sold her old iBook and I turned it into a replacement for our ailing house Linux server, so I have a backup machine until the PowerBook comes back.
I didn't lose this weekend's tinkerings because I shared them here.
Also, it's lucky that I've turned in all the chapters and artwork for the book, because I'd've really been strolling off a cliff if I'd've had to recreate any of that work. Of course, that stuff got zipped up and uploaded to at least 3 locations on a weekly basis, so I was at least smartly paranoid about that.
I guess this'll teach me though. As soon as the PowerBook comes back, and I've reconstructed my external headspace on it, I'll be setting up nightly backups to the basement file server and plan on doing monthly archival to DVD. I can't imagine how lost I'd be if I were really living in my laptop. :)
[ ... 1362 words ... ]
Another little test, this time trying to build something like a Treemap, using CSS and semantic HTML.
The above image is an example of what I'm trying to go for. Here's a sample of what I've got:
http://www.decafbad.com/2005/06/tree.html
Two things I can't seem to work around with my understanding of CSS:
Is there a way to clear the floats in the unordered lists without using a break?
Is there a way to even out the heights and widths of the columns / rows without some Javascript intervention?
[ ... 369 words ... ]
iTunes podcasting support... I want it all, and I want it now, because it has so much potential in and of itself, and so much potential for driving podcast tuner UI into the future.
The subscriptions are listed alphabetically? Come on, let me sort them in last-updated order. And what, no OPML import / export?
Not many podcast-related additions to the AppleScript scripting dictionary for iTunes. I see a subscribe method, but I was hoping I could at least hack in some support for subscription list import / export. Not having access to the subscription list puts a crimp in that.
Update: Hooray for people who know what they're talking about. Turns out there are a few more additions to iTunes' AppleScript support I missed, but I'm still not finding my way down to accessing the list of podcast subscriptions.
Update 2: Looks like someone's already worked on the import side of things: OPML2iTunes : AppleScript to import OPML podcast subscriptions into iTunes
And in the Bizzarro-Verse, Microsoft is more community-oriented than Apple when it comes to RSS extension creation. Pretty odd. I can see a few spots where the iTunes tags are defensible, but couldn't most or all of these have been established using Dublin Core or other prior work?
Bummer. It seems like the new podcasting support in iTunes doesn't use Syndication.framework, or at least the feeds subscribed in iTunes don't show up in the Sources table in the database I was snooping around in.
And here I was hoping for Tiger to have already quietly included a shared syndication feed architecture similar to what's proposed for Longhorn.
Otherwise, podcasting in iTunes seems interesting so far. Now, if it used BitTorrent out of the box...
Can I just say I hate the new binary plists in OS X Tiger? I got so used to futzing with them using vim and shell-side friends that it's jarring to get a face full of garbage now when I poke at them.
And yeah, I know about /usr/bin/plutil--but, yuck.
[ ... 486 words ... ]
Hey, what do you know? The database used by Syndication.framework on OS X is accessible with SQLite 3, assumedly by virtue of Core Data. Check out this barely presentable capture of what I just did in a shell window:
[11:34:49] deusx@Caffeina2:~/Library/Syndication$ sqlite3 Database3
SQLite version 3.0.8
Enter ".help" for instructions
sqlite> .tables
Articles Sources
sqlite> .schema Articles
CREATE TABLE Articles (id INTEGER PRIMARY KEY,
source_id INTEGER,author TEXT,title TEXT,contentType INT(1),
contents TEXT,excerpt TEXT,GUID TEXT,permalink TEXT,iconURL TEXT,
categories TEXT,date DATETIME,dateReceived DATETIME,unread INT(1),
flagged INT(1),collapsed INT(1),noComments INT(1));
CREATE INDEX ArticleCurrents ON Articles (noComments);
CREATE INDEX ArticleDates ON Articles (date);
CREATE INDEX ArticleDatesRcvd ON Articles (dateReceived);
CREATE INDEX ArticleSources ON Articles (source_id);
CREATE INDEX ArticleUnreads ON Articles (unread);
sqlite> .schema Sources
CREATE TABLE Sources (id INTEGER PRIMARY KEY,URL TEXT,
subscribed INT(1),title TEXT,iconURL TEXT,date INT,lastCheck INT,
lastUpdate INT,slider INT(1),description TEXT,homePage TEXT,
timespan INT(1),sort INT(1),HTTPdate VARCHAR,feedHash VARCHAR(40),
FOAFURL TEXT,protocol VARCHAR,lastError VARCHAR,maxDays INT(2),
maxArticles INT(2),x_monkey TEXT,x_ninja TEXT,x_pirate TEXT,
x_robot TEXT);
sqlite> select * from Sources;
id|URL|subscribed|title|iconURL|date|lastCheck|lastUpdate|slider|description|homePage|timespan|sort|HTTPdate|feedHash|FOAFURL|protocol|lastError|maxDays|maxArticles|x_monkey|x_ninja|x_pirate|x_robot
1|http://www.apple.com/main/rss/hotnews/hotnews.rss|1|Apple Hot News||141617700|141648125|141648128|||http://www.apple.com/hotnews/|||Tue, 28 Jun 2005 02:15:00 GMT|150fdf111cd223367f5c0cb8d28c65ec2a4ec195||RSS|||||||
2|http://ax.phobos.apple.com.edgesuite.net/WebObjects/MZStore.woa/wpa/MRSS/newreleases/limit=25/rss.xml|1|iTunes 25 New Releases|/images/rss/badge.gif|141577349|141648124|141648126|||http://phobos.apple.com/WebObjects/MZStore.woa/wa/com.apple.jingle.app.store.DirectAction/viewNewReleases?pageType=newReleases&id=1|||Mon, 27 Jun 2005 18:02:29 GMT|8a2c02423581414b223f4533f0bf89211e1aa6c7||RSS|||||||
...
sqlite> select * from Articles;
id|source_id|author|title|contentType|contents|excerpt|GUID|permalink|iconURL|categories|date|dateReceived|unread|flagged|collapsed|noComments
2003|5||'Mactel' desktops may offer triple-threat OS|0||Also: GE, IBM and GM: the welfare kings|http://news.com.com/News.com+Extra/2001-9373_3-0.html?part=rss&tag=rsspr.5748612&subj=news|http://news.com.com/News.com+Extra/2001-9373_3-0.html?part=rss&tag=rsspr.5748612&subj=news|||140527020|140612922|1|||0
2004|5||Virtual property becomes a reality|0||Blog: With the recent sentencing of a Chinese man who murdered an acquaintance in a dispute over a virtual sword, talk of the growing...|http://news.com.com/2061-10786_3-5748748.html?part=rss&tag=5748748&subj=news|http://news.com.com/2061-10786_3-5748748.html?part=rss&tag=5748748&subj=news|||140579040|140612922|1|||0
There's one piece up there that had me do a coffee spit-take, though:
x_monkey TEXT,x_ninja TEXT,x_pirate TEXT,x_robot TEXT
Seems like the Syndication Wars have progressed, and the various sides have enlisted all of these combatting factions. Monkey vs Robot, Pirates vs Ninja--I only wonder whether the Ninjas and Robots will ally against the Monkeys and Pirates? It just seems natural.
[ ... 418 words ... ]
Now for some quick GreaseMonkey spew, recorded without any effort to actually see what's up in the community or reading any FAQs:
I want to separate script code into reusable modules.
That said, am I an Architecture Astronaut when I can't get more than 10 minutes into a quick project without already starting to digress into building a reusable framework?
Is it wrong that I felt like I was working in Perl again when I wrote that script?
That said, I wish JavaScript had either multi-line quotes ala Python or Perl heredoc syntax.
Doing some twisty regex search-and-replace in Vi lets you do a lot of refactoring / recoding damage to source code in no time flat.
Can I just say how nice it is to not worry about other browsers when coding?
I've also got a few ideas I'd like to record and pursue for future GreaseMonkey endeavors:
Record the URL of all form submissions via XMLHTTPRequest to a remote server, with blog comment forms in mind. Track changes on those URLs. Notify me via Atom feed when new comments arrive in places where I posted comments.
Clean up and abstract that magic form thing I did into a more general way to make all kinds of magic textarea forms. (More microformats? .sig files for LiveJournal responses? /usr/bin/banner for annoying blog comments?)
Revive Third Voice in GreaseMonkey style. Subscribe to arbitrary REST API'ed annotation servers, fetch & aggregate annotations for current URL via XMLHTTPRequest, build cute floating stickies with rude comments from friends.
Auto-ROT13 en/decoder ring, because there's a need for that.
Script which redirects all links to books on Amazon.com to point at my new book. I will install this on all computers at CompUSA and the Apple Store.
I've suddenly realized that a lot of the things I wanted to do with Agent Frank are possible with GreaseMonkey. Also, I wonder how long it'll be before I get sucked into further FireFox extension hacking.
[ ... 740 words ... ]
Update (6/9): One quick note-- I've noticed that this little hack of mine has been called a "hack for Movable Type". However, while I personally use Movable Type, this is a hack for textareas in FireFox.
Movable Type just happens to use textareas. It's worth noting, however, that WordPress uses textareas too. So does LiveJournal. So do most comment posting forms. This is bigger than a single blog package plugin-- that's the point.
Whew. So it looks like the book is out of my hands now, having finished the final reviews. I have some more to say about that, but first I want to post the results of the last day or so of hacking I've done.
I've been working on the stuff for the book so long that I just had to do something else (ie. not RSS or Atom) to help clear my head. But, I'm addicted to learning and building stuff. So, although I did relax a bit since the main effort of the book passed--that is, relax as normal people define it--I just can't stop making things.
So, I had a beer, cracked open Dive Into GreaseMonkey, and decided to make good on that idea I wrote about last month. Not only that, but I had a little free time over lunch today, so I downloaded a trial of Snapz Pro X 2 to try my hand at a little screencasting, ala Jon Udell.
I've got more things to say about all this, and my new found excitement for GreaseMonkey, but first I'll share the goods.
If you want to risk running my horribly premature code on your machine, here's the script:
magic_hcalendar.user.js
If you'd like a preview of what it does, here's a movie:
magic_hcalendar.mov
And, just for the sake of completeness, here's a quick screen grab:
[ ... 584 words ... ]
Implementors should be aware that the software represents the user in their interactions over the Internet, and should be careful to allow the user to be aware of any actions they might take which may have an unexpected significance to themselves or others.
In particular, the convention has been established that the GET and HEAD methods SHOULD NOT have the significance of taking an action other than retrieval. These methods ought to be considered "safe". This allows user agents to represent other methods, such as POST, PUT and DELETE, in a special way, so that the user is made aware of the fact that a possibly unsafe action is being requested.
Naturally, it is not possible to ensure that the server does not generate side-effects as a result of performing a GET request; in fact, some dynamic resources consider that a feature. The important distinction here is that the user did not request the side-effects, so therefore cannot be held accountable for them.
Source: HTTP/1.1: Method Definitions
So, like... uh... Did Google build their accelerator that way just to provide a dramatic example of why explanations of REST focus repeatedly (to the annoyance of some) on the fact that the HTTP GET method is specified as and should be implemented as idempotent?
Seriously. Did they? Well, at any rate, I guess they didn't read this PDF:
Assertion: Prefetching With GET is Not Good.
But, eh, I hadn't read that PDF until a few minutes ago anyway. Though, it is kind of funny that I found it as the first hit on Google for the terms "rest get idempotent prefetch problem". (Which, snarkily, is really the only reason I mention it.)
Yes, one could argue that only "badly designed" web applications that don't follow the rules of GET and POST will be affected, but I'm not sure this is an argument that Google (or anyone else who actually builds or uses web apps in the wild) would care to make in this situation.
Source: O'Reilly Radar: Google Web Accelerator considered overzealous
Er, oh yeah... I guess I can't be too smug about GET and idempotency, now that I look at a few of the web apps with which I've been involved. Yeah, that smarts.
Although, I do have to say that most of the nonidempotent-(read: broken)-GET-driven things I've put together tend to be behind href="javascript: do_foo()" function call links which, while hated by some, would have protected you from this--at least until Google's prefetch learned JavaScript.
Bah, I say. Maybe it's time to start actually, really paying attention to this?
[ ... 539 words ... ]
I hate to admit it, but I've seen the leaked premier. After reading the glowing review on Warren Ellis' blog, I couldn't resist.
Within the first 15 minutes, I knew what I was watching. (And, in fact, I recognized the Autons!) Other than the lack of a long coat, big hair, and scarf, this guy is him. (Though, I don't think I'll be shaving my head to continue my fashion tutelage.)
It's like things picked up right where they left off--cheesy plot, goofy incidental music, sonic screwdriver, and all. Most important of all: I'm so glad that it didn't get a revival by way of an American studio, although I do wish it'd gotten picked up by the SciFi Channel.
Just as soon as there's a DVD for sale, I'll be ordering it. I don't suppose they take foriegn donations? Or maybe I could just pay off some Briton to offset the taxes or license fees they paid to support the show's production? I don't even care if this was a promotional stunt.
[ ... 178 words ... ]
The Back to the Future trilogy is, hands down, a work of genius. And I was overjoyed to watch the whole run on TNT this weekend while I worked on yet another book chapter.
Someone needs to buy me the complete BTTF trilogy. Or, maybe I need to buy it, once my head bobs above water.
Why is pasting plain old unformatted text in Microsoft Word considered a "special" paste action?
And, if Word helpfully extends my selection range one more time, I'll shoot it. I thought I turned that damn feature off.
Have I mentioned that I hate Microsoft Word? I'm up to about 175 pages across 8 chapters written, and I find myself gazing wistfully at TextEdit.
After wrestling for months with libxml2 for FeedReactor, and all the issues I had getting the Python bindings compiled and working on Mac OS X, just so I could play around with XPath and some decently fast XML handling... I discover that 4Suite installs like budda on Linux, Windows, and OS X, and seems pretty fast. I've only used it for XPath so far, but I'm curious to try out what it does for XSLT.
Your moment of webcomic zen:
[ ... 329 words ... ]
Here goes nothing--atomic bullet points to power, quickie turbines to speed...
Pyjamarama is my song of the evening.
I've gotten hooked on [Vim][vim], having defected from [xemacs][xemacs], because I like keeping more of my user interface in my headspace and [adopting modes as fighting stances][vimstances].
[vimstances]: http://fallenearth.org/blogs/caiuschen/archives/2005/02/15/foot_pedals_in_vi_vs_emacs/index.php
[vim]: http://www.vim.org
[xemacs]: http://www.xemacs.org
I haven't been paying attention to my web stats. Does anyone out there actually read and enjoy my links, since I split them out of the main blog? (Just curious.)
I've been thinking lately that my innate fashion instincts come from the Tom Baker era of Doctor Who. Thankfully, I have a girlfriend who helps dress me. The hair's still getting pretty unruly, though.
Quick News is the NetNewsWire of the Palm OS world. It can even download podcasts! And it's only $15 bucks!
Primus says:
Funny thing about weekends when you’re unemployed.
They don’t quite mean so much,
Except you get to hang out with all your working friends.
[ ... 412 words ... ]
So, in the spirit of pico-projects, I've started building that address book application I mentioned awhile ago and I want to start writing about it as I go.
First off, hopefully you'll notice the quick diagram I threw together in OmniGraffle. This is a sort of rough sketch of the loosely-joined architecture I want to explore with this thing.
Data: This is where address book entries live.
Model: A set of objects encapsulating the data, this is how address book entries will be accessed.
REST API: Model objects exposed as resources identified by URI, serialized and deserialized as XML, and manipulated by GET / PUT / POST / DELETE methods.
XSLT Filter: XML data produced by REST API calls can be first passed through XSL at a given URL before being served up as a response.
HTML, CSS, JavaScript: Thanks to the XSLT filter layer, the XML vocabulary used to describe address book entries can be transformed into user interface presentation.
HTTP: Everything happens via HTTP...
Web Browser Client: ...and everything is viewed in a web browser.
Now, I call this a loosely-joined architecture because I want to stress that you should be able to swap out just about any part of this whenever you want.
Want the Data to be in MySQL? Fine. Want it to be in flat files? Fine. Just make sure the Model can cope while maintaining a consistent interface for the REST API. Want to change the user interface in the browser? Great-- ideally, all you have to do is change some XSLT files. I'm writing everything from the XSLT Filter down to the Model in Python. Don't like that? Fine. Rewrite it all in Perl, and hopefully everything from the XSLT up to the browser will still be useful to you.
At some point, you might even want to ditch the browser for a native desktop client. Fabulous! Just ignore everything past the REST API and HTTP, don't use any XSLT in the Filter, and use the API and XML directly.
I don't think any of this is particularly revolutionary-- although I thought it was when I first saw Amazon Web Services doing some of this, and I hope to throw a little GMail in as well. I hope that this will all be useful as I muddle through explaining what I'm doing. In the meantime, you can see me getting the stage set as I start checking things into my Subversion repository over here:
http://www.decafbad.com/svn/trunk/hacks/abook/
[ ... 712 words ... ]
Synchronet Bulletin Board System Software is a free software package that can turn your personal computer into your own custom online service supporting multiple simultaneous users with hierarchical message and file areas, multi-user chat, and the ever-popular BBS door games.
...
In November of 1999, the author found a renewed interest in further developing Synchronet, specifically for the Internet community, embracing and integrating standard Internet protocols such as Telnet, FTP, SMTP, POP3, IRC, NNTP, and HTTP. Synchronet has since been substantially redesigned as an Internet-only BBS package for Win32 and Unix-x86 platforms and is an Open Source project under continuous development.
Source: Synchronet BBS Software
This software deserves so much more attention. It's like an old-school BBS, complete with ASCII/ANSI menu screens and everything, but it's been modernized: It offers a slew of Internet protocols integrated with the message bases and file areas. It's got an HTTP daemon with server-side JavaScript. It works on Win32 and various Unix platforms. Everything above is true. And it's open source.
In the 90's, I would have expected software like this to be at the core of a startup company stuffed with superfluous and overpaid code monkeys. It would have turned into an Enterprise Application Server or Intranet Knowledge Management Solution-- a mini Domino or Lotus Notes. And, in fact, I seem to remember seeing a few old-school BBS packages get mutated and gigantified by the dot-com radiation in this way.
I keep meaning to get a Synchronet BBS up and keep it up, and maybe get a few interested users logging in, if only for the retro-gaming experience for things like Trade Wars, Barrent Realms Elite, Legend of the Red Dragon, Global War, and anything else I can find.
I really miss the tidal-pool effect BBSes had back in the day, when in my area they were the first and best gateways to the Internet. Direct SLIP and PPP access to the net were rare things still and, before the web took off, Usenet and IRC were some of the best things around. But, anyone who wanted to get the the net had to wander through the local BBS first.
It was really neat to see the mish-mash of people all drawn together by geographic areas denoted by telco area codes. The degree of Aspergers affliction and just plain dysfunctional nerdity gradually decreased as sisters and friends-of-sisters were introduced to terminal programs and teleconference. It was sad to see all of this gradually die off as more and more callers came in via SLIP/PPP dialers and headed straight for the information superhighway on-ramps. All the gift shops closed up and no one showed up in the café anymore.
Sigh.
But, at least Finland isn't a long distance call these days.
[ ... 622 words ... ]
I'm a complete neophyte when it comes to machine learning, but I'd like to get into learning more about the field in general. In particular, I'd like to make my news aggregator smarter. I've already tried using SpamBayes, but that didn't make me happy. Whether it was my approach or whether it was that Bayes itself is not suited toward this task, I'm not sure, though I suspect it's a little of both.
It seems like the magic Bayesian pixie dust works well for spam-vs-ham in my email box, so why shouldn't the magic for interesting-vs-yawn work for my aggregator firehose? Well, here are the issues I'm guessing at:
In the case of spam-vs-ham, you want to classify things into this or that-- that which is kept, and that which is tossed away. But in the case of items in my aggregator, I want a relative sort order or a score. I want a fuzzy guess toward my interest with which to inform presentation of items. Interesting-vs-yawn is more of a continuum than a pair of buckets.
And then, there's the passive gathering of behavioral data from my interactions with the aggregator, because I'm sure as hell not going to click ratings or thumbs-up/down all day. In spam-vs-ham, I could build up two clean mailboxes for training the categorizer, with one containing all spam and the other all ham. But, in the case of my aggregator, the only thing I'm tracking are items in which I showed interest by revealing more information or by clicking through.
So, I can say that a particular pile of items are all interesting. But, my interest level for the rest of the items received is a complete unknown-- maybe I'm vehemently disinterested in those 50 items, but maybe I just never got around to looking at those other 20 and just let them fall off my date range for display. Thus, I have a pile of ham, and a pile of undifferentiated unknown. I'm not bothering to provide any cues as to whether I don't like something, because that'd be boring work-- I mean, I am disinterested in those items, after all. So, I'd like to leverage what the system knows from what I care to provide, but not jump to any conclusions about the items in the unknown pile. There is no spam, only various flavors of ham.
Given all this, then, is there anyone out there who knows more about machine learning than me who could maybe point me toward a better approach or algorithm that fits this profile?
[ ... 1066 words ... ]
I've recently been doing some side work involving Zope and, along with the rest of the suite of technologies it offers, I've been happy to be working with Zope Page Templates again. I dabbled with them a bit when they first came out, and a Zope-free implementation named SimpleTAL was one of the core components of the iteration of my news aggregator which came before FeedReactor.
Out of all the templating and content generation approaches I've used, Zope Page Templates are my favorite yet. Pretty expressive, yet unobtrusive; nicely powerful, yet not quite something with which you'd want to write an entire application (and that's a feature, not a bug).
I've yet to be in a work-a-day team that uses ZPT-- but I can see where a lot of production, delegation, and integration issues would have gone much smoother had I used ZPT instead of Template Toolkit for the web app framework I created at a previous company. (Though I do have to say TT2 is very nicely done!) And where I am now, I spend most of my days trying to pummel ASP 3.0 pages into some semblance of logic/presentation separation-- I would certainly dive at the chance to dump VBScript and <% cruft %> for a bit of Python and ZPT. (But, you know, it's a living.)
A close second favorite is XSLT. I've really been hot on it lately, having worked it into the core of FeedReactor in place of SimpleTAL. And in other hacks, I've really come to appreciate it's role as a filter segment in pipelines between REST web services and URL-as-command-line invocations.
Granted, both ZPT and XSLT very different technologies, but they are often used in similar contexts. More than once, I've wished that XSLT was as simple as ZPT (i.e. less verbose and intrusive, more document centered), and I've wished that ZPT had some of the features of XSLT (i.e. ability to be used as a transforming filter).
Reading Ryan Tomayko's description of Kid got me thinking, and googling. One thing I turned up from a mailing list archive asked about an “XSL implementation of TAL?” It struck me as a tad nutty at first, but then I started having inklings that just maybe it could be done. (Whether it should be done, well...) But the kernel of the idea grabbed me: Instead of using TALES path expressions to look up values in Pythonic space, why not use XPath expressions to look up values from a supplied XML document?
This strikes me as such an obvious idea that someone has to already have done it and possibly rejected it for good reason. On the other hand, maybe this is the sort of thing Ryan's thinking about-- I wonder how hard it would be to hack this into Kid? It would give only a subset of XSLT's capabilities in trade for simplicity, and would only offer the “pull” approach, but it would give XML-pipelining to a ZPT-ish technology.
I think this is something I want to look into a bit further at some point.
[ ... 1167 words ... ]
You know what I was just thinking? Why doesn't Froogle have an API like Amazon? It's nearing Christmas again, and other than my occasional hacking activities, now is when my Amazon wishlist gets the most play. Well, that and on my birthday.
But, since my mind's been on shopping a bit, I've been checking out Froogle. Did you know that Froogle has wishlists? Man. I knew that back in the mid-90's I should have gone with that great business idea I had for making a site devoted to wishlists and aggregated shopping, maybe make some cash off affiliate fees. But anyway, now that I see Froogle's doing it, I have the notion to migrate my eight pages of wishlist items over to Froogle.
But, no! There's no API, and I'm feeling too lazy to hack any screen scraper web robots together. So. I'm probably weird for this being the deciding factor, but for now, Amazon retains my patronage. Funny thing is, although it's a mild form of data lock-in, Amazon does have an API and I can scoop up my wishlist items whenever I feel like it. It's just that there'd be no convenient place to put them right now.
[ ... 228 words ... ]
So, like I was saying: I've been working on FeedReactor and have been doing some things with it that I find rather interesting, independent of news aggregation.
One of the core goals I have for FeedReactor is to explore what it takes to build a web app that exploits principles of REST architecture. Having already sung the praises of XML-RPC, I wanted to get immersed in REST and see what all the hubbub was about. I've got some ways to go, but I think I understand the major concepts now, and it's a pretty nifty frame within which to work.
But, two other things I've added to my mix have really made things interesting for me:
XSLT filtering
The XmlHTTPRequest object
XSLT and REST make a really good pair, as Amazon Web Services already demonstrate. Inspired by that API (and earlier experiments), I use XML for all the input and output formats in my API and accept a query string parameter that contains the path to an XSLT file. When this parameter is supplied, the XML output by the API is first processed using the given XSLT. (Think of it like piping API output through xsltproc.)
So, with a properly constructed collection of XSLT, I can present a browser-viewable HTML user interface served up directly from REST API calls. Links, frame sets, and iframes present in the HTML lead the user from that call to the next XSLT-wrapped REST API call.
But, once the initial HTML-and-JavaScript payload reaches the browser, it gets better (ala Gmail):
On older browsers (if I happen to care about them), I can make new HTTP requests back to the server from JavaScript using iframes. In this case, XSLT filtering lets me retrofit the API's responses to the HTML-and-JavaScript crud I need to serve up to make things happen back in the browser client. Unfortunately, passing data to the API (which expects XML, not form submissions) is still a bit wonky and requires some hacks and exceptions involving hidden forms and such.
However, on the newer browsers, it's all about the XmlHTTPRequest object. With this facility, I can make clean asynchronous requests back to the REST API, including XML data in the request body if I feel like it. Responses are handled by JavaScript callbacks, which twiddle the browser DOM to update the user interface in response.
So, after the major initial contact with the API to supply the browser with HTML by way of XSLT, most future interactions take place in the form of direct calls to the REST API using XML. Although for some things, it's easier to just reload a page of HTML, it's nicer for most interactions to be handled via DOM manipulations in-place. I've been amazed at the Gmail-like responsiveness I get from FeedReactor when I'm skimming through news items, marking some as seen or flagged, and popping open the descriptions on others.
I suppose I shouldn't be amazed at the responsiveness, since I'm using some of the same techniques as Gmail. However, my daily-use installation of FeedReactor is presently running on an old 300Mhz Debian Linux PC at home, and it's taking me through the daily produce of 600 subscribed feeds faster than any desktop aggregator has yet. Of course, this is partly a product of my familiarity with the UI I've cobbled together, but... the server's running on a 300Mhz PC with 256MB of RAM! And the client is my 867Mhz G4 PowerBook, running Firefox or Safari, depending on my mood.
Although I can't see when I'll have time for it, I really want to explore this approach further using desktop apps on OS X and accessing the API from Flash movies (maybe using Laszlo). I'd also like to see how far I can go toward adapting the interface toward mobile devices like my Treo 600.
So anyway, this has been where most of my private hacking sessions have been taking me over the past year or so: combining HTML, CSS, DOM, JavaScript, XML, XSLT, and REST to build what I consider to be a next-generation web app.
Now, although I use FeedReactor on a daily basis to keep up with all my feeds, it's nowhere near any state suitable for public consumption. I add new subscriptions from a command-line script and still fiddle with the database directly for some operations. I'd like to have a personal-server version of it ready for use by some alpha geeks before or not long into the new year, but I'd like to share some of the things I've been doing with it before then.
With that in mind, I think I'll wrap up this entry and think about putting together a quick tutorial pico-project to demonstrate some of the concepts. Maybe an address book, or something equally simple-yet-useful.
Stay tuned.
[ ... 918 words ... ]
It's the last month of 2004 tomorrow, and it's occurred to me that I haven't spent much time around here.
Doing a quick check, it looks like I've written a little over 50 posts this year, down from around 170 last year. And the year before that was around 340. Mainly, my activity around here has progressed toward much more link blogging using my own tools and, more recently, del.icio.us. When I actually have written something of my own lately, I've tended toward sweating over longer entries or nothing at all.
Does all this mean I'm an ex-blogger? Or was I ever? On the other hand, who really cares? Funny thing is, I'm sure I can find a few dozen entries I've written, self-flagellating about not writing more often.
If I were to let you read from my handwritten journals, you'd find the same thing every few entries. It seems I suffer from a strange complex of guilt and pedestal building: I feel guilty for not writing more, but then when I have something quick I could write, I feel guilty for not having something grander to offer.
Of course, there's also the fact that I had a really busy streak in my work-a-day life for awhile there, but for the past month or so I've mostly been lying fallow. Now, I'm getting antsy to produce some Worthwhile Things again.
Bah. How about an early New Years' Resolution to follow my own advice and let my brain dribble barely-worthy crap here on a more regular basis.
And, how about I make this the last entry I write about not writing entries? I'm sure I can come up with other topics about which to write when I can't think of what to write.
[ ... 390 words ... ]
I've had an iPod for a little over a week now, and I've been working pretty diligently to rate every song I hear and trying to make sure all the metadata is correct. I've even started tinkering with tagging songs using things like :dreamy, :goofy, :energy, :calm in the comments field for use with Smart Playlists. (Yeah, I know about TuneTags, but the psuedo-XML in song comments bugs me, as does the somewhat buggy behavior of the last version of the program I tried.)
By this point, I've managed to cram about 3400 songs from our CD collection into it. (So much for the marketing!) With my efforts so far, a “Good Music” Smart Playlist selecting for 3-stars and above gives me around 415 songs. This doesn't count the songs I've rated with 1-star, which get deleted from the iPod periodically. Also, I've yet to get a significant proportion tagged with special comments, so mood-based and concept-based playlists are far off until I get a better tool for letting me quickly and lazily tag songs.
So, this morning on the way into work I fired up my “Good Music” playlist on random for the first time, and I was amazed at how good the selection was. Yes, I rated these songs, so I should know they're good--but so far, I've had all 3400 songs on shuffle and have been alternating between listening and rating, skipping songs I wasn't in the mood for, and canning songs right off the bat with a 1-star rating. So up until now, my rotation has been an okay experience.
However, hearing that mix of consistently high rated songs was an unexpectedly good experience. What occurred to me as I rounded the last stretch of I-75 into Detroit this morning is that this metadata and these Smart Playlists on shuffle amount to an attempt to tickle myself. Ever try that? For the most part, it doesn't work. Sure, you know where you're ticklish--but if it's your hand trying to do it, you're expecting it and the tickle doesn't happen.
I'm probably stepping too far into breathless pretentiousness with this, but it makes me want to think further about machine learning and intelligence. Yeah, Smart Playlists are a very, very rudimentary form of intelligence, but it's good enough to tickle me with a music mix--which is a very real bit of value added to my life.
I wonder how much further this tickling-myself metaphor can be taken? That is: take a machine endowed with information I produced, apply some simple or slightly complex logic with a bit of random shuffle, and feed it back to me to see if it makes me experience it with some novelty. Someone's got to already be on top of this as a research project. That, or it's an idea obvious or dumb enough only to appeal to me.
[ ... 973 words ... ]
So I finally got myself an iPod, thanks to The Girl.
Through various twists of replacement policy and iBook promotional antics, somehow she ended up with two 20GB 4G iPods, both of which she's been planning to sell off on eBay to end up with some cash and an iPod Mini. Well, it finally occurred to me this weekend that I needed to buy one of those iPods.
Lately, I've been only been listening to streaming radio at work, since I don't really have the hard drive space on my PowerBook for music, and loading up the work PC with MP3s is pretty unpalatable. I miss the days when I had a 40GB library at work, but between company policy where I am now and having lost that whole library in a hard drive crash back then, I'm hesitant to go there again.
Enter the iPod. I was reminded of its presence in The Girl's office, still boxed up and shrink-wrapped, at a moment when I was thinking about podcasting and thinking about my lack of hard drive space. So, I gave in and snapped it up.
Thus far, I'm pretty happy. Sure, I'd been looking at the larger capacity models that came with a dock and remote, but this one was the right price at the right place and the right time. I was also lucky that she had an iTrip she was selling that just happened to work satisfactorily for playing MP3s in my car - something that's been a bit of a quest of mine for years. While it's true I do have an in-dash Blaupunkt MP3 CD player in my Ford Focus now, it's also true that 20GB certainly outweighs 700MB.
The few snags I've run into so far mostly have to do with the fact that it seems like my desired usage pattern of the iPod isn't quite supported. See, I don't want to have a massive library on my PowerBook, to be synched in part onto my iPod. I have a library on a file server at home, and I want to use the iPod alternately as a music store away from home for iTunes on my PowerBook and as an MP3 player while I'm driving. I don't want any music at all on my PowerBook. Problem is, though, the iPod isn't quite a first-class citizen in iTunes. Party Shuffle doesn't work, and I had a few problems with making sure metadata (like ratings and last played date) made it into iTunes.
Oh yeah, and I wish they'd turn down the wheel sensitivity way down when setting a song's rating. At present, it's just a bare millimeter of a finger's twitch to leap from 1 to 5 stars. Might just be me.
But, for the most part, I'm very happy to have my own music at work again, and the potential of tinkering with smart playlists and podcasts are exciting to me. That, and the fourth-generation iPod is just an elegant, slick joy to hold.
[ ... 900 words ... ]
The future of syndication that folks at Web2.0 are professing is really structured around information organization and access. It's about people who are addicted to content, people who want to be peripherally aware of some discussions that are happening. It is not about people who use these tools to maintain an always-on intimate community. There is a huge cultural divide occurring between generations, even as they use the same tools. Yet, i fear that many of the toolmakers aren't aware of this usage divide and they're only accounting for one segment of the population.
Source: apophenia
- a culture of feeds: syndication and youth culture
As I was writing about falling for the podcasting hype, I'd mentally queued up some ideas for something further relating to my growing addiction to NPR and news in general. Danah's writing about youth and feeds and intimate communication versus institutional communication resonates well with what I've been tossing around in my head.
When I was in high school, around about the time Ross Perot was getting into the presidential race, I remember putting a little item on my to-do list in my brand new day planner:
Read the newspaper, watch the news.
I must've been, what, 16 years old? I suppose that would have made me one of the youths Danah's talking about, albeit of an earlier generation of online communicators. At the time, the bulk of my disposable income earned as a grocery store bagger was spent on music CDs, gas, and the occasional upgrade to my Commodore Amiga. I didn't even know was NPR was, though I knew there was this thing they did with news on the radio. But newspapers and talk on the radio were things that my grandparents paid attention to, if anything.
The only reason I put that item on my to-do list--in fact, the only reason I even had a day planner with a to-do list in the first place--was because, according to the teachers trying to prepare me for college, this was what grownups did. Planning your days and reading the news were things that adults did, and if I wanted to be an adult, I should get with the program. And I wanted to get with the program, but I really didn't see the point yet.
However, I did live most of my social life online. Now, that needs a bit of qualification: Of course, I am a big geek and many of my kind spend their days living in Mom's basement talking to men pretending to be 14-year-old girls. But, back when I was first getting online, the main gateway for access was the dial-up BBS, preferably one that was a local call to your area code and prefix. What that meant is that most of the people I was chatting with online were within a 16-year-old's parentally condoned driving radius.
So, I never lived in the basement, and I did actually get out quite a bit. The only real strange bit was that very few of my social group went to school together--and actually, most of us were misfits in school, some counting the minutes till we could get back to each other. Having just finished Cory Doctorow's Eastern Standard Tribe (read on my Treo 600, my comm, no less), I can totally grok the tribes. Mine was as small as an area code or two, rather than a time zone, but I had a tribe. Still do, even though we've since dispersed across many, many area codes. Now there's LiveJournal and Xanga, among other tribe-building technologies.
But lately, in the past few years, I've been changing. I'm only 29 now, but I've learned what a day planner is for and my to-do list is crucial; I know enough about the news on TV not to watch it much, yet I pull in enormous volumes of news from online sources and magazines. And, as I wrote earlier, NPR is now the only station on my radio dial.
When I was 16, the presidential race was a curiosity about which I felt vague guilt for not knowing more. But, this time around I'm giving it an attention and range of emotion akin to a rabid sports fan during playoffs. I lost sleep over whether or not my voter registration was up to date with my correct address. I do realize that for many, many reasons this particular presidential race is historic. But I'm a johnny-come-lately--there've been historic presidential races before: history didn't start because I started paying attention.
What's happened is that I've changed. If I could time-travel and stop by to say hello, my high-school-self would probably admire who I am now, but wouldn't quite understand me. He'd get the half-dozen IRC windows I have open, and the handful of IM windows I'm floating at any particular moment, but I doubt he'd get the lure of my news aggregator in the background. I loved Jesus Jones at the time, but I didn't really know what it meant to be an Info Freako.
What changed in me? I'm not quite sure. I'm sure there's something going on with hormones and the few grey hairs I have now. But I think it has something to do with actually starting to become a grownup. That is, I'm paying taxes, I'm acting in the world, I have responsibilities, and I've left the shelter of my parents' house. All the way from elementary school through college, I was on rails, and there wasn't much I needed to know other than what they were teaching to get by. Now, though, I'm off the rails, and I feel I need all the information I can get, just to figure out how to navigate.
Maybe it's become obsessive, but I don't want to miss any vital data that will help lead me toward my bliss, to grow up without growing old. And I know that, however small, my actions have consequence in the world, so I want to understand. I am a member of a civilization. I think I get that now.
So, anyway, if anything I'm just underscoring with my own experience that usage divide between youth and older info freako adults Danah wrote about. I've been on both sides of it now, I think.
Where I think I disagree a bit is about trends: she asks if this Info Freako style of massive feed consumption will be relevant beyond the Web 2.0 crowd of today. As an early adopter of a technologically-driven social life, I would have to guess that the current generation will produce some even more obsessive Info Freakos than the oldsters around today.
Because, if my own experience is any guide, we start off using the technology to talk to each other in tribes. However, as (or, I guess, if) we grow up and become fully acting members of our civilization, we turn to the same sorts of tech to converse with the civilization itself. Whether that will take the form of massive feed consumption, I don't know, because I have to assume the tech will be very much changed by then. I can see the intimate communication habits progressing to civic and national and global communication habits, even in myself.
The problem, though, is that once you start making ventures out of your tribe, you start running into the limits of your neocortex. Communication must necessarily lose its intimacy and give way to group-to-group and one-to-many conversations. That's where I see feeds coming in to supplement IM and email--though I certainly hope by then that there's a lot more intelligence behind feeds and microcontent routing and user interface, a lot of the principles will be the same.
But, in any case, I think we're in for some interesting history coming up, as more youths used to texting each other take up roles as members of civilization.
[ ... 1328 words ... ]
So I had an idea for a quick podcasting listening hack on the way into work this morning. Check it out:
Take one list of RSS feeds in OPML.
Throw in a bit of XSLT.
Combine using xsltproc to make a playlist that works in iTunes.
And, oh yeah, I just happen to have an xsltproc web service laying around, so:
Supply a URL to your OPML in this form.
Get a freshly-built playlist.
Now, this has been barely tested and is the product of a ten-minute hacking session. There are likely an enormous number of things wrong with this. That said, iTunes does seem to open the playlist happily, and it looks like only new streams are added with repeated openings of the playlist.
You will want to be careful to ensure that your OPML is valid XML (mine wasn't, on initial export from iPodderX - escape those freaking ampersands in URLs already!), and I have no idea what would happen if any of the RSS feeds in your subscriptions turn up invalid.
Have I mentioned that, despite their unforgiving and sometimes fragile nature, I love XML technologies?
If this looks useful, maybe I'll work it over a bit more and pair it up with some python to handle actually downloading the MP3s and torrents.
Update: Oh yeah, and I'm expecting this will be useful with an iTunes smart playlist crafted along these lines:
Date Added in the last 1 days
Play Count is less than 1
Update #2: Another use I just found for this playlist, is on my Xbox Media Center. I generate this playlist via cronjob every few hours, and store it on an SMB share accessible to the XBMC. Voila! Listening to podcasts on my stereo system via the Xbox. Yeah, nothing big, just kind of nifty.
[ ... 339 words ... ]
So, over the last day or so, I've found myself falling for the Podcasting hype.
Yeah, yeah, I know -- I listened to and read Maciej's audioblogging manifesto (and, yes, that's a link to the text version, which kind of helps support the argument therein) but I think the addition of portable digital audio players and RSS feeds with enclosures to the mix changes things.
The whole audioblogging thing has seemed incredibly stupid and annoying to me, since my experience of it so far has mostly consisted of this: I navigate first to a text blog entry, click on a link to an MP3, then stare at the screen as the thing plays. Being a high-bandwidth Info Freako, a feeling of time wasted comes upon me pretty quickly. I can speed read and I want to get through this quickly, but I can't speed listen. I want to throw a bookmark at del.icio.us if I like it, but I can't select any text. Getting a bit bored, I start thinking about how maybe I might want to remix this crap, make a funky beat out of all the utterances of “um”, “ahh”, and “err”.
So, yeah, this sucks. Not picking on any particular audio blogger or post -- because they're almost all like this -- but I want that 4 minutes of my life back.
But the thing is, I'm a news radio junkie. I abandoned listening to music over the air almost seven years ago, so when I'm not listening to MP3 CDRs, my car tuner is almost perpetually locked on NPR. I listen to people jabbering at me at almost all times while I'm driving. And at work, I mix listening to my MP3s with streaming talk, news, and old sci-fi radio stations.
The difference here is that radio doesn't demand much of my attention. I'm usually doing something else while I'm listening, like driving or working. I don't have to navigate to anything, I don't have to provide any feedback or make any decisions--I just have to let it stream into my head. The lower mental demands of audio and a lack of necessary interaction dovetail nicely with multitasking.
So, in come iPodderX and friends. They're feed aggregators specifically built to slurp down audio enclosures and sync them up to audio players like the iPod. The idea is that, when you leave home, you take the digital audio player with you, loaded up with your own personal radio programming. Not having an iPod, I've been queuing these aggregated audio posts up in iTunes at work, and I've been playing around with burning CDRW's for use in my car's in-dash MP3 player. Once I get a headphone adapter for my Treo 600, maybe I'll start listening to them on there.
With this switch of perspective, I think I'm falling for the hype. The key is to get out of the way: aggregate, queue, and play in the background. Yeah, there's going to be a lot of awful crap out there, and lots of dorks eating breakfast and lipsmacking into the microphone as they blab (this is me, shuddering)--but as the number of podcasters expand, we will start to hear some blissful hams showing up with things worth listening to.
I'd like to do something, but I doubt I have the time or insight to produce something worth listening to on a regular basis. Adam Curry suggested doing things like a daily quote, jokes, or skits--short, good things have value. (Pete's encounter with frozen pizza instructions on Rasterweb Audio made me snort a bit.)
The first thing that comes to my mind are these old sci-fi radio broacasts to which I'm addicted. While I have written stories of my own, I wonder how much public-domain or Creative Commons licensed content is out there available? Could be fun to do some readings and a maybe do a little low-budget foley work. Of course, there's the hosting and bandwidth to worry about, though I suppose BitTorrent could help if the aggregators support it (and they should!)
In any case, I think the podcasters are on to something here. I'll be listening.
[ ... 841 words ... ]
You, who ever you are, do what you want; but if you’re only here to be the next Kottke, or Scoble, or Stone, quit now. You’ll never get to their position aping their behavior or their rules; you’ll just end up miserable because you’re not writing the way you want, and for the joy of the act. Fuck me, too many sheep in this environment. How can your ‘ba-ah-ahh’ be heard when you’re surrounding by people bleating the same thing?
Someone let in the wolves – it’s feeding time.
Of course, you have to take what I write with a grain of salt. Domestic, refined, mined salt. I’m not as popular as Robert Scoble or Biz Stone, so one can assume that their suggestions work, while my ‘long form diatribe’ won’t do you a bit of good if all you want is to be known.
Or as a friend (someone who I actually like and respect as a person, regardless of how many hits he could send me) says: do what you want, anyway, because we’re all just making this stuff up.
Source: Burningbird: This is Wrong on Oh So Many Levels
I haven't been writing a lot here, but things have been percolating in my head. I've gone through phases of wanting this place to be a bit of a techie zine, I've been in a funk, and lately I've been telling myself that I should blog like no one's watching.
Funny thing is, between those thoughts and my recent activity on a project, I've been posting quite a bit more than I have in a long time. If I were to critique recent posts, I'd beat myself up for being either far too nerdy and obscure, or being inane. Yet, oddly enough, I'd gotten comments and emails that demonstrate obvious interest.
But, it's not a thing to manipulate like search engine listings. When I've written something that I expected to get a lot of comments, it didn't at first. When I posted something that I expected to float by without much comment, it got eight right away. I suppose one could carefully monitor and analyze trendy topics in blogs and try to post only things with high buzz factor, but the best thing is just to write like no one's watching and be pleasantly surprised when you do get attention.
The way I perceive this whole blogosphere working, long term, is for bloggers to read some Joseph Campbell and “Follow Your Bliss”. You could serve the whims of “traffic” for awhile, but if it's not following your bliss, you'll get tired of keeping up. But if you hook into your bliss, there's bound to be traffic-a-plenty coming just to watch you do your own funky breakdance on that piece of cardboard you threw down on your domain name.
Maybe I'm a bit too optimistic about noospheric homesteading, but I expect that the pressures of this space will eventually leave only two kinds of bloggers: the ones who get paid enough, and the ones who have to be here because their bliss won't let them do anything else.
(And I expect the economics to slant in favor of bliss.)
[ ... 864 words ... ]
While the girl does her Calculus and Statistics homework, I'm availing myself of this coffee shop wi-fi to make an initial brain-dump of FeedReactor details into Kwiki:
Installation
Quick Start
Usage profiles
Console feed manipulation
Static blog publishing
Desktop aggregator
Personal server aggregator
Personal dynamic blog publishing
Multi-user dynamic blog publishing
Multi-user aggregator
Architecture
Data model
REST API
Current TODO
Future / Blue Sky
[ ... 71 words ... ]
Wow. So it looks like there are some people starting to follow to what I'm doing with dbagg3, and they're showing me how woefully prepared I am for the attention from tinkerers who are actually trying to, you know, run my code. Things have been crazy busy for me at work, so I haven't been getting done what I've planned. But, I do need to pull a few things together and clean a few things up. I'll soon be answering the smattering of email I've gotten so far, but until then, a few quick thoughts:
My source control is a bit of a mess at the moment. Not only have I switched from CVS to SVN-- but even if you followed me in that migration, I've not kept committed code in working order. I already know that this is a horrible habit, but since no one's really been looking, I haven't been called on it until now. (Heh, heh--d'oh.) Planning this weekend (but hopefully today) to resolve this, so that moving forward, svn trunk will be (as far as possible) in a working state at any given moment.
I've hacked one of my dependencies, SQLObject, by applying a patch to support SELECT DISTINCT queries. This has understandably caused problems for some people who have no idea what I did. This patch has turned out to be essential, though I don't know if/when it will or would be included in a release of SQLObject. So... I wonder if I should dump my working copy of SQLObject into source control? Otherwise, applying the DISTINCT patch to your SQLObject install should work.
At some point very soon, I want to change the name of this thing to feedReactor. Yes, I know there's already a feedparser, and a feeddemon, and a feedburner, and someone's probably got a feedkitchensink in the works, but I like this name and want to run with it.
So, in the meantime while I straighten some things out, please excuse the mess and thanks for bearing with me!
[ ... 433 words ... ]
Got some very good work in this weekend on switching servers and getting dbagg3 in some semblance of working order somewhere other than on my overworked and decidedly non-publicly-demonstrable laptop.
This stuff is so this side of premature, that I'm probably about to cause JohnCompanies to send hit-men out to cancel me, along with my hosting account (have I said that I really appreciate the help so far?). But I just have to get this out: I'm easily excited by shiny code and gadgets, but it's so much easier to get excited when I can see something in working condition before taking a screwdriver to it. So... remember when I mentioned all those URLs? They're working out nicely.
First, check out a simple two-pane view of news items, ala Bloglines:
http://feeds.decafbad.com/api/users/demo.xml?xsl=xsl/two-pane/index.xsl&content-type=text/html
Taking this apart, you can see:
A user account: http://feeds.decafbad.com/api/users/demo.xml
Some XSL: http://feeds.decafbad.com/xsl/two-pane/index.xsl
... and a specified content type (text/html)
If your curiosity is piqued by this, view source and pay attention to link URLs. It's more of the same: XML produced by a REST API, passed through XSL, delivered as HTML.
Here, take a look at another view on this demo user's aggregated items:
http://feeds.decafbad.com/api/users/demo/subscriptions/now-12.xml?xsl=xsl/outliner/index.xsl&content-type=text/html
Unfortunately, this only seems to be working decently with Firefox and Safari. MSIE seems to be balking at the dynamic stuff, though I've had it working there in a previous incarnation of this code. So hopefully this will be fixed soon.
At any rate, what you should see is a single-pane outliner-style display of feed entries. This is the style of aggregator UI I've been using for almost 3 years now. Disclosure triangles open entries up to show summaries and further content. “[seen]” links hide the entries, while “[queue]” hides an entry while tossing it into a queue for viewing later.
Speaking of that, you can see what's in the queue right now:
http://feeds.decafbad.com/api/users/demo/subscriptions/now-12.xml?xsl=xsl/full.xsl&content-type=text/html&show_queued=1
Here is a display of queued entries, with another stylesheet applied that shows everything in a flat and open blog-like template. It's not reverse-chronological, but that's not hard to accomplish with a flag or a tweak to an tag.
So that's just the start of things. Remember when I was rambling on about XML storage and query? A URL like this is one product of that:
http://feeds.decafbad.com/api/users/demo/subscriptions/now-12.xml?xsl=xsl/full.xsl&content-type=text/html&entry_xpath=//entry/title[contains(text(),'OS%20X')]
This should show you a flat listing of all entries whose titles contain “OS X”. This is far from perfect, but it's very exciting to me-- it's got a lot of promise, stuff that first caught my eye when I saw Jon Udell playing awhile back.
Now, something that you might not notice until doing a bit more digging, is that all these attributes like “seen” and “query” are annotations made by the user on entries. If you take a peek at some of the Javascript under the hood, you might notice some XmlHTTPRequest code going on. To mark something as “seen” or “queued”, I POST XML to a URL like this:
http://feeds.decafbad.com/api/users/demo/subscriptions/638/entries/60567/notes/
The upshot of this is that these attributes are not limited to “seen” or “queued” flags-- in fact, these annotations can (well, in theory) be any pairing of arbitrary XML and a name. This annotation then gets injected into the entry, when viewed by the user who owns the annotation, like so:
http://feeds.decafbad.com/api/users/demo/subscriptions/638/entries/60567.xml
In fact, you could invent a new annotation called 'tags' and filter for entries with this annotation with a URL like this:
http://feeds.decafbad.com/api/users/demo/subscriptions/now-12.xml?xsl=xsl/full.xsl&content-type=text/html&entry\_notes\_xpath=//dbagg3:note[@name='tags' and contains(text(),'#food#') and contains(text(),'#odd#')]
Eventually, what I'd really like to see this start doing is something akin to del.icio.us-style tagging while you're reading. Then, you can have public queries that pull feeds based on your (and others') tags and spit things back out as feeds again with the proper XSL stylings.
So at this point, it's all URLs and barely working HTML, but it's exciting to me at least. And it's dogfood for me, since I'm using this crud to get my daily (hourly?) fix. Pretty soon, I'll be diving into wrapping more of a proper usable web app around this, with user management and stuff that works in MSIE. Until then, maybe someone else will see this and catch a buzz from it.
Stay tuned.
[ ... 849 words ... ]
Work has been insanely busy lately, but I have made some more progress with dbagg3. The code is all in CVS, so feel free to take a gander-- I don't have a ton of time for a proper write up, but I do want to spew a little bit.
As per my previous musings on XML in a SQL database, I revamped the database. Now things are sliced up by feed and entry tables, rows in each containing a few metadata columns and then one big column for an XML dump. This lets me index on date and parent feed and such, meanwhile punting on the issue of dicing things like authors or content up further. And, as extension elements start to show up, this handling is dumb enough to simply store things it doesn't know about without mangling them. This is a very good thing and one of my big goals for this beast.
The other thing that I'm getting excited about is the REST API built atop the Atom store. Rather than spend time on proper documentation, here's a quick dump from the appropriate module:
URL: GET /feeds/
URL: GET /feeds/{id}.xml
URL: GET /feeds/{id}/{yyyy}/{mm}/{dd}/{hstart}-{hend}.xml
URL: GET /feeds/{id}/{yyyy}/{mm}/{dd}/{hh}.xml
URL: GET /feeds/{id}/{yyyy}/{mm}/{dd}.xml
URL: GET /feeds/{id}/{yyyy}/{mm}.xml
URL: GET /feeds/{id}/now-{nowoff}.xml
URL: GET /feeds/{fid}/entries/{eid}.xml
URL: GET /users/
URL: GET /users/{uname}.xml
URL: POST /users/
URL: DELETE /users/{uname}.xml
URL: PUT /users/{uname}.xml
URL: GET /users/{uname}/prefs.xml
URL: GET /users/{uname}/prefs/
URL: POST /users/{uname}/prefs/{pname}.{type}
URL: PUT /users/{uname}/prefs/{pname}.{type}
URL: GET /users/{uname}/prefs/{pname}.{type}
URL: DELETE /users/{uname}/prefs/{pname}.{type}
URL: GET /users/{uname}/subscriptions.{type}
URL: GET /users/{uname}/subscriptions/
URL: POST /users/{uname}/subscriptions/
URL: DELETE /users/{uname}/subscriptions/{id}.xml
URL: GET /users/{uname}/subscriptions/{sid}/{yyyy}/{mm}/{dd}/{hstart}-{hend}.xml
URL: GET /users/{uname}/subscriptions/{sid}/{yyyy}/{mm}/{dd}/{hh}.xml
URL: GET /users/{uname}/subscriptions/{sid}/{yyyy}/{mm}/{dd}.xml
URL: GET /users/{uname}/subscriptions/{sid}/{yyyy}/{mm}.xml
URL: GET /users/{uname}/subscriptions/{sid}/now-{hours}.xml
URL: GET /users/{uname}/subscriptions/{sid}/now.xml
URL: GET /users/{uname}/subscriptions/{yyyy}/{mm}/{dd}/{hstart}-{hend}.xml
URL: GET /users/{uname}/subscriptions/{yyyy}/{mm}/{dd}/{hh}.xml
URL: GET /users/{uname}/subscriptions/{yyyy}/{mm}/{dd}.xml
URL: GET /users/{uname}/subscriptions/{yyyy}/{mm}.xml
URL: GET /users/{uname}/subscriptions/now-{hours}.xml
URL: GET /users/{uname}/subscriptions/now.xml
URL: GET /users/{uname}/subscriptions/{sid}/entries/{eid}.xml
Hopefully, the structure of these URL patterns make a little bit of sense. The too-clever thing about these is that they're both documentation in the module's docstrings, and parsed out to register methods with automagically-generated regexes applied to incoming URL requests. (I may eventually realize just how stupid an idea this is, but not yet.)
This list is nowhere near complete or final or even all that well thought out yet. But, it seems to be working out pretty well so far, and it's so easy to tinker with the API to sketch out ideas in working code. Eating my own dogfood, my first browser window of the day tends to open on this URL:
http://localhost/~deusx/dbagg3.5/api/users/default/subscriptions/
now-12.xml?xsl=xsl/full.xsl&content-type=text/html
This grabs the last 12 hours' worth of items from default's subscriptions, passing them through the XSL at xsl/full.xsl on the way to my browser with a content type of text/html. This tends to produce about 1000-1500 entries in about 15 seconds on my PowerBook, which is better than I'd expected.
Pretty soon, I'll be implementing the ability to post metadata onto feed entries under subscriptions. Then, I can mark items as seen, attach categories, tags, and notes. From there, I can exclude seen items from queries, produce new aggregate feeds based on my tagging or notes, among a few other ideas I've got stewing.
A little more work, and I think I'll be able to throw together the beginnings of a Bloglines-style three-pane browser interface, as well as improving the functionality of my own outliner-style display with XmlHTTPRequest-based calls to the API to enable refresh-free interaction. From there, I have some ideas for desktop apps and maybe even some tinkering in Flash. (Wow... has it really been over a year since I was writing about Flash & REST?)
And then, I want to implement the Atom API and allow users to create feeds to which they can post their own items and share read-only with others (or share writing with a group). From there, this thing can turn into a read/write Atom storage tank, serving both as an aggregator and a blog publishing engine, given the appropriate XSL work.
Lots of ideas stewing. Now I just have to get the time and possibly a new web server, since I'd like to eventually open up an installation of this to fellow tinkerers, but this poor little box can barely take what it's tasked with at present...
Oh yeah, and one other thing: I've been thinking about names better than dbagg3. The one that's sticking around in my head so far is feedReactor. What do you think?
[ ... 790 words ... ]
According to calculations, it may cost up to 200% more to develop games for the PS3 or Xbox 2 than it does for current systems.
Source: EA expresses ‘concern’ about next-gen technology
Here's some blogging for you. This article brings two thoughts to mind for me...
First is this: Of course, if you're striving for some semblance of realism in games, the costs will likely approach and exceed the cost to produce movies. It'll approach the cost because, eventually, you'll need either movie-grade animators or real actors. And then it'll exceed the cost, because who wants a game that's as linear as a 2-hour movie? If you want any replay value out of the thing, you're going to have to produce the equivalent of a 4-hour movie at least, if not a 20- to 40-hour movie. And then, you're going to have to be satisfied that many players will miss most of it. Once things reach this point, I think in some sense video games will have arrived as a "successor" to movies, as movies were a "successor" to radio plays.
This brings me to my second thought: Right now, I'm listening to a streaming radio station that's playing old sci-fi and drama radio plays, like X Minus One and The Shadow. These shows are great, and I'm thinking of buying a few box sets of them. These old radio shows get quite a bit of mileage out of their less technologically advanced medium. In contrast to this, my consumption of contemporary and popular television, movies, and music has been dropping off from year to year as I get more tired of supremely well-produced yet worthless content.
Music gets sold on anything but a good tune, movies sold on special effects over plot, and video games head toward technological supremacy over a fun hook or even an engaging story line. But, I don't want anything to do with any of these.
A few days ago, a friend of mine remarked that many "retro" video games were just as horrible as modern video games, but I have to disagree a bit. There were a lot of horrible games. But, for games to be successful back when the dazzle factor of the hardware was low, you needed the fun trick or clever twist that addicted players. The constraints called for ingenuity. Sometimes this meant pushing the hardware, and sometimes this meant coming up with a brilliant yet simple-to-implement idea. (Tetris, I'm looking at you.)
As the hardware platforms progress, we'll see more and more absolutely dazzling demos of the hardware sold as games that completely fail at being fun. But they'll have insane budgets and probably sell very well just because people want to see the pretty sparklies and foobar shaders. The increased capabilities will offer more expressive ability to interactive storytellers, but I bet it will just give even more excuse for game makers to be distracted from that and keep pumping out stories that suck carried by game play that reeks.
It all makes me almost wish for a kink in Moore's Law that stalls the progress of dazzling hardware and forces developers back to being clever with their resources and game ideas. Maybe we'll see more and more of an indie games community rise, producing genuinely fun and amusingly ingenious games. (Gish, I'm looking at you.)
Meanwhile, my girlfriend and I will be playing massive amounts of Magical Drop III.
[ ... 796 words ... ]
One should never think before one posts. That's been my big blunder. And one should never ever ever rewrite, fine-tune, or God forbid edit the post, either. As a blogger, you should form a picture in your mind of a man drinking a cup of coffee. Then imagine that he suddenly feels a dead fly on his tongue and here you'll see your role model. Let your words spew forth with speed and velocity, out of reflex and not reflection. Let them fly without any possibility of ever taking them back. And when challenged, insist that the challenger is lucky that you don't sue somebody, and if he or she thinks you're going to help clean that up, they're crazy.
Source: yellowtext: Oh...Hi! I didn't see you standing there!
Amen, blog brother (with thanks to Quirk Blog for the pointer). I wonder if I need to go on a Month of Blogging, complete with t-shirts, spewing here daily like a sort of NaBlogWriMo?
One should never put blogging on a pedestal, really. I mean, while I do aspire to doing some real writing (when I'm not so busy with work, as I have been of late), my blog-a-day writing shouldn't be all that painful. It looks like my server's on its last legs and the act of posting itself takes forever, so belaboring the actual content so much just puts the last straw on the shaven yak's back.
So, here goes... posty posty post, as they say on LiveJournal. (Well, I seem to remember someone saying that anyway.)
[ ... 279 words ... ]
I've just dumped what code I have into my CVS repository. So, go ahead and poke fun at it:
http://www.decafbad.com/cvs/dbagg3/
Or, fetch it from CVS:
$ cvs -d:pserver:anoncvs@www.decafbad.com:/cvsroot login
(Logging in to anoncvs@www.decafbad.com)
CVS password: anoncvs
$ cvs -d:pserver:anoncvs@www.decafbad.com:/cvsroot co dbagg3
[ ... 42 words ... ]
This is the exciting conclusion of the Wish-of-the-Month Club. Before continuing on, you may want to catch up with parts one and two.
Presenting the Results
Some ready-made files are available for this section:
wishes-ex5.xsl: The fifth iteration of the stylesheet in development.
wishes.html: Sample output in HTML
We've finally gotten together all the bits of information we need--wishlists have been queried; random items have been selected; and a shopping cart has been prepared. Now we just have to present the selections and a link to check out with the shopping cart.
First, locate the following line toward the end of the stylesheet as we left it in the last section:
Delete this, and let's replace it by building some HTML:
Wishlist Shopping Cart\
Here are your wishlist items
items:
We're using the exsl:note-set function again to access the contents of $shopping_cart with an XPath expression. We pluck out the value of the PurchaseUrl in the shopping cart and place it in the variable shopping_cart_purchase_url. Then, after a bit of HTML preamble, we borrow a shopping cart icon from Amazon itself to construct a link to which we can browse later to purchase the selected items. This HTML is very simple so far; it's likely too simple, so eventually you may like to toss some CSS in here to improve the looks of things. But, I'll leave that as an exercise for the reader.
Next, let's build a display of the items selected by iterating first through the wishlists:
This begins a block for each wishlist, starting off with a paragraph containing the label we gave each wishlist. Next, let's include a few details about the product chosen. Again, all of the bits of data included for each product are described in the AWS documentation in the Overview under Amazon Web Services Data Model. Checking that out, we can see that the data includes a URL to images of several sizes representing the product. Let's include the medium-sized image as a link to the product's detail page:
We can also include the product's name as a link:
And, it would be nice to provide a listing of people involved in creating the product (ie. the artists and/or authors):
by
Note that here, the XPath selecting the data is just a bit more involved, since this information can be found in both Artist and Author elements. In another case, we might care to make a distinction, but it really isn't all that important for this project. The data model also provides an indication of from which catalog this product came, as well as its date of release. Let's include that for good measure:
(
-
)
Another thing that would be nice to know is how much this thing costs--we've got this information provided in the XML data as well, so let's include it:
List Price:Our Price:Used Price:
Something to note about these prices, too, is that although the used price is listed, the shopping cart will contain new items from Amazon's shelves. You might want to compare these prices though, and make a change to the shopping cart when you get there, if a used item is acceptable. (Another good reason for manual intervention in our Wish-of-the-Month club.)
Oh yeah, and we should include one other bit of information:
()
This tells us whether or not this item can actually be bought, at present. Although we used this data earlier to try to filter out unavailable items, we should still display this information just in case we missed something.
Finally, let's clean up and finish the HTML:
Running this stylesheet (wishes-ex5.xsl) should give you a page that looks something like this in a browser:
Scheduling Monthly Emails
Some ready-made files are available for this section:
wishes-ex6.xsl: The sixth (and final) iteration of the stylesheet in development.
That HTML we're producing is fine, but what we really want to do is get it delivered to us. We could set up a scheduled run that would periodically generate a page for us to visit, but the whole point of this is laziness. How about firing off an email with this content? There are two things to help us with this: RFC 1521 shows us how to construct email messages with a variety of content types; and sendmail will let us send these messages out. And then, with the help of cron, we can fire up this process every month.
Along with producing XML, XSLT can also construct plain text output--which is just what we need to create MIME email messages. RFC 1521 doesn't make for the most thrilling reading, but there are a few articles to be found that summarize things (such as this article and this article). To make a long story short, a basic shell for an email message using MIME to include an HTML part and a plain text part looks something like this:
To: someone@example.org
Subject: Some useful email subject
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary="theBoundaryString"
--theBoundaryString
Content-Type: text/plain
Some plain text representation goes here...
--theBoundaryString
Content-Type: text/html
Content-Transfer-Encoding: 7bit
Content-Disposition: inline
Content-Base: "http://www.decafbad.com/"
Some HTML representation goes here...
--theBoundaryString--
I've snuck in the idea of providing both an HTML version (which we've already done) and a new plain text version. Depending on your email program and your preferences, one type might be more useful than the other. In any case, it's not all that hard to offer both here. To start sending these email messages, though, we'll need an email address. So, add that as an element in wishes.xml:
deus_x@pobox.com15.000xdecafbad-20D8HVH869XA0NP1QWYI6P2JF3Q535OIOYWQ9XQAE
Let's extract this data into a global variable near the start of the stylesheet:
Start editing the final template of the stylesheet, inserting before the start of HTML content:
To:
Subject: 0xDECAFBAD's Amazon Wish-of-the-Month Club
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary="theBoundaryString"
This is the header for the email. Up until now, we've been generating XML with the stylesheet and haven't cared very much about any extra whitespace or line breaks which might sneak into the output. However, in an email header, whitespace is important since a blank line is what's used to separate the headers from the body of the email message. So, any stray blank lines will cause what we might have meant to be headers to be interpreted as part of the message instead. Producing the first header in the email with xsl:text tags causes the XSL processor to throw away any leading whitespace which would have appeared before the first header.
Other than this little twist, the email header looks pretty much like the shell. We fill in the To address from the global variable $email_to and define a Subject line. The MIME-Version and Content-Type headers are what enable us to include both text and HTML versions in one email.
Now we can start into one of the parts:
--theBoundaryString
Content-Type: text/plain
This begins the plain text section of the email, using the boundary string as defined in the headers to delinieate the section's beginning. The section can also have its own set of headers, of which we use only one: Content-Type. Moving along, let's work on the text content itself.
Here are your wishlist items:
No shopping cart image here, but this includes the human-viewable URL which leads to a shopping cart on Amazon.com. The usage of xsl:text here forces a line break where there otherwise wouldn't have been one with the usage of xsl:value-of. Now, let's iterate through each of the wishlists and list out the product details:
---------------------------------------------------------------------------
---------------------------------------------------------------------------
by
Catalog:
Released:
List Price:
Our Price:
Used Price:
Availability:
Most everything in this stretch should look very similar to the HTML version we just finished. The biggest difference is that every bit of information pulled in using xsl:value-of is done using the disable-output-escaping option. When this is yes, things like ampersands are no longer escaped for valid XML output. Since this bit of the email is plain text, we don't want to see & in album titles, so this will cause ampersands to appear unmolested.
That's the plain text version finished. Now let's create the HTML version:
--theBoundaryString
Content-Type: text/html
Content-Transfer-Encoding: 7bit
Content-Disposition: inline
Content-Base: "http://www.decafbad.com/2004/05/wishes"
The boundary string appears again, signifying the end of the plain text section and the start of the HTML section. Headers appear here which specify that what follows is HTML; that it's encoded in 7-bit characters; that it should be included in the message display itself (rather than presented as an attachment to be saved); and that all relative URLs which might appear in the HTML should be treated as having a base URL as specified. This last part allows HTML in email to refer to images and other pages on another site without making all the URLs absolute.
We don't need to make any modifications to the HTML as we built it in the last iteration of the stylesheet, so we can just include it unchanged:
...
--theBoundaryString--
This final appearance of the boundary string is bracketed on both sides by dashes, which indicates the end of the final section of the document. We should be ready to try this in combination with sendmail in a shell:
$ xsltproc wishes-ex6.xsl wishes.xml | sendmail -it
If everything has worked correctly, there should be an email arriving in your mailbox sometime soon. (Or in my inbox, if you followed the directions literally and didn't supply your own email address.) The options supplied to sendmail are fairly basic:
-i causes lines consisting solely of . not to be treated as an end-of-input signal.
-t causes sendmail to look in the message headers (ie. To:) for a list of recipients.
If you don't happen to have have sendmail available, you might want to look into what local mail programs you have available which can accept the output from the stylesheet.
Once you have this working, the final task is to schedule its monthly execution with your local cron installation. If you haven't played with cron before, there are many resources and tutorials available (here's one and here's another). You should add something like the following to your user account's crontab:
0 0 * 1 * (cd /your/working/path; xsltproc wishes.xsl wishes.xml | sendmail -it)
The "0 0 * 1 *" indicates to cron that this set of commands should be run at midnight on the first of every months. Note also that /your/working/path should be replaced by the path to where you've been working during this project. And finally, I've renamed the final iteration of the stylesheet file to simply wishes.xsl.
Conclusion
So that's it--we have an XSL stylesheet which queries Amazon Web Services for products contained in multiple wishlists; selects a random item from each; prepares a shopping cart containing those items; and finally generates an email message containing both plain text and HTML presentations of the shopping cart and selected items.
Though this implementation serves the purpose I wrote about at the start of this article, there are definitely many areas where this can be improved upon or expanded:
Many people think Amazon is an evil company for their use of patents. I can't say that I'm entirely happy with them for this myself, but their AWS offering is just too nice to resist tinkering with. It might be interesting to investigate other retailers' wishlist offerings, where they exist, and to see how this idea might be made to work with other (or even multiple) retailers. Even better, come up with your own wishlist system, and a cross-retailer shopping cart.
I chose XSLT as the implementation technology because I thought it would be more natural to deal with Amazon's XML this way. There are, admittedly, a few awkward parts in the resulting stylesheet however. Sometimes it's good to see a project like this through, just to get a sense for where things do go awkward with a technology or my understanding of it. It could be interesting to transliterate this into a scripting language like Python or Perl, perhaps using the libxml bindings to do so.
The error and failure handling in this implementation are all but non-existent. Should anything unexpected happen while dealing with Amazon Web Services, the results aren't likely to be very pretty. You may want to consider improving in this area. One instance I identified was to report when the sanity limit was hit in looping through wishlist pages, versus an actual end of pages.
If you play around with making more wishlist queries using the techniques here, you might want to consider caching the full set of data pulled in by the multiple-page calls to AWS, in order to prevent hammering Amazon's servers with repeated requests for the same data, likely unchanged.
I still don't know why exsl:random doesn't work for me. Although I thought using a web service for random numbers was intereting, it would be very nice if I didn't have to use it.
The HTML presentation could certainly use some good CSS to make it more attractive.
Feel free to send me any suggestions, criticisms, or complaints related to this article!
[ ... 2396 words ... ]
Lately, my iTunes has been playing radioio Rock almost exclusively lately, but one thing that peeves me is that I don't seem to see the current song while the stream's playing. Instead, the radioio site offers a pop-up window that displays the last few songs in the playlist. However, I'm usually somewhere off in another window or a shell and don't really feel like popping over to a browser and navigating to the playlist just to see what this song is.
So, I wrote myself a little mini-scraper script:
#!/bin/sh
curl -s 'http://player.radioio.com/player.php?b=614&stream=radioioRock' | \
tidy -asxml --wrap 300 -q -f /dev/null | \
xml sel -t -m "//*[@class='leadrock']" -v '.' -n \
-o ' [http://www.radioio.com' -v '../@href' -o ']' -n
The output looks something like this:
[06/29 11:01:08] deusx@Caffeina2:~ % radioio
Vast - I Need To Say Goodbye
[http://www.radioio.com...]
Cure - The End Of The World
[http://www.radioio.com...]
Seachange - Avs Co 10
[http://www.radioio.com...]
Pixies - Bam Thwok
[http://www.radioio.com...]
Death Cab For Cutie - The New Year
[http://www.radioio.com...]
Lovethugs - Drawing The Curtains
[http://www.radioio.com...]
Oh yeah, and to run this script, you will need these tools:
curl
HTML Tidy
XMLStarlet
Personally, I like the included URLs (which I edited here for length) since they launch a search for CDs by the artist. However, you can cut the output down to just the artist/title by removing the final line of the script and the backslash at the end of the line before.
If you like a different radioio station, say radioio Eclectic, you can change stream=radioioRock to stream=radioioEclectic in the URL above and change class='leadrock' to class='leadeclectic'. I could have parameterized these, but I'm lazy, and that was the whole point!
ShareAndEnjoy!
[ ... 513 words ... ]
Here's the next installment of the Wish-of-the-Month Club. You can revisit the first part, too, if you've missed it. I'd meant to post it within a week of the first part, so apologies all around to anyone who has been tapping a foot waiting for it. Enjoy!
Paging Through Wishes
Some ready-made files are available for this section:
wishes-ex2.xsl: The second iteration of the stylesheet in development.
Now we've got a way to make queries against Amazon Web Services, not entirely unlike what you might be used to if you tinker with MySQL databases on a regular basis. At this point, though, we still have a bit of refining to make to this query. If you take a look at the data produced by the query in its current state, and compare that to what you see on wishlists in your browser, you should notice some things missing.
If you look at my wishlist, you'll notice that items span several pages when visited by browser. As it turns out, AWS queries work in a similar fashion--each query returns only a limited number of items (about 10), and an additional parameter supplied to further queries is required to step through further pages of results. So, using what we've built so far will only get us to the first page of wishlist items; to get all of the items, we'll need a way to step through all of the pages.
In playing with this, I experienced a bit of hairpulling frustration: The AWS documentation, under "Generating Additional Product Results", claims that XML returned by the service will supply a count of the total pages available for a given query. And although I see this element present in other types of searches, the TotalPages element is absent when querying on wishlists. This may be a bug, or it may be an undocumented change in the service--either way, it was a surprise and leaves me with no official way to know how many pages I need to ask for in order to have a complete set of data.
With some further tinkering, though, I figured out a workaround: If a query is made for a page number beyond the final page, the XML returned will be a duplicate of the final page. Once I see a duplicate item appear, I know it's time to stop paging through results. This is completely undocumented behavior, and could break at any time (ie. if Amazon decided to start issuing an error for a page index out of bounds), but it'll work for now.
This calls for reworking the processWishlist template. For a given wishlist, it will need to iterate through a sequence of page numbers, requesting XML from AWS for each, stopping when the first duplicate page is found. Since XSLT is heavily steeped in functional programming concepts, this sort of iteration in XSLT is best done with recursion:
The first modification to this template is the addition of three parameters:
max provides an arbitrary upper limit to the number of pages through which this template will iterate.
curr_page contains the number of the page to be requested in this iteration.
prev_first_asin will contain the ASIN number of the first item from the previous iteration's page of results.
Next, we modify the URL used to query for wishlist data:
The only addition here beyond the previous version is the page parameter in the URL. Not much mystery here--this parameter specifies which page of results we want. Now, let's build the loop:
We capture the ASIN of the first item in this page of results and check to see if we should continue. This if conditional first ensures that we're not past the sanity guard for loop iterations, makes sure that we actually got a non-empty current first ASIN, then checks our current first product's ASIN against what was passed in as the previous iteration's first product's ASIN. If this was the first time through the loop, this value should be empty and therefore wouldn't match the current ASIN. But, if we've gone past the end of results, the previous and current ASIN values should match, and the conditional will fail.
Moving along into the body of the conditional, we copy in wishlist products filtered on a price maximum, just as before:
Having done that, we move onto the recursive end of this template:
Here, the template makes a recursive call back to itself, passing through the wishlist ID and the maximum iteration count. Since variables in XSLT are immutable, meaning that their values can't be changed once they've been set, we can't increment $curr_page in-place like a loop counter in other languages--so, the current page count value is incremented and passed to the recursive call as a parameter. Finally, the current first item's ASIN is passed along, to become the previous ASIN for the next iteration.
Note that when the conditional fails--that is, if the loop limit is passed or a duplicate page is detected--the loop ends. In other words, nothing further happens and execution pops back up out of all the levels of recursion and the top-level template ends.
I wrote "when the conditional fails". This is a key point: for the loop to eventually end, this conditional must fail (or be made to fail) at some point, else this loop will happily progress through page requests forever. This is the reason for the $max parameter limiting the number of iterations, in case something goes haywire--like, oh say, a failure of our duplicate-page detection hack as a loop ending condition. A useful exercise for the reader might be to add some additional diagnostic code to report that the limit was hit versus a natural end to results.
Random Numbers
Some ready-made files are available for this section:
wishes-ex3.xsl: The third iteration of the stylesheet in development.
random-xml: A Perl CGI script used as a web service to generate random numbers.
Armed with a template that will query against the full set of items in a wishlist, we're ready to look into making a random selection from a list of products.
But first, we need to pick a random number. Unfortunately, there doesn't appear to be any random() function in the XPath or XSLT standards. There is a math:random() from EXSLT implemented in libxslt, but I seem to be having a bit of a problem getting it to produce anything other than the same sequence of numbers. I suspect there's a problem in seeding the random number generator, but I've yet to work out how to fix it. (Suggestions welcome.)
So, I cheated and made another workaround with a CGI script on my web server that generates random numbers in a simple XML document. Currently, it's hosted here:
http://www.decafbad.com/2004/05/random-xml
And this is what the script looks like:
#!/usr/bin/perl
use strict;
use CGI;
my $q = new CGI();
my $min = $q->param('min') or 0;
my $max = $q->param('max') or 1;
my $int = $q->param('int');
my $num = $min + ( rand() * ($max - $min));
if ($int) { $num = int($num); }
print $q->header('text/xml');
print "$num\n";
This is a very simple CGI. It accepts the parameters max, min, and int. The values of these parameters determine the maximum and minimum value for the random number returned, and whether or not it should be an integer. For example, the following URL should return an integer between 10 and 20:
http://www.decafbad.com/2004/05/random-xml?
int=1&min=10&max=20
Using this as a web service in the stylesheet with the document() function, we can get a random number. If you've got web space where you can host CGI scripts, I suggest you host a copy of this script yourself, since I can't guarantee how long mine will stick around. But, for as long at works, feel free to use the service from my server.
Moving along, let's add a new named template to the stylesheet, called randomWishlistProduct:
Just like the processWishlist template, we start by defining the parameter wishlist to accept a wishlist ID. Using this ID, we call the processWishlist template itself and store the complete list of products queried from the wishlist into the variable $products.
This next step counts the number of products found in the wishlist. The one tricky bit here is the use of the EXSLT function exsl:node-set(): The $products variable contains what's called a result tree fragment, which is a kind of cross between XML data nodes and a plain old string. This type of data does not normally allow the full set of XPath operators to be used on it, so first we need to use exsl:node-set() to turn it into a full-fledged node set. Then we can look up the Details element nodes and count them.
Here is where the random number service comes in handy. The concat() function is used to build the URL to the service, with parameters specifying that the number should be an integer, and should fall between 1 and the number of products in the wishlist. The document() function grabs the XML document from the service, and the value is extracted from the single element the document contains.
There is an alternative to this last bit, should you happen to have a properly working math:random() function in your XSLT processor:
If you can use this instead, you'll have no need for the random number web service. This version is obviously more concise, and doesn't require another trip out to a web service. You might want to try it--but if you find that you keep getting the same wishlist items selected, then you've run into the problem I found with the random number generator.
Now, let's wrap this template up by selecting an item:
Again, we need to use the exsl:node-set() function to turn the result tree fragment in the $products variable into a node set, from which we select and copy the Details element whose position in the data is indexed by the random number we just selected. Just one last tweak needed to wrap up this iteration of our stylesheet. We need to swap out the call to the processWishlist function at the end and replace it with a call to randomWishlistProduct:
After these changes, you should be able to run the stylesheet ([wishes-ex3.xsl][wishes_ex3]) and get something like the following:
35OIOYWQ9XQAE...1QWYI6P2JF3Q5...
This is similar to the output of the previous iteration of the stylesheet, but this time there's only one product selected at random for each wishlist.
Shopping Carts
Some ready-made files are available for this section:
wishes-ex4.xsl: The fourth iteration of the stylesheet in development.
By this point, we've been able to query and filter products in Amazon wishlists, and we've selected an item at random from each wishlist we've queried. Now, let's enable some purchases.
The AWS provides for Remote Shopping Cart functionality, whereby items can be added to an Amazon.com shopping cart programmatically. This is about as close as we can get to automating the purchase of items selected from the wishlists--there is no API functionality for actually completing the ordering of items. If you really think about it, this really is a good thing and should demand human intervention; we certainly wouldn't want this script going crazy and accidentally buying up everything on a wishlist.
Documentation for the AWS Remote Shopping Cart explains that a shopping cart can be created and items added with a URL like the following:
http://xml.amazon.com/onca/xml3?
ShoppingCart=add&
f=xml&
dev-t=[Developer Token goes here]&
t=[Associates ID goes here]&
Asin.[ASIN goes here]=[quantity goes here]&
sims=true
Part of this should look familiar, so we already know what to do with the developer token and the associates ID. The last part, specifying product ASIN and quantity, can be filled out with information contained in the product records selected at random from the wishlists.
So, let's start by revising the template at the end of the stylesheet:
Here, we've taken what was the output of the previous iteration of the stylesheet and stuffed it into the variable $random_products. Next, let's fill in the blanks and build a Remote Shopping Cart URL:
http://xml.amazon.com/onca/xml3?Asin.=1&ShoppingCart=add&f=xml&dev-t=&t=
Since simple XPath doesn't allow for the looping needed for multiple items, we can't just concatenate this URL together in a select expression like we did with the wishlist item query. So, we use xslt:foreach to build this with blocks of text using the xsl:text element. We iterate though the random products chosen from wishlists and add an ASIN for each to the URL with a quantity of 1. Then, we use the $devtoken and $associate variables to fill in their respective spots.
Note that this could have been written without using the xsl:text elements like so:
http://xml.amazon.
com/onca/xml3?ShoppingCart=add&f=xml&dev-t=&t=
&Asin.=1
&
This removes the clutter of all the xsl:text elements, but it would need to be piled all on one line in order to keep undesired whitespace from getting into the URL. I made a small attempt at wrapping this line here, but line breaks and spaces would leave us with a non-functioning shopping cart URL. It's up to you to decide which to use--personally, I prefer the xsl:text clutter for the ability to add in comments and clarify things a bit.
Finally, having built the shopping cart URL, let's use it to get a shopping cart and wrap things up:
As an aside, this part is pushing the concept of a REST web service a bit: In the REST philosophy, requests using the GET method (which is what document() uses) should only return existing resources and not create new resources or cause modifications to happen. Instead, these sorts of actions should use a POST request. But, since we've already accepted a few rough edges and workarounds in this project so far, we won't let a point of esoterica like that stop us. (That and, well, this is the way Amazon designed their web service, so we'll take what we can get.)
Once you run this iteration of the stylesheet ([wishes-ex4.xsl][wishes_ex4]), you should get something like this XML as output:
...
...............
...
The AWS documentation describes the vital elements here like so:
CartId - The Cart ID is the unique identifier for a given shopping cart.
HMAC - The HMAC is a security token that must be passed back to Amazon Web Services for using an existing cart.
PurchaseUrl - Use the purchase URL to transfer the remote shopping cart from your application to Amazon so that your application's users may complete their purchases. The purchase URL merges the remote shopping cart with the Amazon.com shopping cart.
So, in short, whenever we want to do any sort of manipulation on this Remote Shopping Cart via AWS, we'll need to remember and later supply both the CartId and HMAC found in the XML returned at its creation. And, once we're all ready to check out, the PurchaseUrl points to where we'll need to browse in person.
Stay Tuned!
This concludes Part 2 of the Wish-of-the-Month Club. Following this will be the final part, where we tie everything together and start firing off monthly emails!
[ ... 2721 words ... ]
Remember that I wrote a little while ago about wanting to publish some articles here that I'd want to read? Well, I've been hard at work since then to turn out the first set and I think I've finally got something for you. I mentioned earlier this week that I was taking this seriously, so I hope it shows. So, with many thanks to my girlfriend's kind editorial help, and with some measure of anxiety, here goes...
Introduction
For some time now, my girlfriend and I have been accumulating things we want in wishlists on Amazon.com. Here's mine and here's hers - if you visit them, you can see we've both got quite a few things listed. Though they have come in handy with relatives at Christmas and on birthdays, neither of us really expects to see a regular flow of gifts from them. For the most part, they've just become holding tanks for things we intend to buy for each other or ourselves.
However, I tend to forget we have these lists except for occasional visit to Amazon when I think, "Oh yeah, wishlists. I should pick up a thing or two, there's some good stuff piled up in them." On one particular visit, though, the notion of a Wish-of-the-Month club popped into my head: We could afford to grab at least one item for each of us from our wishlists on a monthly basis, provided that we remembered to place an order. It'd be better than signing up for a book or music club, driven by someone else's idea of what we wanted. Unfortunately, there's that problem for busy, absentminded, and people like us: remembering to place an order.
But wait, isn't this the sort of thing computers are for? I should be able to cobble something together that would peruse our wishlists and--given some criteria like a price maximum--select an item at random for each of us and send them on their way. With this, I could schedule a monthly run and start whittling down those lists.
Gathering Tools
Before I start working through the project itself, let's establish some assumptions and then gather some tools and materials:
I'm going to assume that you're using a UN*X operating system (ie. Linux, Mac OS X, etc.) and that you're reasonably familiar with getting around in a shell and editing files. Things presented here could be adapted for Windows fairly easily, but I'll leave that as an exercise to the reader. Also, you may need to build and install a package or two, so know-how in that regard will serve as well. And finally: some familiarity with XML and XSLT would be useful, but you won't need to be a guru with either.
Oh, and all the files I'll be introducing in this project can be downloaded from my website as a tarball: wishes.tar.gz. If you feel like browsing, you can see these files in my CVS repository. And if you feel like checking out a copy via anonymous CVS, the username is anoncvs and the password is blank--email me for help, if you need it.
So, how do we get a look at these wishlists? Lately, I've been tinkering a bit with scraping information from and automating access to websites. It's a bit like a puzzle game, with all the accompanying frustrations and happy breakthroughs. However, where most puzzle games are designed with a solution in mind, this game isn't even necessarily meant to be played depending on the intentions of website owners.
Fortunately, the folks at Amazon.com have made things very friendly to tinkerers by providing an API, called Amazon Web Services (or AWS). You'll want to download the AWS developer's kit, which contains a wealth of documentation and examples. After downloading these materials, you should apply for a developer's token for use with the service. AWS provides both SOAP and REST interfaces to functionality and data at their site; personally, I prefer the HTTP-and-XML approach taken by the REST interface, so that's what we'll be using here.
To handle the XML produced by AWS, we'll be using the xsltproc command from the XML C parser and toolkit of Gnome. There are other XSLT processors--such as Xalan, Sablotron, and Saxon--but I've found libxslt easiest to feed and care for on the various platforms with which I tinker. It also seems to support a very large swath of EXSLT extensions, all of which come in very handy, yet seem to receive uneven support in other XSLT processors. We'll be pulling a trick or two out of that bag, so its support is key.
You may or may not already have libsxlt installed. Depending on your variant of Linux, it might be as simple as a single package-management command or it might be a bit more complex if you need to compile from source. For Mac OS X, I recommend using Fink for your packaging needs. Although, DarwinPorts is nice as well, if you're used to The BSD Way.
A bonus for OS X users: Marc Liyanage has provided a great Open Source tool named TestXSLT that embeds libxslt, among other XSLT processors, in a slick GUI for easier use. This might come in handy for you as things develop.
Wishlists in XML
Okay, we've got a working environment, a head start on accessing Amazon wishlists as XML, and a way to manipulate that XML using xsltproc. Let's start playing. First things first, we need to gain access to Amazon wishlists in XML form. Reading through the AWS documentation reveals that wish list searches are available via a URL constructed like so:
http://xml.amazon.com/onca/xml3?
t=[Associates ID goes here]&
dev-t=[Developer Token goes here]&
WishlistSearch=[wishlist ID goes here]&
type=[lite or heavy]&
f=xml
I received an ID of 0xdecafbad-20 when I signed up to be an associate a few years ago. This will ensure that I get credited for sales made via the API--which isn't as important for the present project, since I'll be buying items myself, but it'll come in handy in later projects. Also, when I signed up for a developer's token, this is what I was given: D8HVH869XA0NP I'm disclosing my own here for the sake of example, but you should sign up and get your own.
So, that fills in the first two parts of the URL. For the purposes of this project, let's just go with the lite option for type. As for the wishlist ID, let's take a look the wishlist URLs to which I linked earlier:
http://www.amazon.com/exec/obidos/registry/35OIOYWQ9XQAE
http://www.amazon.com/exec/obidos/registry/1QWYI6P2JF3Q5
You can discover these wishlist URLs using Amazon's Wish List Search feature, in which case a wishlist URL might appear like so:
http://www.amazon.com/gp/registry/registry.html/
002-7899886-3676027?%5Fencoding=UTF8&
id=35OIOYWQ9XQAE
In either case, there is a 13-character ID in each variety of wish list URL: this string is the wish list ID. So, the ID for my girlfriend's wishlist is 35OIOYWQ9XQAE and mine is 1QWYI6P2JF3Q5. Given this piece of the puzzle, we can fill in the blanks to come up with the following URL for my girlfriend's wish list:
http://xml.amazon.com/onca/xml3?
t=0xdecafbad-20&
dev-t=D8HVH869XA0NP&
type=lite&
WishlistSearch=35OIOYWQ9XQAE&
f=xml
Check out the XML resulting from this URL--you may want to use a tool such as curl or wget instead of viewing this directly in your browser. You'll see some XML that looks something like this:
...
0262133601Foundations of Statistical Natural Language ProcessingBookChristopher D. ManningHinrich Schütze18 June, 1999MIT Press(another long url)(yet another long url)(one last long url)Usually ships within 24 hours$75.00$63.75$49.99
...
Note that the long URL in the Detail element's url attribute links to the human-viewable product detail page at Amazon. I've also left a few other things out, such as the URLs to product images; I just thought I'd edit it a bit to be friendlier to your browser at home. There's a schema for this XML data, and the ins-and-outs are explained in the AWS documentation under "Amazon Web Services Data Model".
Querying The Wishes
Some ready-made files are available for this section:
wishes-ex1.xsl: The first iteration of the stylesheet in development.
wishes.xml: An XML document used as input with the stylesheet.
Now that we've got some XML from Amazon to play with, let's start tinkering with an XSLT stylesheet to process it. In the interests of flexibility and reusability, we can parameterize a few things in XML before starting in on the stylesheet:
15.000xdecafbad-20D8HVH869XA0NPdeus_x@pobox.com35OIOYWQ9XQAE1QWYI6P2JF3Q5
Hopefully, the data here is fairly self-explanatory: I've established a maximum price for item selection; provided my associate ID and developer token; there's an email address to which I eventually want to send the results of all this work; and I've made a list of wishlist IDs, each with a readable label. Given this, let's start out simple and use this to get some data from Amazon:
So far so good--things start off by pulling in some of the parameters into variables. Next, let's dig into actually querying wishlist data with a reusable template:
First thing into this template, we accept a parameter named wishlist which is expected to contain a wishlist ID string. Next, we build an AWS URL by concatenating together the pieces we have in variables (associate ID, developer's token, and wishlist ID) using the XPath function concat(). Once we have this URL, we use the function document() to make a request and fetch the XML data for that URL. From this, we select all the Details elements.
Then with that data, we can do some filtering on the price and availability. We want to make sure that not only will we select items that are within our budget, but that they are available to buy in the first place:
This code is just a little bit funky, since the price data given by Amazon contains a dollar sign, and we want to make a numerical comparison. So, we chop the dollar sign off and convert to a number before making the comparison. Also, there's an assumption here about what will show up in the Availability element: "Usually ships within" Other things that might show up will declare that the item is out of stock, discontinued, or otherwise not shipping. This might need some tweaking someday, but it seems to work for now.
Taken all together, this template has the effect of a SQL SELECT statement somewhat like this:
SELECT *
FROM Amazon.WishlistItems
WHERE WishlistID = $wishlist AND
OurPrice < $maxprice AND
Availability like '%Usually ships within%';
document() is a very useful XPath function. It allows us to pull in XML from external files and, in our case, from external URLs via HTTP requests. This gives us the ability to make queries against REST web services like AWS--which, among many other reasons, is why I prefer REST web services over SOAP. (I don't even want to think about trying to access a SOAP service from XSLT.)
Now, let's wrap up this first iteration of the stylesheet by trying out the query template on each of the wishlist IDs:
You can get a completed version of this stylesheet, along with the input XML, in case you haven't been cutting and pasting together a copy of your own along the way. Try it out in a shell with:
$ xsltproc wishes_ex1.xsl wishes.xml
Alternately, you could check it out using TestXSLT under OS X. You should get something like the following:
35OIOYWQ9XQAE......
...
1QWYI6P2JF3Q5......
...
Obviously, this example XML is much abridged, but hopefully you can get the gist: For each wishlist ID, there is a containing wishitem element. It contains a copy of the wishlist element from the input XML, followed by all the Details elements filtered and copied from the Amazon XML with the help of the processWishlist template.
That's All for Now!
And that's the end of Part 1. Next up, we'll be delving into a few more wrinkles in the wishlist querying process, selecting random items in XSLT, and the Remote Shopping Cart interface in Amazon Web Services. Stay tuned!
[ ... 2207 words ... ]
WebKit is so insanely easy to use that I'm amazed every OS X application doesn't do it somewhere, just for the fun of it. Maybe they do.
Source:The Fishbowl: A Confluence GUI Client in 200 Lines of Code
A new major feature of Colloquy 2 are the extensible conversation styles. Styles are simple OS X bundles wraped around a CSS file (at minimum) or a CSS file and a XSL file. Knowing this, the fact that Colloquy uses XML to store chat messages that come in over the network is no surprise to some. Pairing these three technologies gives us great flexibility when processing and displaying a message on screen.
The process of formatting a message follows these steps, start to finish. First, wrap the message in a simple XML envelope, encoding any special characters and representing IRC styling as XHTML. This XML envelope gets transformed with the curent style's XSL file (or a built-in default XSL file). The resulting transformation from the XSL on the XML should be XHTML that can then be rendered with help from the style's CSS file. Rendering is done via Apple's Safari (WebKit) engine -- so the possibilities are endless (evidenced by the built-in iChat like Bubbles style).
Source:Colloquy: Developers
Colloquy is an IRC client for OS X that I just discovered this week,
via an article posted on MacSlash.
I've been looking for a decent Cocoa-based app as an alternative
to my use of X-Chat Aqua,
Conversation, and
irssi. Having never heard of Colloquy before,
I figured I'd check it out.
Colloquy is a Cocoa app, and the source is available. It's the first OS X
IRC client I've played with yet that most resembles what I expect out of a modern
Cocoa app. Conversation is right there, too, but I don't see any source (no
offence to the author) and it doesn't yet support multiple servers or AppleScript
(although those are on the planned features list).
Beyond all that, though, what has sucked me into Colloquy is the way IRC messages are
presented and styled. In case the introductory quotes haven't given you the idea, this
thing pipelines XML, XSL, CSS, HTML, Javascript, and WebKit to provide
an immensely flexible user-customizable, modular display style system.
There aren't that many styles yet, but conceivably anything one could
do with the pile of technologies above can be employed in presenting IRC
messages.
Yes, you could make the case that this is an insane example of overkill.
If so, Conversation or a shell-based program is likely more your speed.
Admittedly, Colloquy is not a featherweight IRC client.
But I've been thinking about this sort of inversion of web tech for awhile.
Instead of the browser hosting the app, the app hosts the browser. I've been
doing a ton of tinkery UI work with HTML and JavaScript in my
news aggregator and have come
to appreciate the DOM and various things JavaScript makes possible in modern
browsers.
This has lately lead me to consider how a browser canvas
could be used as a sort of universal widget inside a native app... not at
all unlike the way Colloquy uses it. Apple's WebKit encapsulation makes it
just about dead simple
to drop it into an app and integrate it. In fact,
from a shallow glance at the docs for WebKit, it seems even simpler to use than
some other GUI widgets in the Cocoa arsenal.
So... is this the start of more Cocoa apps embedding WebKit views, "just for the
fun of it"? Who knows, but it really appeals to my propensity for mixing and
matching different tech within the same project. I suppose it's a sort of sick
addiction I've picked up from the Tower of Babel web development I've been doing
for years, but it looks like fun to me!
[ ... 830 words ... ]
I've just read Mark Pilgrim's post, "The infinite hotel", which I'm sure I'll need to re-read a few times and chase down references to read. Also I'm reading Gödel, Escher, Bach again for the third time, since I first read it in high school and needed corks in my ears to prevent brain slurry from spilling out. I really need to read more of this sort of thing, refresh myself on all the math I took in college, and explore some of this really abstract stuff.
Something I've been musing about lately, without any real novel ideas or insights, is about the history of computation and these thinking machines. Not history in terms of events and when, but in terms of the concepts and discoveries leading up to keyboards, screens, and code today. Thinking about things like recursion, and sets, and logic, and all the patterns and revolutions in thought that are the basis for everyday business and life today.
I've been trying to imagine the world in each moment where each of these things were new, when these things were worked out in minds and on paper. When there were no computational engines available to carry out calculations or work out conclusions to logical constructions.
Today, these discoveries are crystallized in computing architectures, and so geeks hack and play and learn by example. The construction of the CPU is objective fact, independent of subjective thought or understanding, and the behavior of code demonstrates the laws and rules. Before, the rules were carefully reasoned out and intuited from observations on the objective universe, but now they're assimilated by example from mechanically working artifacts.
I'm not sure I'm expressing this very well, or if my thoughts are very well formed altogether, but I'm trying to imagine mental life without readily available, objectively existing computational artifacts with which we can play, without prohibitive investments of effort or time. No scripting languages with which to just try out logical constructions. No calculators with which to solve formulae. All manual, all by hand, all worked out by careful thought and precision. I'm trying to imagine what geeks like me, as I am today, would be like at a time when everyone dealing in these things was an abstraction astronaut, and there was not really a such thing as that-which-just-works or worse-is-better. Does this make any sense?
Again, this is not really an expression of anything coherent or novel. This is mostly me just in awe of how we got here, and trying to get myself above the mode of being just a hacker chasing down the phylogeny of all that's come before, and into some meta-mode of understanding of the things behind what makes these thinking machines and the thinking itself work. Maybe after a few more decades of this I'll have some thoughts worth sharing synthesized from all that I've learned.
[ ... 788 words ... ]
The problem with varying the polling interval is that the need varies. It's ok not to poll my little opensource website within 24 hours, but what about the announcements to the civil defence website or local municipal environment alerts, or the nuclear power plant news feed?
Source:Comments on The End of RSS
Definitely a good point there. For most of the feeds in my daily habit, what I use is an AIMD variation on my polling frequency per feed based on occurrence of new items. For feeds with low-frequency but high-urgency items, a different algorithm should come into play.
On the other hand... should incoming alerts with that much urgency really be conveyed via an architecture driven by polling? Here's an excellent case for tying instant messaging systems and pub/sub into the works.
[ ... 155 words ... ]
In case anyone is interested in using del.icio.us with blosxom in place of my own BookmarkBlogger, get yourself a copy of xmlstarlet and check out this shell script:
#!/bin/bash
DATE=${1-date +%Y-%m-%d}
BLOG="/Users/deusx/desktop/decafbad-entries/links"
FN="${BLOG}/"echo ${DATE} | sed -e 'y/0123456789-/oabcdefghij/'".txt"
touch -d "${DATE} 23:59" ${FN}
You could do this with XSLT, but hacking with a REST-ish & XML producing web service entirely in a shell script seemed oddly appealing to me that week. Extending this sort of thing to blogging systems other than blosxom is left as an exercise to the reader.
Update: Hmm, looks like one of the blosxom plugins I'm using hates the variables in my code above. So I stuck curly braces in, which seem to get through okay.
[ ... 244 words ... ]
You wanted to share the same documents with your coworkers and friends. Now you can.
With VoodooPad 1.1, you can view, edit, and save to any wiki that supports the 'vpwiki api'.
Source:Flying Meat Software
Funny, I’ve been tinkering with a wiki API along with a few others tinkerers for a year or so now. I wonder if we could get these APIs merged or synched and give VoodooPad access to a slew of wikiware?
Every once in a while, someone gets ideas about crossing recipes and computers. Of course, I love the idea. Two common ideas we hear a lot are 1) to put recipes in XML format and do all sorts of wonderful things and 2) that kitchen appliances should be smart and you should be able to feed them recipes and have your food made for you. They're both great ideas, but invariably, people underestimate the work involved ("But it's just a recipe!") and overestimate the usefulness ("It would be so cool!").
Source:Troy & Gay
Here’s a good response from someone who knows what he’s talking about when it comes to recipes on the web—he’s one of the contributors to the aforementioned RecipeML format and is part of the team responsible for Recipezaar . While I think that recipes as syndicated microcontent could be a good thing, Troy makes some important points here.
[ ... 152 words ... ]
RecipeML is a format for representing recipes on computer. It is written in the increasingly popularExtensible Markup Language - XML.
If you run a recipe web site, or are creating a software program -- on any platform -- that works with recipes, then you should consider using RecipeML for coding your recipes! See the FAQs and the new examples for more info.
Source:RecipeML - Format for Online Recipes
So I'm all about this microcontent thing, thinking recently about recipes since reading Marc Canter's post about them. Actually, I've been thinking about them for a couple of years now, since I'd really like to start cooking some decent meals with the web's help. Oh yeah, and I'm a geek, so tinkering with some data would be fun too.
One thing I rarely notice mentioned when ideas like this come up is pre-existing work. Like RecipeML or even the non-XML MealMaster format. Both of these have been around for quite a long time, especially so in the case of MealMaster. In fact, if someone wanted to bootstrap a collection of recipes, you can find a ton (150,000) of MealMaster recipes as well as a smaller archive (10,000) of RecipeML files. Of course, I'm not sure about the copyright situation with any of these, but it's a start anyway.
But, the real strength in a recipe web would come from cooking bloggers. Supply them with tools to generate RecipeML, post them on a blog server, and index them in an RSS feed. Then, geeks get to work building the recipe aggregators. Hell, I'm thinking I might even give this a shot. Since I'd really like to play with some RDF concepts, maybe I'll write some adaptors to munge RecipeML and MealMaster into RDF recipe data. Cross that with FOAF and other RDF whackyness, and build an empire of recipe data.
The thing I wonder, though, is why hasn't anyone done this already? And why hasn't anyone really mentioned much about what's out there already like RecipeML and MealMaster? It seems like the perfect time to add this into the blogosphere.
[ ... 1292 words ... ]
What I believe we are seeing is domain experts seeking each other out. Crossing organizational and philosophical boundaries.
Source:Sam Ruby: Whuffie Web
...someone that's G-list globally might be A-list amongst pet owners.
Source:Danny Ayers: Whuffie Web
A very, very good point that I'd missed at first thought about the Whuffie Web. There's a matter of scale involved here, where the relative A's through Z's are completely different given your choice of grouping. And, where choice of grouping is around topic area, the world's a bit of a smaller place and getting your questions answered is likely much easier. Especially if you've built up some Whuffie in that domain area by generating some useful answers and knowledge yourself. For newcomers to a domain of knowledge, who have lesser stockpiles of Whuffie, they'll hopefully be fortunate enough to find much of what they're looking for chronicled in the archives of blogs of those who've come before. When they don't, though, it can still be a frustrating experience.
But, semantic web tech in and of itself doesn't solve the problem where data or knowledge is missing altogether. How could it? So, although I was a bit dismissive at first thought about what Dave Winer wrote, he nonetheless has a good point. Even if the semantic web were richly populated with data and running in full swing, it would still be missing large swaths of Things People Know. And, well, the thing to use in that case is-- wait for it-- People Who Know Things. And the way you hopefully can get to them is by being nice and interesting, then blog the answers or ask the people answering your query to blog it themselves. Then, hopefully, we have blogging tools which can do the bits of pre-digestion to allow that knowledge to be accessed via semantic web machinery to fill in the gaps.
This all takes me back to when I first encountered Usenet in my Freshman year of college, and became instantly enamoured with FAQs. It seemed like there was a FAQ for everything: coffee, anime, meditation, Baha'i faith, Objectivism, and hedgehogs. It seems mighty naive to me now, but at the time, I so thought that this was the modern knowledge factory. Through the contentious and anal bickerings of discussion threads on Usenet, and the subsequent meticulous maintenance of FAQ files, every trivial bit about everything within the sphere of human concerns would be documented and verified and available for perusal by interested parties. Netiquette demanded that one pour over the FAQs before entering the conversational fray, so the same ground wouldn't be endlessly rehashed. Approval from one's peers in the group came from generating new and novel things to add to the FAQ, and all were happy.
This, of course, summarizes thoughts coming from a Freshman compsci student getting his first relatively unfettered access to the internet, gushing about everything. On the other hand, I have many of the above enthusiasms for the Semantic Web's promises. In a few years, I expect that my enthusiasm will be more even, yet at the same time, I expect there still to be some real uses and benefits to this stuff stabilizing out of it all. Hopefully, it doesn't get obliterated by spam before then, like Usenet, like email, and now (but hopefully not) in-blog discussions.
[ ... 554 words ... ]
I see that Mark Pilgrim has posted a picture of himself as a kid, working at an Apple //e. Based on what I wrote this past Summer about being Newly Digital in 1983, I would guess that around the same time I was working on a Commodore 64, and I would have teased him in a relentlessly geeky way about his clearly inferior machine.
[ ... 65 words ... ]
Let's do a demo of the Semantic Web, the real one, the one that exists today. Doc Searls has a question about the iQue 3600 hand-held GPS. It is sexy. They say it only works with Windows, but Doc thinks it probably works with Linux too. A couple of thousand really smart people will read this. I'm sure one of them knows the answer. Probably more than one. There's the query. Human intelligence is so under-rated by computer researchers, but when we do our job well, that's what we facilitate. Human minds communicating with other human minds. What could be easier to understand?
Source:Scripting News
Well, I certainly wouldn't call this the Semantic Web-- more like the Whuffie Web. See, if we were all A-List bloggers, with our own constellations of readers willing to pitch in to answer a question, we could all make queries like the above. A-List bloggers have the big Whuffie. Most everyone else has much less Whuffie, thus their query powers are much less. I somehow doubt that the Whuffie Web, if it were to take off in a big way, would work to equal benefit for everyone. A cousin, the Lazyweb, sometime serves its petitioners well, but it's a fickle and unpredictable thing indeed. Sometimes you get magic, sometimes you get shrugs. This also links into the Whuffie Web, in that Lazyweb contributors will be more likely to service a request if it comes from a Big Time Blogger. It's all about the Whuffie exchange.
On the other hand, if this Semantic Web thing were to take off, it'd benefit anyone who could lay hands on the connectivity to acquire the data, and the CPU power to churn through it. The data itself could come from anyone with the connectivity to provide the data, and the brain power to create and assemble it from information and knowledge. No underestimation of human intelligence here. If anything, it's an attempt to better respect the exercise human intelligence, to conserve it, and make it more available. Were the Semantic Web to take off in a big and easy to use way, people could spend more time creating answers and less time answering questions, since the machines do the job of fielding the questions themselves.
Of course... without the Whuffie, where's the motivation to provide the data?
[ ... 587 words ... ]
The RVW specification is a module extension to the RSS 2.0 syndication format. RVW is intended to allow machine-readable reviews to be integrated into an RSS feed, thus allowing reviews to be automatically compiled from distributed sources. In other words, you can write book, restaurant, movie, product, etc. reviews inside your own website, while allowing them to be used by Amazon or other review aggregators.
Source:Blogware Implements Distributed Reviews
Aww, yeah. Bring on the microcontent. Yay, hooray! This is an XML namespace-based extension to RSS 2.0, and for even more flavor, it uses the work of other pre-existing specs, such as ENT, FOAF, and Dublin Core. This wouldn't be hard at all to slip into an RSS 1.0 feed and an RDF database as well.
[ ... 126 words ... ]
Oh yeah, and, just noticed this upon arriving at work. In the past 6 months, forgotten mounted shares and the subsequent filesystem-related lockups and beach-ball-spinnings in Jaguar have been my sole reason for reboot.
As it would happen, I forgot to disconnect from shares on my home LAN again, and awoke my PowerBook on the work LAN. Before Panther, this would have lead to a reboot within 10 minutes. This time, it did the Right Thing. Yay hooray!
Oh, and the Grab application works for individual windows now-- something which seemed to always be greyed out before.
[ ... 98 words ... ]
I know I'm late to the blogosphere release party for Panther, but I just got it last night and, biting the bullet, installed it with only minimal effort toward backing things up. I intend to eventually wipe this PowerBook completely and install fresh, but I couldn't wait. :)
Mark Pilgrim published the most definitive coverage of the beastie I've seen yet, with help of the denizens of #joiito to manage the onslaught of readers. So, I won't make any attempt to catalog the new things.
A few impressions though:
Everything feels faster. Windows slide around and resize like they've been waxed underneath. Things seem to launch faster.
A few small things have improved, like System Preferences quitting when I close the window, rather than hanging around waiting for me to open the window again or quit.
Some third-party extension I had installed threw Finder into a launch-and-crash loop for awhile. So, if you've yet to install, try to purge your system of extensions first. This should be obvious, but is sometimes a surprise when it's actually a problem.
Expose looked like a neat feature when I first heard of it. I fully expected it to be slow, stuttery, and 'cute' when I finally played with it. Now, having used it and slowly incorporating it into my usage habits, it's amazing. Smooth and not stuttery at all, it looks like a computer interface feature from the movies.
Fast user switching, where desktops rotate in and out of view, also looks like you wish it would, and seems like it's from the movies.
I hate metal.
I hate metal.
I hate metal.
That is all. For now. Maybe.
[ ... 277 words ... ]
After playing with an N-Gage, I think sidetalkin.com is freakin' hillarious. One thought on this sidetalking thing, though:
At least it keeps the screen from getting all schmutzed. My Treo 300 screen gets absolutely filthy, due to me pressing the slab up against my head to talk. Also, there seems to be a defect in the LCD developing, which seems to have something to do with, again, being pressed up against my face.
In most other ways, this thing looks to be a flop... but the sidetalking thing might just not be such a bad idea.
[ ... 97 words ... ]
For the past year or two, I've been trying an experiment in my
personal research and learning. I've been seeking out tools and
technologies which are as different as possible from those with which
I already have experience. I want to break up some prejudices and
habits I have, and expose myself to more ways of looking at things.
Now that I write this, it sounds like a great approach to life in
general, but for now I'm focusing on computer science. :)
My success
with this has been entirely dependant on free time and brain cycles,
of which I've had precious little. But, I have managed to wean myself
away from Perl to learning Python, developing a few apps with it and
incorporating it into my problem solving kit. I've also managed to
get myself away from XEmacs for hours at a time in order to weave Vim
into my work-a-day life. These two things haven't been easy for me,
since I've been using both Perl and some variant of Emacs for almost
12 years now, and I've done my share of sneering at that which is not
perl or emacs.
And, although I've yet to spring upon them, I've also been making wary,
narrowing circles around Lisp, Smalltalk, Prolog, and .NET. There
been occasional forays into Java, as well as my daily attachment to
Flash and Actionscript lately. And then, there've been my hefting and
swinging of XSLT and XPath, as well as RDF, countered by a few feints
with plaintext shell tools and YAML. There's been more, but most
investigations have been too tentative to mention.
If there's a "holy war" between two things, I want to explore them both.
I tend to see two apparently intelligent parties in an extended debate
over which of them has a hold on the One True Way. In my
experience, though, there's a high likelyhood that such a phenomenon
points toward a real truth which lies somewhere inbetween. (This, of
course, ignoring such cases where one party is correct, and the other
is WRONG, WRONG, WRONG!) There tend to be very good reasons why smart
people on either side of a fence have taken up with what they have,
and I want to know both sides thoroughly. I know full well that both
sides have at least some valid criticisms against the other, but I
want a synthesis of the two.
In this field of computer science, there
are as many ways of working with the dreamstuff as there
are ways of structuring thoughts. And, rather than there ever being
One True Way to do things, there will always be another smart person
developing another powerfully expressive and insightful way of doing
things. Someday, I'd like to be one of those smart people, so I need
to have a sense for that truth in the middle that other One True Ways
bracket and zero in on. And then, I want to know enough to jump out
of the frame altogether, and in which ways I can invert and twist
things to encircle some new spark.
Someday in the next few years, I'd like to get back into school so I
can get to even higher levels of growing up to be a computer scientist.
But for now, it's back to work for me. And, if you happen to think of
any geeky holy wars, let me know. I'm collecting them for study.
[ ... 1111 words ... ]
I agree with Derek Balling [who criticized Foo Camp], and when you come back to earth, I bet you will too Jeremy.
Did I read that you guys had meetings about RSS? At a private invitation-only event? Do you realize how WRONG that is?
Source:Dave Winer in a comment on "Some Foo Camp Links"
One of the sessions on Sunday morning at FOO Camp was a brainstorming session on how a site could provide a list of feeds.
...A working name for this effort is "FDML". The stands for Feed (Discovery / Directory / Detailing) Markup Language, depending on who you ask. ;-)
Source:Sam Ruby: FDML
Just so it is absolutely clear: all I have done is listed a set of requirements, many if not most of which are directly from Jeremy himself. The acronym was suggested by David Sifry.
People are welcome to question, refine, or add to the requirements, or present proposals on how these requirements can best be implemented. Perhaps even with OPML.
Source:A later comment on Sam Ruby: FDML
For anyone who wonders why people talk about politics and animosity in
the tiny sphere of web syndication tech, here's a case in point.
You see, there was a private event over the weekend, called Foo Camp.
To this, many smart people were invited, and many more weren't.
Grousing about invitations, funding, and elitism aside, it sounded
like a great time and a cool change from your average conference. I
hope it turns into a regular event, and hope that someday I'm given
the opportunity to go to something like it. I'm sure a lot of us
out here would like to make it to something like that.
But, for what it was, you can only gather so many people before it
becomes a circus (or a conference). Charging a price serves as a
limiter, while making the event invitation-only works as well. The
difference is whether you're bringing in people who can afford it
versus people who are favored by the organizer. Either way, someone's
going to be pissed about not going. The difference is whether you're
pissed off at the organizer's economics or the organizer's
personality. Oh well.
So anyway, around mid-September, Jeremy Zawodny had floated
an idea
involving publishing and discovery of lists of RSS feeds.
He was one of those invited to Foo Camp, and in one of their
huddles, he brought the idea up for a brainstorming session.
From the sounds of it, they tossed around a few ideas, but
didn't really come up with much other than that it was an idea
worth discussing.
No sooner than the camp breaks up, though, and the angry buzz
has already started. How dare a bunch of geeks talk about
technology they're interested in while at a private gathering?
How dare they not invite all of us? Conspiracy! Elitism!
They didn't pick me for their kickball team! By the way,
this isn't an attempt to put words in mouths. This is my
off-the-cuff impression of what I read yesterday. It all
seems repeatedly and unnecessarily childish to me, and it's
certainly not limited to one person.
So, by today, there's already
a wiki
devoted to exploring this idea, along with a scattering of blog
posts. This seems pretty speedy to me,
considering campers returning to the work-a-day world after
a geek retreat. This doesn't seem at all the work of a sinister
cabal bent on wresting control and domination over a technology,
as what I saw implied in the first comment I quoted above.
Dave Winer's already posted a
first proposal
toward implementing the idea. And, believe it or not, as Sam comments
on above, this approach has not been ruled out. In fact,
Jeremy had suggested using OPML in his original posting of the idea.
Why couldn't we just have seen the collaboration without the
antagonism, in at least this case? Yeah, there was a small, private
gathering at which discussions were had. Sounds like what happens at
work, or with friends, or in classes. Granted, I suppose an argument
could be made concerning the relative openness of these gatherings as
compared to Foo Camp. But, this is mooted by the fact that the
people involved were already moving toward sharing the discussion.
For all the grousing about flame wars and personality clashes on
mailing lists and working groups, sometimes it's nice to work on an
idea in a smaller group with a good dynamic. It helps to get
something together before throwing the doors open to have the thing
buffeted by opinions and criticism from all sides. It's one way to
avoid "stop
energy" while trying to build some momentum.
As Dave himself wrote, "I heard at a working group meeting that things
like SOAP can only happen when no one is paying attention." So, it
sounds like a bunch of geeks tried to get something rolling before the
attentional heat lamps turned on it. Had they wanted to be a sinister
cabal, we certainly wouldn't have heard about any of this until long,
long after the event. It would have been kept behind closed corporate
doors until the day of embrace-and-extend. Then, profit! As it is, I
think they erred on the side of throwing open the discussion
too early.
So anyway, the reason I write at such length about this is that I
don't think that this should be let to pass without comment or
consideration. This kind of thing is what's wrong. We need to take
at least three deep breaths before reacting like this, whether
or not we've taken 900 beep breaths in the past already. It's the
nature of these things. As an interested but outside observer, the
atmosphere created by such reactions makes me very sad. And it's not
just one person doing this, either.
So, chill out. It's just data. In fact, the proposal at question
here is just a friggen outline of feeds! It's just a list of
lists! Most of the geeks out there just want to play, and are happy
to have more geeks to play with. Can't we just get along and play the
game together, rather than gaming each other?
[ ... 1116 words ... ]
In response to the opposition to RSS-Data,
Marc asks,
"Where are the Reviews, Resumes, Recipes, Topics and other cool new
forms of micro-content?"
Well, I did a bit of Googling this morning, and this is what I found:
On the subject of reviews, A.M. Kuchling
has provided an
RDF namespace
for embedding book review metadata within XHTML documents.
For resumes,
Uldis Bojars
has been working on an
RDF schema for resumes and CV.
To offer up recipes, I found
this RDF schema
for recipes hosted on
donnafales.com.
As for topics, well, there's already a straight RSS 2.0 namespace
extension called Easy News Topics.
And, finally, for events there is
mod_event,
and RSS 1.0 module used for presenting calendar event information.
Yes, with the exception of ENT, these are RDF schema or namespaces.
But, any one of them could likely be adapted to straight XML and used as an RSS 2.0
namespace, thereby leveraging the work these people have already done
in modeling these kinds of content, as well as potentially providing
an easy transformation path to RDF for those who care.
What does RSS-Data provide out of the box which makes any of the
above obsolete? There's no magic here, other than translating between
raw data sctructures. You'll still need to do the same sort of
modeling and structure work that the authors of all the above have
done. It's always nicer to have someone else do homework for you.
So, if all this new microcontent is so hot, why hasn't anything like
the above been put into use? Would adding 5 new tags to an RSS
feed really be an insane burden to express calendar events? Granted,
some of the other examples above are more complex, but then so are
the things they seek to represent.
What's the RSS-Data magic that improves on all the above?
[ ... 776 words ... ]
I'll be at the Enterprise Architect Summit in Palm Springs next week,
on a couple of panels. One's entitled Schemas in the wild: XML takes
on the vertical industries, and the panelists are Jon Bosak and Jean
Paoli. The single most important question I'd like to ask these guys
is: how do we strike the proper balance between freedom and control?
By freedom I mean incremental and iterative evolution of data
structures in response to patterns of real-world use. By control I
mean the predictable regularity enforced by a DTD or XSD.
Source:Jon Udell's weblog, XML vocabularies: freedom and control
For quite awhile now, Jon Udell's been asking the same
sorts of questions as I did in my longwinded write-up yesterday.
[ ... 122 words ... ]
Dare Obasanjo has provided some initial bullet points of what a vocabulary gets from having an XML Schema :
Usually provides a terse and concise description of
the vocabulary [relative to the prose of the spec]
Enables software to validate that XML documents
being received from clients or servers actually
conform to the vocabulary. This prevents issues like
each application hacking up its own validator or
"liberal RSS parser".
Allows vocabulary to co-exist with technologies and
tools that already support features specific to a
schema language such as relational to XML mapping,
object to XML mapping, directed editting, etc.
Source:Finally Atom: Why use schema?
Danny [Ayers]: "...and the same can already be done using RSS 1.0 as it stands."
But are we talking about the same "same"? The appeal of RSS-Data is that I don't need to work up a schema, get anyone to buy-in, or map anything to an external resource... I take an existing data structure, and plug it into a syndication feed. That's it.
Source:Roger Benningfield in a comment on his "RSS-Data: A Working Demo"
Yes - we know that RDF can do many of the things RSS-Data was designed for.? But (believe it or not) it really has nothing to do with RSS 1.0 at all.? RSS-Data is about extending RSS 2.0.? OK?? Not RSS 1.0.
The point here being that the world is bi-forcated and what do we do?? Can't we all live together?? Can't we put our heads together and come up with solutions that BRIDGE between these two standards - which just happen to have almost the same dam name?
I gotta believe there's a way that once we "structure" something - like a Calendar Events, Resumes, Recipes or Reviews - we SHOULD be able to express and subscribe to these micro-content?formats - via EITHER RSS 1.0 or RSS 2.0.
OK - get it?? BRIDGE BETWEEN BOTH RSS 1.0 & RSS 2.0.? That's what we want.? BOTH!
Source:Marc's Voice: We want BOTH RSS 1.0 & RSS 2.0!
So, it looks like this RSS-Data thing is gaining momentum and demos, so I'm guessing that it's going to become one of the thing us rock-bangers will have to contend with at some point or another in tinkering with things in syndication and interoperability. I have my misgivings about it, which mostly center around the issue of schema.
See, the goal of RSS-Data, as I understand it, is to bridge raw data from one programming environment to another, and package it up to be syndicated within RSS feeds for which an existing infrastructure already exists. So, it's "easy". Just throw your data structures at a library, which serializes them into some magic XML. At the receiving end, another library, written possibly in a different language altogether, transliterates the magic XML into local idiomatic data structures. You never think much about XML, nor does the consumer of your data.
But... we're still talking about structures here. Whether they're represented by XML tags, RDF triples, RDF/XML serialization, or hashtables and arrays-- there's still a structure involved. From whence did it come?
About RSS-Data, Roger Benningfield writes, "...I don't need to work up a schema...", which is literally true. He goes on to write, "I take an existing data structure, and plug it into a syndication feed. That's it."
From where did this "existing data structure" originate? For my examples, I used an existing schema from the Amazon web services. Where'd you get yours?
I'd guess that you got it from somewhere in the bowels of your scripts, a hash or rough structure once limited to intra- or inter- module data exchange, but now pressed into service as a unit of interoperation. I wouldn't expect that you'd put much specific effort toward making this data structure particularly concise or friendly for interoperation. This might not be a big deal for now. And anyway, why bother with it? That's not the philosophy with this tech, as far as I understand it. The idea, is that hopefully this data structure is already good enough for sharing. And, luckily enough, this is sometimes the case.
On the other hand, maybe you're sitting down to come up with a new data structure for sharing, from scratch. During this activity, I imagine that you'll be mulling over what goes where, what's contained by what, what this hash or dictionary key means versus that one. You'll likely be deciding whether to use a string here, or a date time here, and you'll likely have some idea about ranges of values for various things. This is a bit more abstract an activity than you may have gone through, were you simply creating an internal data structure for your app. In this case, you'd likely be thinking more about the data in and of itself, rather than the specific needs of your app and its API. In my opinion, this is a bit better for sharing.
But, how's your documentation? Will I be able to reliably accept data from your application by just looking at a write-up or a rough spec? Will I have to walk through your source code to reverse engineer general usage? Will I have to examine RSS-Data dumps to come up with a rough approximation of what to expect from your data structure? If this is a data structure plucked from the depths of your script, who knows? If this structure was designed specifically for sharing, I hope that you've documented as you go along.
What RSS-Data makes me worry about is an abundance of fuzzy, adhoc structures for interchange that no one ever quite documents well enough because they're too busy hacking along and pushing things out the door. Maybe they'll be good enough, given discipline and thoughtfulness, but then maybe they'll end up in a mess. But, just like many scripting languages, there are no facilities in RSS-Data currently to either require or even merely encourage clean and documented interchange structures.
This is a code-first-schema-later approach: The schema stems, eventually, from general usage and tradition, and if we're lucky, from documentation. If the people hacking on the project have discipline and are thoughtful, this documentation will be well maintained, and changes well communicated. It can be a train-wreck, but it doesn't have to be.
On the other hand, we can circle back to that Amazon Web Services schema I used in my previous examples. This technology, XML Schema, represents the opposite approach: schema-first-code-later. In coming up with such a schema, I think still think about information and data structures just as I would while hacking on a script and thinking about a native data structure for sharing. It's just that, with this approach, I'm doing things in a different order and front-loading the thinking.
But, there's more: if I build something like an XML Schema, I'm creating something which is both documentation and a machine readable resource. I'm sure someone out there is working on or has released tools or stylesheets to convert XML Schema into HTML or RTF or something human readable. Hell, you could even apply some transformation to the schema to generate code or data entry forms.
Once I have a schema, implementing code to produce and handle XML data conforming to it isn't really all that much harder than using straight RSS-Data. This is an item for much dispute, but my gut and limited experience tells me that the difference in complexity will usually be more like a dozen lines of code or less in a decent environment rather than, say, an order of magnitude. I think we'll find that things will tend to be consistent with Phillip Pearson's example implementations of an RSS namespace extension versus an RSS-Data example.
What we get for the added complexity, though, is certainty. I can say, "Here. This is a URL to the schema for the XML data my application produces." If I've lived up to my end
of the bargain, you won't even need to see my application's code or documentation. You can implement with the schema, and our apps will interoperate. We can treat the data formats as separate entities from applications. In other words, we can treat interchange as neutral ground.
The problem, of course, is that this business with schema carries with it a bit of overhead, as well as a demand that you do some homework. You'll need to know more than your immediate programming environment. You'll need to think about XML and XML schemas, and you can't just stay in your comfortable favorite environment of programing language idiom. This is off-putting to some, to say the least.
So... how about Marc's question? "Can't we all live together?? Can't we put our heads together and come up with solutions that BRIDGE between these two standards - which just happen to have almost the same dam name?" On the one side, I see hackers who want to get down and code, and who consider themselves and each other thoughtful and disciplined enough to do the right thing and prevent trainwrecks. On the other side, I see hackers who want to put discipline and thoughtfulness upfront and in writing (or typing?) before they code, because they don't really trust themselves or others to keep from wrecking the trains all the time.
Personally, I want to live somewhere in the middle. Just enough distrust of myself and others to discourage sloppy problems, but not too much so that I have to trudge through careful molasses to get anywhere.
I don't think I'm thrilled with RSS-Data. But if you're going to use RSS-Data anyway, but here's one thought out of all this: Is there some way we could come up with an RSS-Data-analogue for schema? Forget about XML schema and standards groups and the like. Think about some semi-universal way of translating meta-data-structures composed within one's favorite scripting language which forms documentation and a promise about what to expect over the wire? If done right, maybe we could even generate an XML schema with this, and that could be a bridge between the two approaches. On the surface, it sounds like a wonky idea to me, but hey...
Thanks for bearing with me through this much-longer-than-usual post. :)
[ ... 1756 words ... ]
13:52:29 is there a notation for capturing browse
histories in rdf?
13:53:25 good question, monkeyiq... I wanted something
like that a while ago...
13:53:30 I didn't find anything in particular.
Source:#rdfig: hypertext histories and RDF schemas for HTTP
For what it's worth, I'm looking for this too. I've done a little bit
of work in cobbling together some RDF representations of HTTP transactions,
in order to record browsing history in a rich way. I've
basically just been mapping from HTTP/1.1
header fields to RDF properties. It's been a little while, but I seem to remember that both
dbproxy's metaminer plugin
and
AgentFrank's MetaMiner plugin
have implementations toward this end. Sooner or later, I'll get back to one project or
the other, and I'd really like someone else to do my homework on this. :)
[ ... 138 words ... ]
After making those RSS namespace examples, I was thinking aloud about
SOAP on [#joiito](/tag/joiito) yesterday and how it compares to what I did with the Amazon
data. Sam Ruby
happened to be in the room:
deusx: want a quick primer?
rubys: I'd love one, though unfortunately at the moment,
I'm about to be off to a meeting :(
f8dy would like a quick primer
This is really quick. Take some XML. XML that doesn't
have a DTD or any PI's. Put it in a soap:Body. Put the soap:Body in
a soap:Envelope. Voila', you have valid document literal SOAP.
That was a quick primer, and though I know there's more to
it, putting it like that makes me see SOAP a little differently.
[ ... 127 words ... ]
So, for the same of argument, yesterday I threw together
examples
of what a use of RSS-Data might look like alongside what
the same data in an RSS namespace extension might look like.
I promised code, but never got a chance to circle back around.
Fortunately, Phillip Pearson
connected the rest of the dots for me with two examples:
Parsing RSS-Data
Parsing an RSS namespace extension
I was just a little surprised by his results, since I expected
the code to handle an RSS namespace to be at least a bit more complex
than the RSS-Data example. But,
as Phillip observed later,
the scripts were pretty much equivalent in length, complexity, and
ease of construction.
Then, this morning, I saw that Danny Ayers had posted an
example in RDF
of this same data. It doesn't differ very much from my namespace
extension example, except that the few differences there are enables
his example to flow through RDF tools (as well as, usually, XML tools like
XPath and XSLT).
In a comment
on one of Phillip's posts, though, Roger Benningfield makes
the point that this example is a bit biased:
I agree that there won't be a ton of difference between a struct full
of strings and plain ol' XML. But that's kind of a stacked example,
since SDL would allow a lot more than that... arrays, integers, and
arrays of integers inside structs.
What I did could be obscuring some work. I just took an existing
schema from Amazon, which gave me some initial work already for free.
(Though, there's something to be said for that in and of itself.)
The structures were already established, and the schema was created
with XML representation already in mind. This could have placed
RSS-Data at an example. While I really don't think
that XML-RPC serialization offers more flexibility in expression than
XML itself, I could be wrong and I don't want to be tilting
at straw men.
So, while I doubt that I'll have a whole lot of time today, I think
for the same of completeness, someone should go through the parallel
processes of going from problem statement up through data modeling and
on to production and consumption of RSS-Data and an RSS namespace
extension. While doing this, capture the work involved in both.
I could see shortcuts taken on the RSS-Data side, since you don't have
to be concerened with various bits of XML tech like DTDs or schema
or whatnot. You can jump right into coding up an example usage and
come up with your data model on the fly. Whether this is a good thing
or not, I'm sure many will disagree. Also, I'm sure others would
go through this differently than I would. Again, your mojo may
exceed mine.
At this point, I can see the benefits of RSS-Data in rapidly cobbling
together scripts, but I lean toward having a decently defined data
model first. You can do this in your scripts, but using the existing
XML tech forces you through some specific processes. On the other
hand, I can see where some busy developers don't have time or spare
brain cycles to absorb all the XML tech. It could be made easier
at that end of things, which is where I'd rather spend my effort.
Anyway, I'm really interested in seeing where this goes, because
this comparison of RSS-Data, RSS namespace extensions, and even
RDF seems like another very concrete, non-theoretical way to demonstrate
the benefits and drawbacks of these ways of thinking about data
and interoperability.
[ ... 591 words ... ]
Okay, I got
the example data out there.
Here's what's first on my mind about it:
Man, that RSS-Data is one verbose piece of XML. The Amazon-specific
namespace version looks much more compact and readable; I'd rather
View Source
on that one.
Python comes out of the box with
xmlrpclib,
and other languages have XML-RPC facilities available as well. I can't imagine
it'd be too hard to get a hold of the core of it and employ it in
unmarshalling the RSS-Data straight into idiomatic Python structures.
On the other hand, I'll need to write my own handlers for the Amazon XML
using the XML parser modules that come with Python.
With its clean, almost self-documenting structure, the Amazon XML is easily
handled with XPath and XSL. If I had a pile of ProductInfo elements
in a document, I could yank out all their images with something like:
//az:ProductInfo/az:Details/az:ImageUrlSmall
Using the RSS-Data
example, it'd probably be something more like:
//sdl:data/sdl:struct/sdl:member/sdl:name[@text='ImageUrlSmall']/../sdl:value,
and that's not considering if I have mixed kinds of RSS-Data schema represented in the
feed.
I suppose I could help this out by surrounding the struct with another
struct, containing one member named 'AzProductInfo', making the path something
like so:
//sdl:data/sdl:struct/sdl:member/sdl:name[@text='AzProductInfo']
/../sdl:value/sdl:struct/sdl:member/sdl:name[@text='ImageUrlSmall']/../sdl:value.
And these are the conclusions I'm jumping to at the moment, before experimenting:
RSS-Data's convenience to script authors is at odds with the RSS 2.0
spirit of View Source.
Producing and consuming RSS-Data could be easier than handling
purpose-specific XML schema in scripts.
Since RSS-Data doesn't follow in the spirit of XML specs and schema,
using formal XML tools to handle this stuff will give you
nothing but headaches. (Then again, it seems like some of the
stuff that's fully in the spirit of XML yields headaches just
the same.)
RSS-Data might catch on and spread nonetheless, because lots
of people don't read XML, don't use formal XML tools, and just
write scripts to get their jobs done.
[ ... 322 words ... ]
Okay, just for the sake of tinkering, I'm poking at embedding data
from the
Amazon Web Services
into an RSS 2.0 feed. On one hand, I just shoehorned the Amazon
XML schema into an RSS 2.0 namespace, and on the other, I tried
transliterating the Amazon XML data into
RSS-Data /
XML-RPC serialized data
structures.
To resolve my own love/hate of this RSS-Data idea,
I'm planning to keep going from here and work up some simple Python
scripts to produce and consume data along the lines of both examples,
then to comment on the experience. (This is assuming I don't run out
of round tuits.) Some things to note:
Your XML mojo is probably stronger than mine,
so please feel free to correct me.
Although I created the RSS-Data example by hand, it would
otherwise be completely produced and consumed by machine.
Since it's at the root of a few things I'm thinking,
it's worth restating: RSS-Data is intended to be produced and
consumed by machine, not by humans. This means that the XML
data needs not look pretty or elegant to you, but to your machine.
So, on with the XML. First, I
requested data
from Amazon and got the following:
0439139597Harry Potter and the Goblet of Fire (Book 4)BookJ. K. RowlingMary GrandPr?08 July, 2000Scholastichttp://images.amazon.com/images/P/0439139597.01.THUMBZZZ.jpghttp://images.amazon.com/images/P/0439139597.01.MZZZZZZZ.jpghttp://images.amazon.com/images/P/0439139597.01.LZZZZZZZ.jpgUsually ships within 24 hours$25.95$18.16$3.97
From this, I cooked up an example RSS feed with Amazon's XML
schema shoehorned in as a namespace:
Testing Amazon NamespaceHarry Potter and the Goblet of Fire (Book 4)0439139597Harry Potter and the Goblet of Fire (Book 4)BookJ. K. RowlingMary GrandPr?08 July, 2000Scholastichttp://images.amazon.com/images/P/0439139597.01.THUMBZZZ.jpghttp://images.amazon.com/images/P/0439139597.01.MZZZZZZZ.jpghttp://images.amazon.com/images/P/0439139597.01.LZZZZZZZ.jpgUsually ships within 24 hours$25.95$18.16$3.97
Then, I transliterated things into what I understand of RSS-Data:
Testing Amazon NamespaceA Sample Itemurlhttp://www.amazon.com/exec/obidos/ASIN/0439139597/0xdecafbad-20Asin0439139597ProductName
Harry Potter and the Goblet of Fire (Book 4)
CatalogBookAuthorsJ. K. RowlingMary GrandPrReleaseDate2000-07-08T00:00:00ManufacturerScholasticImageUrlSmallhttp://images.amazon.com/images/P/0439139597.01.THUMBZZZ.jpgImageUrlMediumhttp://images.amazon.com/images/P/0439139597.01.MZZZZZZZ.jpgImageUrlLargehttp://images.amazon.com/images/P/0439139597.01.LZZZZZZZ.jpgAvailabilityUsually ships within 24 hoursListPrice$25.95OurPrice$18.16UsedPrice$3.97[ ... 613 words ... ]
A few months ago I approached Dave Winer and a few other people with a very simple idea.? Why not use XML-RPC's data serialization format to create a simple data language for object meta-data in RSS (and other!) applications.? Interestingly, if you subtract the message envelop from XML-RPC, add Unicode and time-zone support to the standard, you've actually got WDDX, quite literally.? Dave really liked the idea, and we came up with the idea of RSS-Data.
Why use RSS-Data?? Pragmatism.? Because of the rapid growth of blogging software, XML-RPC parsers are already implemented in dozens of languages and platforms.? As a result, a simple data language based on XML-RPC's data model could emerge in a matter of days or weeks, as developers quickly refactor their parsers to simply provide data serialization/deserialization components.
Source: Jeremy Allaire's Radio (via Silicon Valley - Dan Gillmor's eJournal - Expanding the Scope of RSS)
Grr. I can’t decide whether I hate this idea or can live with it. On the one hand, I have benefitted from XML-RPC and it’s quick integration between disparate scripting environments. But on the other hand, the tendency to use adhoc data structures in scripting has given me numerous headaches and plenty of inexplicable bugs.The further I get, the less I want quick and dirty, and the more I want thoughtful chaos and at least some documentation. I’d like some schemas, rather than reverse engineering from example. But sometimes it’s nice to short circuit over-designed processes and take expedient shortcuts, even if there lies the road to madness. Sleep is good sometimes.
[ ... 262 words ... ]
This is an interesting thing over at
Life on Mars:
Comment Icons.
Post a comment, supply the URL to your blog, and if your
blog has a locatable RSS feed which points to an image,
that image will be displayed next to your comments. As I've
been known to have a mild obsession with LiveJournal, this reminds
me a lot of the usericons in use there, only distributed
across blogspace, which is what I've wanted to see done for a
long time.
All the infrastructure of LiveJournal,
Friendster, and the like could be recast as distributed
feeds and metadata, with smarts on blog servers or
personal clients. One piece at a time...
[ ... 113 words ... ]
Just discovered Tom Dyson's
Mailbucket.org,
and started playing around with signing up mailing lists
for feeds. It's simple, send an email to
foo@mailbucket.org,
then check http://mailbucket.org/foo.xml
for an RSS feed.
I was tinkering with something like it last week, using
Postfix, Mail::Audit, and blosxom -- but hey, if someone else
has done it, I'll just go use theirs! :)
A few feeds I've set up:
cocoa-dev from Apple
macosx-dev from OmniGroup
[ ... 94 words ... ]
Okay, so that thing with the SQL I did Friday?
I'm not exactly sure what I was thinking with it. I was doing something
that seems really odd now, trying to collect counts of new items together
by hour, then averaging those hourly counts across a week. Instead, I'm
trying this now:
SELECT
source,
'update_period' AS name,
round(min(24,max(1,(max(1,(iso8601_to_epoch(max(created)) -
max(now() - (7*24*60*60), iso8601_to_epoch(min(created)))) /
(60*60))) / count(id))),2) AS value
FROM
items
WHERE
created >= epoch_to_iso8601(now() - (7*24*60*60))
GROUP BY
source
This bit of SQL, though still ugly, is much simpler. This leaves out
the subselect, which I think I might have been playing with in order
to build a little graph display of new items over time by source. What
the above does now is to get an average time between new items for the
past week, with a minimum of an hour, and a maximum of a day. This
seems to be working much better.
An alternate algorithm I've been playing with was suggested in
a comment
by Gnomon,
inspired by TCP/IP's Additive Increase / Multiplicative Decrease.
With this, I subtract an hour from the time between polls when a
poll finds new items, and then multiply by 2 every time a poll
comes up with nothing new.
Using the average of new items over time lessens my pummeling
of servers per hour, but the second approach is even lighter
on polling since it's biased toward large leaps backing off
from polling when new items are not found. I'll likely be trading
off between the two to see which one seems to work best.
Hoping that, after playing a bit, I'll settle on one and my
aggregator will play much nicer with feeds, especially once
I get the HTTP client usage to correctly use things like
last-modified headers and ETags. There's absolutely no reason
for a news aggregator to poll a feed every single hour of a day,
unless you're monitoring a feed that's mostly quiet, except
for emergencies. In that case, well, a different polling
algorithm is needed, or maybe an instant messaging or pub/sub
architecture is required.
Update: As Gnomon
has corrected me in comments, I've got the AIMD algorithm mixed up.
What I really should be doing is making quick jumps up in polling
frequency in response to new items (multiplicative decrease of
polling period) and creeping away in response to no new items
(additive increase of polling period). As he notes, this approach
should make an aggregator jump to attention when clumps of new
posts come in, and gradually get bored over periods of silence.
I've adjusted my code and will be tinkering with it.
Also, although Gnomon makes
a good point that bloggers and their posting habits are not easily
subject to statistical analysis,
I've further refined my little SQL query to catch sources
which haven't seen any updates during the week (or ever):
SELECT
id as source,
'update_period' AS name,
round(min(24,max(1,coalesce(update_period,24)))) AS value
FROM sources
LEFT JOIN (
SELECT
source AS source_id,
(iso8601_to_epoch(max(created)) -
max(
now()-(7*24*60*60),
iso8601_to_epoch(min(created))
)
) / (60*60) / count(id)
AS update_period
FROM items
WHERE created >= epoch_to_iso8601(now() - (7*24*60*60))
GROUP BY source
) ON sources.id=source_id
Also, in case anyone's interested, I've checked all the above
into CVS. This beastie's far from ready for prime time, but it
might be interesting to someone.
[ ... 1237 words ... ]
Today, my aggregator got
the following SQL worked into its feed poll scheduling machinery:
SELECT id as source,
'update_period' as name,
max(1, 1/max((1.0/24.0),
sum(update_count)/(7*24))) AS value
FROM sources
LEFT JOIN (
SELECT source AS count_id,
round(iso8601_to_epoch(created)/(60*60)) AS hour,
count(id) AS update_count
FROM items
WHERE created>epoch_to_iso8601(now()-(7*(24*60*60)))
GROUP BY hour
) ON id=count_id
GROUP BY source
ORDER BY value
It's likely that this is really nasty, but I have only a street-level
working knowledge of SQL. Also, a few of the date functions are
specific to how I've extended sqlite in Python. It works though, and
what it does is this:
For each feed to which I'm subscribed, work out
an average time between updates for the past week, with a maximum
period of 24 hours and a minimum of 1 hour.
My aggregator does this daily, and uses the results to determine how
frequently to schedule scans. In this way, it automatically backs off
on checking feeds which update infrequently, and ramps up its polling
of more active feeds. This shortens my feed downloading and scanning
time, and is kinder in general to everyone on my subscription list.
Next, among other things, I have to look into making sure that the
HTTP client parts of this beast pass all the
aggregator client
HTTP tests that Mark
Pilgrim put together.
Update: Well, it seemed like a good idea, anyway. But, on
further examination, it has flaws. The most notable is that it
assumes a polling frequency of once per hour. This works right up
until I start changing the polling frequency with the results of the
calculation. I haven't poked at it yet, but maybe if I take this
into account, it'll be more accurate.
On the other hand, I've also been thinking about a much simpler
approach to ramping polling frequency up and down: Start out at
a poll every hour. If, after a poll, no new items are found,
double the time until the next poll. If new items were found,
halve the time until the next poll.
Provide lower and upper limits to this, say between 1 hour and 1
week. Also, consider the ramp up and ramp down factor as a variable
setting too. Instead of a factor of 2, maybe try 1.5 or even 1.25 for
a more gradual change. To go even further, I wonder if it would be
valuable to dynamically alter this factor itself, to try to get the
polling time zeroed in on a realistic polling time.
Okay. There the simpler approach leaves simplicity. I'm sure there's
some decently elegant math that could be pulled in here. :)
[ ... 638 words ... ]
I would like to propose, nay, admonish, that the name of the format and spec
should be Atom, that the current naming vote should be killed, and we should
move on to grander things without the auspices of "what's it called?!" over
our heads. This has been going on far too long.
Source:Morbus Iff: 'Atom' Should Be It's Name, and It's Name Was Atom
I haven't been anywhere near the epicenter of Atom/Pie/Echo much,
so this is mostly a 'me too' kind of posting. But, you know, as an
interested hacker waiting for dust to settle before I start paying
much attention, the decision on a name, as superficial as it is,
seems telling to me.
On one hand, I could take it to be representative of what's going
on inside the project as a whole. (If they can't settle on a name,
how can they settle on what's included in the spec?) On the other hand,
it could just be that naming the thing is the least interesting aspect
of the project. But I consider that because I'm a nerd, I've been
there, and I want to see the project thrive. Others might not be so
charitable or patient. :)
So just name the dang thing Atom already.
[ ... 273 words ... ]
Enter attention.xml. Of course it monitors my attention list, noting what feeds are in what order. Then it pays attention to what items I read, in what order, or if not, then what feeds I scan, and for how long. The results are packaged up in an attention.xml file and shipped via some transport (RSS, FTP, whatever) to Technorati. Dave has some ideas about what he will provide in return: "If you liked these feeds and items, then here are some ones you don't know about that you may want to add to your list."
But the real power comes in a weighted return feed that works like this: OK, I see who you think is important and what posts are most relevant to your interests. Then we factor in their attention.xml lists weighted by their location on your list, average the newly weighted list based on this trusted group of "advisors", and return it to your aggregator, which rewrites the list accordingly.
Source: Steve Gillmor's Emerging Opps
Dave Winer says this guy’s full of shit. I’m not sure why, or it if’s sarcasm. In a lot of ways, what Steve Gilmore wrote about sounds like syndicating whuffie and what Gary Lawrence Murphy of TeledyN wrote about republishing RSS items read and rated from one’s news aggregator.
Sounds like the next one of the next steps this tech needs to take to hit a new level of intelligence, forming a minimum-effort feedback loop from writers to readers and between readers themselves. What did I read today, and was it interesting? What did you read today, and was it interesting? What did we both read and both find interesting? What did you read, and find interesting, that I didn’t read and might find interesting? And then, back around to the author again, what of your writings was found very interesting, and (maybe) by whom?
Okay, I may be the last person fiddling with Flash to
discover this, but here's what I've learned today:
Flash MX hates progressive JPEGs.
From the above: "The Macromedia Flash Player does not have a
decompressor for progressive JPEG images, therefore files of this type
cannot be loaded dynamically and will not display when using the
loadMovie action."
This would have been nice to know, hours ago. Or maybe fixed in
the past year or so since the above linked tech note. See, although
I'm a Jack of a lot of Trades, I don't really pay attention much
to things like JPEGs and their progressive natures. It wasn't
until I finally started randomly clicking buttons on and off in
Macromedia Fireworks while exporting a test JPEG that I finally
narrowed down the problem.
This was after a day worth of examining ActionScript, XML data,
HTTP headers, and a mess of other random dead ends. And a lot of
last-ditch random and exhaustive twiddling of checkboxes and
options.
Then, once I had the words I
wouldn't have had unless I already knew what my problem was, a Google search for
"flash progressive jpeg"
got me all kinds of info.
Problem is, the JPEGs supplied to the particular Flash app on which
I'm hacking come from a random assortment of people working through
a content management system on the backend. They upload them
with a form in their browser, and this Flash app gets a URL to the
image via an XML doc it loads. Me, I'm probably in bed when this
happens. I'd love to have tested every one... er, rather, no I
wouldn't.
So... Now I just have to figure out how to get all these people
to start making sure that their JPEGs aren't progressive. Hmph.
I can only hope that this message gets indexed and maybe provides
more triangulation for some other poor sucker in the future.
[ ... 429 words ... ]
* Orangerobot uses cracked software. I will respond to the following
commands: !ame , !amsg , !quit ,
!open_cd, !switch_my_mouse_buttons
Hmm. If what Orangerobot just emoted is true, that's
funny as hell.
!amsg Wang!
Wang!
and what's the purpose?
AnitaR: Of the message from Orangerobot?
yes
must be part of the joke I'm not getting
yet
* Orangerobot uses cracked software. I will respond to the following
commands: !ame , !amsg , !quit ,
!open_cd, !switch_my_mouse_buttons
AnitaR: Could be a joke, but it appears that this person
is using pirated software that's detected its illegitimacy and is
allowing us to manipulate that user's computer.
or its a social experiment by the person behind OR :)
adamhill: Or that. :) Either way, it's fun
I'm glad it isn't one of those experiments that tests
how strong a shock we'll give the owner
?def orangerobot
Some googling points to this software:
http://www.klient.com
!switch_my_mouse_buttons
!ame likes cheddar cheese.
* Orangerobot likes cheddar cheese.
?learn Orangerobot is either a person using cracked
software or a social experiment by a demented psych student
I understand now, Dr. Chandra; orangerobot is either a
person using cracked software or a social experiment by a demented
psych student
!open_cd
okay, I'm done.
* Orangerobot uses cracked software. I will respond to the following
commands: !ame , !amsg , !quit ,
!open_cd, !switch_my_mouse_buttons
!quit hush.
<-- Orangerobot has quit ("hush.")
[ ... 327 words ... ]
Some folks are experimenting with using Wiki to build websites. I particularly like what Matt Haughey did with PHPWiki and a bit of CSS magic dust. Looks nice, eh? [Via Seb's Wikis are Ugly? post at Corante]
Janne Jalkanen's Wiki-based Weblog is interesting too. Hmm. Maybe blog API(s) can be used for Wikis too. That reminds me, shouldn't Wiki formatted text have their own MIME type? Is there one? "text/wiki"? For now, different dialects of Wiki formatting rules will have to be accounted for like "text/wiki+moinmoin".
Source: Don Park's Daily Habit
It's been a while since I last worked on it, but I did implement an
XML-RPC API on a few wikis, called XmlRpcToWiki. Janne Jalkanen
did a lot of work toward the same interface with JSPWiki. I use this API
in the linkage between my blog and the wiki on this site. Now that
I've drifted away from XmlRpc a bit and am more in favor of simpler
REST-ish web service APIs, I'd like to see something more toward that
end. Seems like a lot of people are discovering or rediscovering
wikis since the introduction of Sam Ruby's wiki for Atom/Echo/Pie
work, so it's interesting to see a lot of things come up again like
grousing about APIs and mutant wiki-format offshoots and standards.
[ ... 290 words ... ]
Or maybe it's time to release our own Defender.A worm which could invasively close down the relevant "holes" in Internet security. A defensive worm could use standard intrusion tactics for benign result. For example, it could worm it's way into Windows XP computers and get the owner's permission to turn their firewalls on. It could survey open TCP/IP ports and offer to close them.
Source: Superworm To Storm The Net On 9/11 (via KurzweilAI)
So, anger is my first reaction to the idea of any unwelcome visitors on any of my machines, well intentioned or not. I’m sure that there aren’t many who wouldn’t feel the same way. But, although a lot of us try to keep up on patches and maintain decent security, there’s the “great unwashed masses” who just want to “do email“.
On one hand, it’s easy to say, “Tough. Learn the care & feeding of your equipment.” Yeah, as if that will help or get any response from all the people who’ve bought into AOL and have been reassured for years that computers are friendly and easy beasts (despite their intuitions to the contrary). Hell, I’d bet that, more often than not, the same person who gets regular oil changes and tune-ups for the car has no idea how to do the equivalent for a computer (or that it even needs it). Cars have been positioned differently than computers. No one expects a Spanish Inquisition when they live in a virtual preschool of a user interface with large and colorful buttons and happy smiling faces. They know there’s some voodoo going on underneath, but the UI tells them that it’s nothing to worry about (until it isn’t working).
Now if the problem was just that stupid users ended up with broken computers, there’d be no problem. But, like cars with problems waiting to happen (like worn down tires), their users become a hazard to others. Unlike cars, however, the problems of stupid users’ computers are contagious and self-replicating: every tire blowout becomes a 1000 car pileup.
It’s like everyone sits on their recliners watching TV in their houses; not even realizing that there are doors to lock; not even hearing the intruders rummaging through the fridge in the kitchen; and certainly not knowing that there’s a guy sleeping on the sofa at night working by day to let his army of clones into the neighbor’s houses.
So, about what about vigilante “white hat” worms? Wouldn’t it be nice if there was a guy wandering the neighborhood locking door for the ignorant? Wouldn’t it be nice if there was a truck driver on the road that forced cars with bald tires off to the side for free tire replacement? Okay, maybe that’s a bit whacky, but then again, people with bald tires aren’t causing 1000 car pileups.
I’m thinking that “white hat” virii and worms are one of the only things that will work, since I’m very pessimistic about the user culture changing to be more responsible. Though, what about a compromise? Install a service or some indicator on every network-connected machine, somewhat like robots.txt , which tells friendly robots where they‘re welcome and where they‘re not. Set this to maximum permissiveness for white hat worms as a default. The good guys infect, fix, and self-destruct unless this indicator tells them to stay out. Then, all of us who want to take maintenance into our own hands can turn away the friendly assistance of white hat worms. It’s an honor system, but the white hats should be the honorable ones anyway. The ones which ignore the no-worms-allowed indicator are hostile by definition.
So, then, the internet develops an immune system. Anyone can release a white hat worm as soon as they find an exploit to be nullified, and I’m sure there are lots of geeks out there who’d jump at the chance to play with worms and virii in a constructive way. And if you want to opt-out of the system, go for it. Hell… think of this on a smaller scale as a next-gen anti-virus software. Instead of internet-wide, just support P2P networks between installations of your anti-virus product. When it’s time to close a hole, infect your network with a vaccinating update. I doubt this would work as well as a fully open system, but might have less controversy.
Anyway, it’s a whacky idea to a whacky problem that just might work.
What the [#joiito](/tag/joiito) bot knows. I'm dumping it out dynamically with the Twisted webserver, which is all Python too.
Source: Epeus' epigone - Kevin Marks weblog
While the #joiito bot is looking pretty keen, I keep wondering if anyone hacking on it has seen Infobot ? It’s the brains behind purl, the bot serving [#perl](/tag/perl) channels on a few IRC networks. Jibot seems to have some funky punctuation-based commands, but purl accepts commands in formulatic english and even picks a few things up from normal channel chatter. When I look at Kevin Marks’ dump of Jibot’s brains, I can’t help but think of the gigantic factoid packs available for Infobot.
[ ... 167 words ... ]
I haven't been paying attention to my referrers as much lately,
but I probably should. Because, when I do, I find things like
another implementation
of BookmarkBlogger in Python, this one by
David Edmondson.
His version has many fewer requirements, using only core Python
libraries as far as I can see. One of these which I hadn't any idea
existed is
plistlib,
"a tool to generate and parse MacOSX .plist files". When I get
another few round tuits, I'll likely tear out all the XPath use
in my version and replace it with this. Bummer. And here I thought
I was all clever using the XPaths like that in Python :)
[ ... 163 words ... ]
Hanging out on joiito on IRC today,
I read Ecyrd asking
around about any tools to present GNU-style changelogs
as an RSS feed. I couldn't find any, but I did find
this changelog parser, apparently
by Jonathan Blandford. So,
when I had a few free minutes, I took some parts I had laying around, along
with this parser, and made this:
- Changelog for JSPWiki
Source code for cl2rss
This is at the "it works" stage. It needs much work in what it presents
in an RSS feed, so feel free to suggest changes!
[ ... 188 words ... ]
After tinkering a bit with
web services and XSLT-based scraping
last week for generating RSS from HTML, I ripped out some work I was
doing for a Java-based scraper I'd started
working on last year and
threw together a kit of XSLT files that does most everything I was trying
to do.
I'm calling this kit XslScraper, and there's further blurbage and download links
avaiable in the Wiki. Check it out. I've got shell scripts to run the stuff
from as a cron job, and CGI scripts to run it all from web services.
For quick gratification, check out these feeds:
- The Nation (using Bill Humphries' XSL)
- KurzweilAI.net
- J-List -- You've got a friend in Japan!
- New JOBS at the University of Michigan (By Job Family)
[ ... 141 words ... ]
It's been one year since I
signed up for a JohnCompanies server,
and though I've had no complaints whatsoever, I've signed up for
a server instance with JVDS.com and have moved
just about everything over.
Why? Because it's cheaper, and I have less disposable income these
days. And, well, it seemed like fun to try another virtual server
company, since I've been looking into it so much lately. The new
server has less capacity than the one I've had at JohnCompanies, but I
really don't need all that much -- just a roof over my files and a
root password. Well, I don't really need a root password, but it's
nice to have so that I can tinker around with more things with fewer
questions asked of the management. (For what it's worth, we're still
using JohnCompanies servers for hosting at my work.)
I've almost got this server migration thing down to a science, though,
since I had everything over and up in a few hours. And that was going
from a FreeBSD system to Debian Linux. Personally, though I fully
respect FreeBSD and the ports collection, I like Debian and apt-get
so much better. But who knows, maybe in another year, I'll be moving
again for the hell of it.
I don't have much in the way of reputation for JVDS, but the management
has been very responsive to requests so far. In fact, they're using
RT for their support ticket
management. Responsiveness has been one of the most impressive aspects
of JohnCompanies, since between my personal server and the servers
I use at work, it tends to take less than an hour to get resolution
on any problems I've had. So far, JVDS has yet to disappoint me as
well.
[ ... 640 words ... ]
Remember my BookmarkBlogger? Well, I rewrote it in Python. For
a little while, I was making little apps in Java, wishing it were a
scripting language. I've stopped that now. Also, I've added the
ability to include both link text and a non-linked comment in the
bookmarks to be blogged. This new version is quite a bit simpler
and contained all in one script -- configuration, template, and all.
Download a tarball here
from my CVS server.
[ ... 78 words ... ]
I walked in thinking "I can't believe I'm a student again. I'm a student again? Yee-bloody-ikes, how am I going to manage being a student again?"
And I walked out with a spring in my step, thinking, "Hey! I'm a student again! W00t!"
Source: Caveat Lector: Augusti 24, 2003 - Augusti 30, 2003 Archives
I’m not entirely sure (though I have hunches) on how to go about it, or to whom I should be talking, but this is what I want to be saying in the not-too-distant future.
[ ... 101 words ... ]
It occurred to me that this ought to be possible by reassigning a container's background-image property when it is :hover-ed.
Source: Images and thumbnails, a pure CSS hack (via dbagg: Items by Time)
Yup, and you can do the same for every other pseudo-class of an anchor tag. I read about this via Eric Meyer’s article on the O‘Reilly Network. I’m still very much a CSS neophyte, but it’s helped me incredibly at work, where I was able to create a site layout with one set of HTML pages styled by a small library of CSS files for look & feel.
Yeah, yeah, that’s what it’s for, you say. But it surprised the hell out of me that I was able to abuse background image properties of containers to create JavaScript-free rollovers, as well as select between completely different image-based layout elements. This isn’t pure utopian CSS that I’m doing, and most of my position is still with tables, but thanks to blank pixel images atop CSS-controlled background images, I can do what I think are amazing things.
Now I just have to break free of the rest of my HTML crutches, circa 1996.
Okay, so I took another shot at scraping HTML with web services with another site that passes the HTML Tidy step. Luckily, this is a site that I already scrape using my own tool, so I have XPath expressions already cooked up to dig out info for RSS items. So, here are the vitals:
Site: http://www.jlist.com
XSL: http://www.decafbad.com/jlist.xsl
Tidy URL: http://cgi.w3.org/cgi-bin/tidy?
docAddr=http%3A%2F%2Fwww.jlist.com%2FUPDATES%2FPG%2F365%2F
Final URL: http://www.w3.org/2000/06/webdata/xslt?
xslfile=http%3A%2F%2Fwww.decafbad.com%2Fjlist.xsl&
xmlfile=http%3A%2F%2Fcgi.w3.org%2Fcgi-bin%2Ftidy%3F
docAddr%3Dhttp%253A%252F%252Fwww.jlist.com%252FUPDATES%252FPG%252F365%252F&
transform=Submit
Unfortunately, although it looks okay to me, this feed doesn’t validate yet, but I’m still poking around with it to get things straight. Feel free to help me out! :)
After checking out Bill Humphries’ approach to scraping yesterday, I recalled the various things Jon Udell has written about URL-as-command-line and the various places I’ve seen the W3C XSLT Servlet used in XSLT tinkering. I also remembered that there’s an HTML Tidy service offered by W3C as well.
So… these are all URLs. I figured I could pull together the site URL, Bill’s XSLT, the tidy service, and the XSLT service, and have a whole lot of scraping going on right in my browser or via wget or curl. Here are the steps in how I composed the URL:
Unfortunately, this doesn’t work. In particular, step [#2](/tag/2) fails, the Tidy service reporting a failure in processing the original HTML. I imagine, had that worked, the whole process at step [#3](/tag/3) would be producing RSS. On my command line, HTML Tidy works fine, so I’ve been thinking of throwing together my own web interface to that program and seeing if that works.
If it works, this with the addition of a cache at each stage could allow for what I think is a pretty nifty, all web-based means of scraping news items from web sites.
What would really be nice for apps like this is a better way to express the URLs-within-URLs without escaping and escaping and escaping and... Thinking some very lightweight scripting here, or some LISP-ish expressions would help.
Continuing with making it easier for "Big Pubs" to create RSS feeds. I'm assuming that they have a publishing system, but it wasn't built with RSS in mind, but they want on the bandwagon.
Source: More Like This WebLog: Thursday, 21 August 2003
Using curl, tidy, and XSL to scrape content from HTML pages into an RSS feed. This is basically what I do now with a half-baked Java app using JTidy, XPath, and BeanShell. I keep meaning to release it, but it’s too embarassing to share so far. Yet, it’s been working well enough to scrape what sites I’m interested in such that I haven’t been too motivated to tidy it up and tarball it. One thing I like better about Bill Humphries’ approach, though, is that it doesn’t use Java :)
[ ... 195 words ... ]
Let's face it, email has become unuseable, the latest worm to strike is likely only the tip of the iceberg we're about to collide with. I've never liked the metaphore of an 'inbox', certainly not one that fills up and can't accurately be filtered.
Source: Email is Dead, Long Live Email!
I linked to D.J.Bernstein’s Internet Mail 2000 project a little while back, and I think what Adam Curry says here is along a similar path.
Internet Mail 2000 starts off with the assumption, “Mail storage is the sender’s responsibility.” So, you want to send me an email? Post it on your server and tell me to come & get it. When I get the notification, I’ll then decide whether or not I want to bother. There are a lot of details to fill in here, such as secure posting and retrieval, trust and identity, notification mechanisms. But, it certainly would seem to balance out the equation a bit.
How to do it, though, so that things are still at least as simple to use as existing email, such as it is?
In case it had been an annoyance to anyone, I’ve finally gotten around to adding a “Remember my personal info” cookie to my comment forms. Let me know if it breaks. Otherwise, carry on!
[ ... 35 words ... ]
Despite a reading an entry by Srijith
discussing Bayes-based classification as unsuitable
for use in news aggregators, I tied SpamBayes
into my homebrew news aggregator
and have been trying it out this week. I know I’ve been talking about it
for awhile, but procrastination and being busy all round kept me from getting
to it. Funny thing is, when I finally got a chance to really check things out,
the integration was a snap. I’d anticipated a bit of work, but was pleasantly
surprised. I doubt that any other aggregator written in
Python would have a hard time with it.
If, that is, anyone else wants to do it. I already knew it wasn’t
magic pixy dust
but I figured it might be worth a try. I will be eating my dogfood
for awhile with this, but I’m thinking already that what’s good for spam
might not be so good for news aggregators.
Srijith’s post
mentions some snags in ignoring some of the semantics of a news item,
such as whether a word appears in the item’s title or information about
the item’s source. I don’t think that this completely
applies to how I’m doing classification, since SpamBayes appears to
differentiate between words found in email headers and the body itself.
When I feed an item to SpamBayes for training and scoring, I represent
it as something like an email message, with headers like date, subject,
from, and an “X-Link” header for the link. However, even with this,
I think Srijith’s got a point when he writes that this method will miss
a lot of available clues for classification.
Unlike Srijith’s examples, though, I’m not trying to train my
aggregator to sift entries into any specific categories. So far, I’ve
been trying to get it to discriminate between what I really want to
read, and what I’m not so interested in. So, I figured that something
which can learn the difference between spam and normal email could help.
But, although it’s early, I’m noticing a few things about the results and
I’ve had a few things occur to me.
See, in the case of ham vs spam, I really want all the ham and none of
the spam. A method to differentiate between these two should be
optimized toward one answer or the other. SpamBayes offers “I don’t
know” as a third answer, but it’s not geared toward anything else
in-between. However, in measuring something like “interest“,
inbetween answers are useful. I want all of the interesting stuff,
some of the sort-of interesting stuff, and a little of the rest.
This is also a problem for me in deciding to what I
should give a thumbs up and what gets the thumbs down. Even though
I’ve subscribed to a little over 300 feeds, every item from each of
them is somewhat interesting to me. I wouldn’t have subscribed to the
feed if there wasn’t anything of interest there, so I’ve already
biased the content of what I receive. Some items are more interesting
than others, but the difference between them is nowhere near the
difference of wanted ham vs unsolicited spam. So, I find myself
giving the nod to lots of items, but only turning down a few.
SpamBayes would like equal examples of both, if possible.
I’ll still be playing with this for awhile, but I need to look
around at other machine learning tech. I’m just hacking around,
but the important thing is to try to understand the algorithms
better and know how they work and why. Bayes is in vogue right now,
but as Mark Pilgrim intimated, it’s not magic. It’s just “advanced” :)
In the immortal words of Mark Jason Dominus: “You can’t just make shit
up and expect the computer to know what you mean, retardo!”
[ ... 731 words ... ]
16:06:23 [neo85] DO I NEED TO GO TO A SPECIFIC FOLDER TO LOAD
THE HTMAL?
...
16:07:37 [Ash] neo85: you may need to clear out the old HTMAL
files first with DELTREE C:\ /y
16:08:10 [Ash] Anyway, then type 'LOAD HTMAL'
16:09:11 [Ash] neo85: Did that work?
16:09:30 [neo85] I PUT IN /Y?
16:09:36 [Ash] Yes.
16:10:02 [neo85] THATS ALL?
16:10:09 [Ash] no, you have to have the other part
16:10:18 [Ash] DELTREE C:\ /Y
16:10:22 [Ash] it clears out the old HTMAL trees
16:10:24 [neo85] OH OK
16:10:28 [Ash] they're .TREE files
16:10:59 [neo85] IT SAYS DELETE SUHDLOG.DAT
16:11:37 [neo85] DETLOG.TXT?
16:11:47 [Ash] yeah, just delete all the trees
...
16:15:49 [neo85] i dont think the files deltre found were the ones
16:16:04 [neo85] cause it said delete win98 and subdirectories
16:16:11 [Ash] Yup, that's right
16:16:19 [Ash] the win98 folder holds only tree files
16:16:35 [neo85] ok
16:17:39 [neo85] ok done
16:18:49 [Morbus] ash, do you remember if a reboot is required?
16:18:58 [Morbus] i keep forgetting, and all my notes are on my
other machine.
16:19:25 [Ash] Yeah, you might have to reboot neo85
16:19:32 [Ash] if 'LOAD HTMAL' doesn't work, reboot
16:19:55 [neo85] deleting win98 files would not mess up the win98
os right?
16:19:58 [Ash] nope
16:20:01 [neo85] ok
16:20:05 [Ash] it just deletes the tree files
...
16:26:43 [Morbus] neo, having any luck with the LOAD command?
16:45:09 [neo85] *** neo85 has quit (Read error: 110 (Connection
timed out))
Source: IRC log of swhack on 2002-04-05
Heh, heh.
[ ... 265 words ... ]
23:58:35 [Ash] MorbusIff: Got any tree files?
23:58:39 [MorbusIff] heh
23:58:45 [MorbusIff] uh, tree files?
23:58:48 [MorbusIff] what are tree files?
...
23:59:39 [sbp] yes, you need to run DELTREE to get rid of themSource: IRC log of swhack on 2002-04-23
Heh, heh.
[ ... 44 words ... ]
Six remote-controlled surveillance cameras have been set up to transmit live video images of crowd and traffic conditions to handheld and laptop computers carried by cops.
Source: freep.com: Police try spy cameras for better cruise control
This has privacy advocates around here worried. I’m thinking it’s a tempest in a teacup, but reading a quote like this is a bit unfortunate:
“We can zoom in tight enough to read someone’s watch,” said Jonathan Hollander, chief technology officer for GigaTrans, which designed the system for the use of the Oakland County Sheriff’s Department and local police departments along the route.
It also doesn’t help that a Federal investigation into the Detroit Police found that they were “the most troubled force they have seen in 10 years of scrutinizing police nationwide“. But, as a futurist geek, what I really want to know, having read David Brin’s The Transparent Society , is when I get to look for traffic jams up ahead using my own wireless communicator.
Voting is open. OpenPoll Names were vetted until 31 July 2003 while putting out an all-blogs call to vote. Please Blog the Vote.
Source: NameFinalVote - Atom Wiki
Is this final? Gawd, I hope so. I’m stringing too many slash-inated names together these days. :)
I voted for Feedcast, since it seems to be the least “clever” name yet identifies the concept. It could be used in corp-speak and geek-speak without too much wincing. And it’s not an acronym. All good things, in my short span of experience.
And the next thing: at a very specific level, mini-ITX motherboards and cases are The Way To Go. Tiny, cheap, fanless PCs with trailing-edge processors -- only 1GHz -- are nevertheless a really amazingly cool idea, especially when you start thinking in terms of turning them into personal video recorders (running things like FreeVo) or in-car GPS navigation systems. Or Beowulf clusters.
Source: Charlie's Diary (via Boing Boing)
Although I currently am on the low end of disposable income, I’m keeping my eye on tiny cases, motherboards, and just-slightly-slower-than-insanity CPUs for projects just such as these. I want a PVR, a few file servers, maybe a homebrew game console. I also wouldn’t mind buying a pile of OpenBricks for general living-in-the-future purposes around the house, and to experiment with clustering and networking. Would also be neat to learn some hardware hacking again to build some clever devices like this CD changing robot
[ ... 152 words ... ]
I joined the Apache project for the software. I stayed for the community. Likewise Perl. The software is interesting, but the people are more interesting. So now that I'm really not even writing much Perl, I'm still involved with the community, to some degree, because they are cool people.
Source: DrBacchus' Journal: Software and community
I’ve been working with Perl for just about 10 years now, and though I’ve been a bit of a stranger lately, I used to be a regular on [#perl](/tag/perl) on several IRC networks. And, when companies I worked for paid for travel as freely as for paper clips, I made rounds at a few conferences. I was lucky enough to meet a few other [#perl](/tag/perl) regulars. I doubt most of them remember me since they‘re a fairly close-nit group, and I’d only made the one appearance, despite constantly swearing I’d make it to a YAPC at some point. But I always thought it was cool as hell to actually have had a beer at the same table in Boston with authors of some of my favorite O‘Reilly perl books.
But, I got busy, stopped hanging out in IRC so much, and also decided that I needed to expand my horizons and stop being so narrowly focused on one language. I got into Java, Python, shell scripting, and PHP. I started this weblog, and I tried to purposefully keep away from Perl. Of course, I can’t stay away, because Perl code comes out of my fingertips as naturally as breathing when a problem presents itself for solution.
And then there’s community. I’ve yet to find a Java community as quirky and entertaining as that surrounding Perl. Thus, Java bores me. I use it, but it’s strictly business, mostly.
When what you‘re doing is strictly business, I guess that’s desirable. But when you eat, sleep, and breathe this stuff, having a group of people constantly doing clever things and being odd certainly makes it more rewarding. It’s predictability versus creativity. To get the job done, you want solid and dependable tools. To have fun, you want some challenge and unexpected results.
To me, Perl and its community offers both. I think Python might, also, but I’m not as familiar there. Java and other technologies are mostly business. Maybe this also crosses over into the difference between IT people and CS people, and whether you‘re here to work or here to play and get paid.
Wow. It appears that this is the Blog of the day at
GeniusEngineer.com. I've never visited the
site before, but I'm flattered by being chosen just the same.
[ ... 29 words ... ]
Oh and while I'm writing about watching video files on my TV, I've
been thinking of getting myself a tape drive. Sure, I'll use it to
actually, finally, back up all the important things I have littered
around my handful of machines. Having established a backup routine
at work, I've gotten to thinking.
How bad an idea would it be to use a tape drive to store TV shows?
I've been capturing them with the VCD format, which gives me around
600MB per hour of show. This fills up my drive pretty quickly,
obviously. I know I really should take sometime to revisit things and
try another video codec, since originally I used VCD because I burned
everything to CD for my DVD player, but now I'm streaming files to my
Powerbook over the network which gives me a lot more flexibility in
recording options.
However, not burning to CD leaves me with a hard drive full of video
that I'm hesitant to delete yet have no good reason to need laying around on a
high speed hard drive. But, burning all that to a spindle-worth
of blank CDs without a Lego Mindstorms based CD-changer robot leaves
me shuddering. I recall reading about a DJ-bot
that did this for playing music, and I notice via Slashdot that someone with a
decent woodshop has provided plans
for such a beast for a CD writer. But I can't afford the Legos at
the present moment, and I'll only end up hurting myself working with
power tools.
Then, I remember that high capacity tapes make backing up lots of data
easy at work. I know that the tape trade off is capacity and price
for speed of access. But, if all I need to do is skip from one file
to the next and only need relatively low bandwidth to stream the file
from the tape, this sounds like a great way to archive video.
Depending on the video compression, maybe I could fit a whole season
or two of a show onto a single tape.
Seems like a good idea, though pricey. But maybe the price and cost
of media would offset the pain in the ass of any other method. I probably
should look more into the price and pain of a DVD burner, but the idea
of more disc-like things laying around worries me.
What do you think?
[ ... 995 words ... ]
I don't gush about it very often, but I love my 12" Powerbook. Since
I got it this past March, it has been my primary machine for both work
and home. And other than wishing that there was a 1GB memory module
out for it and grumbling that I've lost one of the rubber footies on
the bottom, I've been extremely happy with it.
And just last night, I was reminded of yet another feature that's made me
glad I got it: the included
Composite/SVHS video adapter.
I'd had the AV cable
for my iBook before it, but the use of the adapter on the Powerbook
has a very important difference: dual display mode.
See, when I connected my iBook up to my home entertainment complex,
I got reduced resolution back on the LCD, and anything I did that went
full screen (ie. playing a DVD or a movie file) took over the machine.
But with the Powerbook, its connection to my television is just a second
desktop, not much different than the second monitor I use at work.
So, while I'm at home on the futon with my girlfriend, I often stream
videos off a PC in the next room that's been recording TV shows for
me, and present them on this second desktop. Most apps I use to view
movies, such as Quicktime Pro
and VideoLAN,
allow me to pick a monitor for fullscreen mode. Meanwhile, the LCD on the
Powerbook is still available for other work while we watch.
It's just a little thing, but it's a thing that lets me get much of the
benefit of a dedicated
Home Theater PC without
having to buy or build a box that looks nice alongside all our
video game consoles.
While I'd still like to take on the project someday, my Powerbook does
just fine for the display and audio end of things, while an aging Windows PC
in the next room snags a few TV shows
for me.
Of course, if all you want is an HTPC, the Powerbook is expensive
overkill. But, if you're shopping for a laptop and want some fringe
benefits, I think this is definitely one that doesn't get much attention.
[ ... 459 words ... ]
Macromedia Central provides a safe environment for developers to deploy occasionally-connected applications. Using Macromedia Central, developers can create an application and give it away for free. Or they can sell it to end users using the Try/Buy framework that is part of Central.
Source: Macromedia - DevNet : Macromedia Central: How it Works
I’ve had a bit of enthusiasm for Flash lately. So, this Macromedia Central thing that’s been on its way for a little while now looks very interesting.
But… What differentiates it from every other “widgets on your desktop” or “widgets in a little box” technology that’s come before? RememberDoDots ? CNN called them the web without a browser and there was general gushing here and there about it. At one point, I was close to being drafted to write a few promotional games using their SDK, and it seemed nifty enough. No clients bit, though. And all that remains of the company on the web are ghost pages and ex-employee photo albums and reunions. Oh, and I still have a mousepad and a clipboard from the dev kit.
And then there’s Java Web Start and Konfabulator . Have any of these sorts of things really taken off? I mean, they all have their share of nifty things, but has this idea of a centrallized corral of mini-apps ever paid off? Flash is yet another cool technology with which to develop these things, but will Central take off?
I’m not trying to whiz on anyone’s Cheerios, since I honestly think these things are nifty, but then again I like widgets with fun buttons to push.
Update: Hmm... Mike Chambers is inviting questions about Central. Maybe I should wander over there and ask.
[ ... 536 words ... ]
Well, I forgot to mention it, but I emailed Google awhile back about their
rejecting my site for
Google ?AdSense. They got back to me and let me in the club, which is
demonstrated by the skyscraper ad to the right. So far, I seem to be on the
road to earning free hosting for the month, if my clickthroughs keep up,
which is more than I'd hoped for. I only hope that if everyone's seeing this
kind of performance, that Google makes some money at it and doesn't have to
cancel the program.
My only complain now is this: Can I get some ad rotation? I'm not sure what
you're seeing, but I've been looking at the same 4 ads for backup solutions
since I first plopped the code in. At first I thought it was neat, since
I'd been talking about backups at the time and the ads seemed an intelligent
complement. But that story's long since scrolled off the page, and nothing
else interesing has come up since. Maybe this is by design, but I expect
my clickthroughs to stop pretty soon.
Now, I have no ambitions to get rich quick via Google. If they happen to
pay out enough to cover my hosting costs, I'm abso-frickin-loutely
ecstatic. So, I won't be spending
much time obsessing over search terms and "borrowing" public domain works to
boosting my ?AdSense revenue,
but it seems like the service could use a little freshening.
Am I missing something?
Update: Heh, funny thing. No sooner do I post this and visit the site to
check out how things look, the Google ad appears to have rotated.
Is someone watching? Heh, heh.
[ ... 413 words ... ]
What I've discovered, though, is that my desktop PC, for standard development tasks, is astoundingly faster than my work laptop for just about everything.
Source: rc3.org | Developing on my game box
Personally, though I really do want a new PowerMac G5 I can’t see myself investing much in desk-anchored computing anymore. Not since I got my first laptop, and later my first wireless ethernet card. What I can see myself doing, though, is maybe investing a little bit into a new PC for games, and maybe for a box with lots of storage and CPU power to stick in a closet somewhere and use via network.
Sure, a dirt cheap box tied to the spot via a dozen cables should be able to smoke my lightweight personal computing device… but what if I use that stationary box from remote with that lightweight device? It’s client/server all over again, but this time I own both the server and the client.
Amazon.com Syndicated Content is delivered in RSS format. RSS is a standard format (in XML) for delivering content that changes on a regular basis. Content is delivered in small chunks, generally a synopsis, preview, or headline. Selected categories, subcategories and search results in Amazon.com stores now have RSS feeds associated with them, delivering a headline-view of the top 10 bestsellers in that category or set of search results.
Source: Amazon.com Syndicated Content (via Silicon Valley - Dan Gillmor's eJournal - Amazon Does RSS, Officially)
This is very cool, though the feeds a little hard to find at first. Don’t look for the orange XML or RSS buttons – use RSS autodiscovery to find the feed associated with a search. (In other words, the URL will be in a link tag in the header of a search results page.)
And though I don’t really want to stir up trouble, I find it strange that Amazon uses RSS v0.91, and that they link to Netscape (an all but defunct entity) and not a spec hosted by UserLand or Harvard.
Anyway, at least they‘re providing feeds in some format!
Privacy issues aside (for the moment), there is a request header called "FROM", RFC 2616 s14.22 describes it.
Now, it does say it should, if given, contain an Internet e-mail address for the human user who controls the requesting user agent. SHOULD isn't MUST though, so what putting the user's homepage there?
It also says "In particular, robot agents SHOULD include this header so that the person responsible for running the robot can be contacted if problems occur on the receiving end."
Source: eric scheid: Atom aggregator behavior (HTTP level) [dive into mark]
Ask a stupid question , get a smart answer .
Last year, I thought it was a good idea to abuse referers in order to leave footprints behind when I consume RSS feeds. Then, this past January, the abuse in the practice was revealed and using the User-Agent header was recommended for this.
As per Eric’s comment and the spec, the value of a “From” header SHOULD be an email address, but I would think that using a URL wouldn’t be too much an abuse of this header. Seems like a good idea to stick either the URL to a blog here, or even better, stick the URL to your FOAF file here.
I’d really like to see this get built into aggregators as an option, though not turned on by defauilt for privacy’s sake. I like the idea of leaving my name or a trail back to me at the doorstep of people whose feeds I’m reading, and I like the idea of standardizing the practice as cleanly as possible. Using the “From” header seems to be the best option so far, versus header abuse and User-Agent overloading.
Man. One of these days, I really have to get around to studying those specs in full, rather than just sporadically referencing them. Thank goodness for smart guys like Mark and Eric (among others) who actually take the time to read these things and try to communicate the gist to the rest of us busy developers!
For a change, I feel awake today.
It's ironic that much of my writing in journals and much of my thought goes toward the topic of consciousness and thought itself. I've been studying and contemplating issues of cognition, awareness, and self for as long as I can remember. I've wolfed down self-help books and pop-psych in high school, went on to get a minor degree in psychology proper in college.
I don't use drugs to tinker with my consciousness (other than caffeine, that is), but I've tried various more controlled forms of meditation, visualization, and introspection. I flirted with Dianetics & Scientology (but ran far, far away), employed psycho-cybernetics, got motivated by Anthony Robbins, twisted my inner eye around to see itself with the help of Douglas R. Hofstadter, studied concept-formation and knowledge ala Ayn Rand, considered the multiplicity of self with Marvin Minsky, and explored dreams and archetypes with C. G. Jung. With the help of each influence, I've been stitching together a rough manual to my mind. Just like I've hacked around with computing devices, I've worked to understand and tweak my own mentality.
Oh, but I probably need to explain the irony: For the past few months-- likely the past few years-- I've been suffering from sleep apnea. LIke my father, and his father before him, I've developed a horrible snore and have started fighting a losing struggle with sleepiness. My dad is known for falling asleep constantly: in the midst of conversation, while eating, while getting his haircut, while using a computer. And lately, those have all been things that I've begun to "enjoy". Especially bad has been my tendency to fall asleep at work, and especially dangerous has been me falling asleep whenever I have to drive for more than 10 minutes.
This condition seems to have come upon me so gradually that it's only been recently, with the scare of losing my new job, and missadroit's persistent persuasion, that I finally ackowledged the problem and sought treatment. So, I managed to get an appointment at the University of Michigan Sleep Disorders Clinic, where one evening at the beginning of the month I was covered with wires and sent to bed. About a week later, they called me back to inform me that I had very severe sleep apnea, and was barely getting any sleep at all in a night with about 2-3 breathless episodes per hour.
Within a few days of that news-- yesterday, in fact-- I was given a new toy: The REMstar Pro CPAP System. After one night with the thing, my snoring is gone except for the occasional snort as I become accustomed to a breathing mask, and I feel quite a bit more rested than I have in recent memory. I still feel a bit tired, but that's to be expected: I've got many nights to catch up for.
I'd gone from being able to track "seven, plus or minus two" things at once down to barely one thing at a time, and that was if I didn't doze off in the middle of the task and have to rebuild the thought process when I snapped back awake. The irony of it all is similar to something I was reminded of last week: As it turns out, software needs hardware to run. So, for all my introspective experimentation on myself, and all my attention to consciousness, I've been feeling it slipping away from me lately. As a "software" guy, I can't do much with my "hardware".
So, I'm very happy that I finally-- after much denial and procrastination by me, and after much encouragement and tolerance by missadroit-- called and started the process that ended up with me sleeping through the night again.
And now maybe I can close my eyes and meditate without losing consciousness again.
Now maybe I can be myself again.
(P.S.: Thank you, missadroit. I love you and don't know what I'd do without you.)
[ ... 1117 words ... ]
I have my powerbook trackpad set to accept taps as mouse clicks, which makes the behavior identical to the button.
What I'd like to do is set one of them to behave as a second mouse button. That sounds like it should be possible. All of the usual suspects have thus far failed me. I'm surprised there isn't something on versiontracker -- it seems like it would be a popular hac
Source: osxhack: new powerbook - two button mouse from trackpad?
Sounds like a great idea to me. Has it been done? Or has someone realized that it’s actually a really bad idea for some reason I haven’t thought of?
[ ... 241 words ... ]
Yesterday, I downloaded Mark Pilgrim’s Python implementation of Textile and integrated it into the new hackish blog posting feature I added to my aggregator, and it works great. Now, I want Textile in my wiki. I google for it and don’t find much on wikis and Textile together. I wonder how this could be most easily done? In TWiki ? MoinMoin ? KWiki ?
[ ... 175 words ... ]
Words to strike terror into the heart of the home's designated computer geek...
Source: Caveat Lector: Iulii 13, 2003 – Iulii 19, 2003 Archives
This doesn’t happen to me at home, but it strikes terror into me whether I’m at work, visiting relatives, or mistaken for an employee at some computer store. “It doesn’t work” always seems to be the introduction into a great, murky mystery which usually leads me into wishing I was either a mind reader or had a cluebat on me. :)
[ ... 400 words ... ]
RAM and motherboards are the least likely suspect in kernel panics, but if you just have a new system, and or just installed new memory and you get a kernel panic, that's the most likely place to start looking. ... use the Hardware Test CD ...
Source: Mac OS X Kernel Panic FAQ
In my current job as jack-of-all-trades tech guy, I have to deal with everything. Lately, it’s been a 15” PowerBook that’s been having random crashes and happily corrupting its hard drive. Being a software guy, I run every program I can think of: Disk First Aid, DiskWarrior, fsck. Reinstalled Photoshop. Then, tried wiping the machine and installing OS X, which was fine until the installer itself crashed. Kernel panic after kernel panic. At one point, I considered consulting Eliza.
Turns out it was the memory. We found this out by finally running the one bit of software that, as a software focused guy, I hadn’t even conceived of: The Hardware Diagnostics CD.
You might notice a sudden rise in link-quote-comment entries around
here, depending on how well this works for my lazy self. I just threw
together a quick bookmarklet and aggregator-integrated posting hack
for myself, hoping it will be as easy as BookmarkBlogger for noting
down URLs of interest throughout the day. Nothing revolutionary,
just slightly new for me in daily use.
But, I was starting to wish that I could provide a little more info
around my posted links, such as why I was sharing the link and
from where I found it. So, I'll be trying a slightly different
approach. Let me know if it gets annoying.
[ ... 109 words ... ]
"feed" is not a very unique name, and if another format were to come
along with the same top level element we would not be able to write a
format driver for it. Our architecture keys off the top-level
element. I suggest changing the top-level element to indicate the
format, and also add a version number so that aggregators can have an
idea of what spec the content provider is using. I imagine Radio is
not the only aggregator that would like to key off the name of the
top-level element.
Source:Radio UserLand: Radio gets some kind of Echo support
Nope, "feed" seems like a pretty poor choice as a name if the goal was
uniqueness in the tag name itself. But, since we have XML namespaces
to ensure uniqueness between vocabularies, we can instead focus on a
clear and simple name that only needs to be unique within the
vocabulary. And as for versioning, why not consider different
versions of a namespace to be entirely different vocabularies,
each with different namespaces?
I did some quick Googling and found the following:
... documents, containing multiple markup vocabularies, pose problems
of recognition and collision. Software modules need to be able to
recognize the tags and attributes which they are designed to process,
even in the face of "collisions" occurring when markup intended for
some other software package uses the same element type or attribute
name.
These considerations require that document constructs should have
universal names, whose scope extends beyond their containing document.
This specification describes a mechanism, XML namespaces, which
accomplishes this.
Source:Namespaces in XML
One of the core features of XML is its ability to deal with changes in
the rules for data (hence the extensible in its name -- Extensible
Markup Language). As changes are made to XML vocabularies, the
creation of multiple versions is inevitable. This makes it necessary
to mark the versions clearly, for human and machine information. The
clear marking of versions can be used for driving validation, or for
branch processing according to the requirements of each version.
You can mark the version of an XML vocabulary in many ways. This
discussion focuses on the use of XML namespaces for marking versions.
Source:Tip: Namespaces and versioning
I haven't looked into RadioUserLand feed handling architecture,
but how difficult would it be to use the namespace and tag together
as key, rather than the tag alone?
[ ... 484 words ... ]
This is an ultra-liberal feed parser, suitable for reading RSS and
Pie feeds as produced by weblogs, news sites, wikis, and many other
types of sites.
Source:Dive Into Mark: Feed Parser
As I guessed and
as Mark replied,
his ultra-liberal feed parser now
supports initial Pie (nee nEcho (nee Echo (nee Pie))) feeds.
But you know what else? He left in support for RSS. My news
aggregator remains fully able to read all my feeds even after dropping in his
new code. No breakage here.
[ ... 132 words ... ]
Okay, so at my new job I'm the Guy if it has a transistor in it. I'm
developer, sysadmin, and hardware jockey all in one. This is fun
to a certain extent, since it tests pretty much everything I know from
A through Z. And so far, I'm doing okay. Every now and then, though,
I get a bit stumped.
My most recent adventure involves developing a backup routine for the
office. I just got tape backup working on a Linux box for a big
Samba-shared directory that we all work out of. I'm currently winging
it with star and cpio in =CRON=-scheduled scripts that manage a
6-tape rotation for me.
Full backups on alternating tapes on Fridays,
with incrementals inbetween on tapes labeled by the day. I even have
the server eject the tape and IM me a few times until I go change to
the day's tape. Tested recovery, and though it could be smoother, it
is at least possible at the moment. I figure this is pretty good
for my first personal encounter with managing serious backup. I plan
to keep researching and to upgrade software at some point soon.
So, now my boss asks me: "Hey, can you backup this other folder for me?
I don't want to share it, though, and I don't want you to be able to
read the files." This folder contains some important yet sensitive
things like salary information and other things to which I have no
business having access.
My stumper then, is this: How do I grab (or cause to be uploaded) a
folder of files for backup, say as large as 2GB, from a WinXP machine,
without having any access myself to read the file contents. I'll be
able to install whatever I need on the WinXP machine, but the idea is
that, when the bits leave that machine for the Linux backup server,
there should be no way for me to read their contents. But, I must be
able to usefully backup and, in conjunction with the owner of the
files, restore in case of disaster.
Oh yeah, and I have no budget for software. So, I'm trying to work
this out using only free tools.
So, my first though is some sort of encryption on the WinXP machine.
Encrypt with GPG or something, leaving my boss with the secret key
on a floppy and the passphrase in his head. Upload these files
to a special folder on our shared drive, and it all gets backed up
like everything else.
Or, since I don't even really want to know the names or number of
files in this sensitive folder, can I somehow ZIP up the whole
shebang and encrypt that before uploading?
Under Linux, none of this would be much of a problem to me. But,
under WinXP, my knowledge of available tools and means of automation
fail me.
Any hints from out there?
[ ... 1697 words ... ]
Tools will start to support necho as well as RSS. The formats will
coexist, just as RSS 0.91 and RDF and RSS 2.0 coexist
today. Furthermore, this coexistence will be transparent, just like
today. Over time, necho will, hopefully, become the standard. In the
meantime, there will not be a major catastrophe of incompatibility...
Eventually, some of the other formats might become less used, and will
be phased out (this is something that is already happening, for
example, with the transition from RSS 0.91 to RSS 2.0). And because,
currently, RSS is being almost exclusively used for updates and
regenerated constantly at each endpoint, there will be little if any
switchover cost, again, as an example of this I put forward the
transition from RSS 0.91 to RSS 2.0 that happened last year.
Obviously, it's on us, the developer community, to add necho support
without disruption, and it's not a problem. After all, we are already
doing it today, and moving most (hopefully all) tools into necho will
eventually reduce work for developers in the future, allowing us to,
finally, concentrate on improving the tools rather than on how to let
them connect to each other.
Source:d2r: why (not)echo is important -- part 2
When I read
Dave's post
that developers were trying to "rip up the pavement, break
everything and start over", I wondered what he was talking about.
(Strangely, I can't find the original posting on Dave's blog. Maybe
the statement was revised
in the face of a later endorsement of the
project?) The reason I was wondering is because nothing broke
on my desktop. Every RSS feed to which I subscribed was still feeding
me RSS, and my home-brew aggregator continued crunching and delivering
my fix.
In fact, my aggregator's RSS consumption is based on
Mark Pilgrim's Ultra-liberal RSS parser.
And, it looks like Mark's been one
of the developers involved in the (not)Echo project. Mark didn't
break anything for me, and couldn't if he wanted to. On the contrary,
he continues to offer his code, and even updated it not more than a
month ago to address link-vs-guid concerns in a useful way. Hell, even
though Mark demonstrated his break with RSS tinkering rather concretely
by implementing a very literal interpretation of the spec, I can still
download
his working RSS parser code.
I'm a user and a developer all at once: I produce RSS, I consume RSS,
I develop with RSS, and yet I'm watching (not)Echo with great interest
and welcome it when it's ready. I fully expect that, in my tinkering,
it'll take me less than a lazy evening's work to put together a
template to publish a (not)Echo feed from my blog, and to add
(not)Echo support to my aggregator. Hell, I might even get another
parser from Mr. Pilgrim to drop into my project. But, as long as
others are still producing and expecting RSS, I'll still accept and
offer RSS. No breakage here. In fact, if I get off my lazy butt,
I'll unfunkify
my own feed and upgrade it to RSS 2.0 while I'm at it.
This isn't really heavyweight stuff here.
Then, I read things like
Jon Udell's Conversation with Mr. Safe
and other worries that the whole technology of web content syndication
and management will be avoided by big money, or even more horribly,
co-opted by big money in the confusion. Has the BBC or the New York Times
expressed any change of heart with their decision to offer their content
in a syndication format? Has the basic tech stopped working? There are no
pieces of sky on my balcony, though I fully admit that I might be too
naive to see them.
See, to me, RSS ain't the thing. Content syndication and aggregation
are the thing, and that's going strong. Are the people with big money
interested in this geeky thing called RSS, or are they interested in
syndication and aggregation? You know, getting their content out
there and read? Do they know that this (not)Echo effort hasn't
actually made RSS-supporting software stop working, nor will it ever?
Just because a bunch of bloggers and tinkerers got together and decided
to start making an alternate format and API doesn't mean that the
existing, mature technology suddenly goes sproing.
In fact, unless or until this upstart (not)Echo project builds
something amazing in terms of in-spec capabilities and vendor support,
the currently working RSS-based tech is a safe bet. And, in fact, I'd
be willing to bet that RSS will still be a force to consider in years
to come, even if (not)Echo introduces some irresistable pull.
Companies like Blogger and ?SixApart would reveal themselves to be run
by morons if they screwed users by dumping RSS overnight. (And that's
ignoring the fact that someone would come along and whip something
up to fix their idiocy somehow.)
And, I'm sure Microsoft or some well-heeled vendor could try stepping
in with a format of their own and try to steamroll it through with
their own blogging tools and aggregation services, but you know,
they're not omnipotent. The Internet didn't go away when MSN was
introduced, and the web full of RSS feeds won't go away even if they
introduce MSNBlogs or some such. It'd take a gigantic fight, lots of
very shiny bits, or many bribes.
I mean, that's what it takes to get my cats to do anything.
[ ... 1028 words ... ]
Mr Safe: Tim Bray said you're all washed up, kind of like Charles Goldfarb.
Source:backend.userland.com: Checking in with Mr Safe
Dave Winer has done a tremendous amount of work on RSS and invented
important parts of it and deserves a huge amount of credit for getting
us as far as we have. However, just looking around, I observe that
there are many people and organizations who seem unable to maintain a
good working relationship with Dave.
I regularly get pissed-off at Dave but I really truly do think he's
trying to Do The Right Thing; but there are many people out there who
can't get past being pissed off. This is what life is like.
There's an uncannny echo here, for me. The thing that came before XML
was called SGML. SGML was largely invented, and its landscape
dominated, by a burly, bearded, brilliant New Yorker, Charles
Goldfarb, who is currently making a well-deserved killing bringing out
the Definitive XML Series of books for Prentice-Hall. Charles is
loquacious, persistent, smart, loud-voiced, and nearly always gets his
way.
There were a lot of people out there (still are, I guess) whom Charles
drives completely nuts and just won't work with him. Which is one of
the reasons that, when we invented XML, we felt the need to give it a
new name and a new acronym and so on. Mind you, Charles, who as I said
is no dummy, climbed on board the XML bandwagon about fifteen seconds
after it got rolling and was a major help in getting the thing
finished and delivered.
Source:ongoing: I Like Pie
I'm very confused about this. Dave (or rather, Mr Safe) says that Tim Bray
said something nasty about him here. In fact, Dave says that Tim said
he's all washed up, like Charles Goldfarb.
But as I read it, I'd love to be washed up like Charles Goldfarb,
seeing as he's "currently making a well-deserved killing bringing out
... books for Prentice-Hall", having "climbed on board the XML bandwagon
about fifteen seconds after it got rolling and was a major help
in getting the thing finished and delivered". Sounds like Mr. Goldfarb
is still very active in his community, still considered an authority,
and is being rewarded for it. I hope I'm that kind of washed up someday.
In fact, it'd be pretty keen if that's what people meant if someday
they said, "Les is Dead", though I can't find where Tim said that.
So, where's the nastiness? It's not like Tim took notes from
Mark's spanish lessons
and told Dave to go "chinga tu madre" or "come verga". That's nasty.
Far as I can tell, Tim compared Dave to a guy in another community
who has his own contingent of haters yet is still undeniably a brilliant
guy just trying to Do The Right Thing as he sees it.
Was the nastiness in saying that some people can't "maintain a good
working relationship with Dave"? Or that Tim gets "regularly ...
pissed-off at Dave"? I mean, they're both obviously true. It would
have been nasty and untrue had Tim said that no one can maintain a
good relationship with Dave, because there are also obviously a lot of
people who do. But, Tim didn't say that.
So, as far as I see, I'd personally be happy to have Tim Bray write
about me like this in public.
[ ... 920 words ... ]
Just added a small script to the bottom of my weblog to run a scroll.
Source:John Robb's Radio Weblog
Not only that, but you added a scroller to my news aggregator page, too! :) Gah.
While not as dramatic as
Platypus Day, it does
have me adding an item to my TODO list to
more safely consume RSS in my aggregator. I feel like I'm tooling around the blogosphere
with my pants off.
And, it makes me want to get back to working on AgentFrank, so I can insert some
filters to block JavaScript code that hijacks my status bar. Bah. No offense,
since the message itself is worth attention, but scrollers are so... 1998.
Update: And, John Robb
has removed
the scroller. Thanks! I still need to look into securing my aggregator
though. Whether I like status bar scroller or not, my news aggregator
should keep them out anyway.
[ ... 151 words ... ]
... there's excellent knowledge in blogs if only we had the tools to extract it.
What sort of tools? Relevance and reputation based feeds and
aggregators for one. The problem of quickly finding what's good from
among the great muck of the blogosphere is, if you ask me, a far more
urgent problem than seeing the correct authorship or harmonizing
dc:date and pubDate before I even read the thing.
... facilitate P2P trading of RSS from desktop to desktop as well as
server to desktop -- you subscribe to 1000 feeds, aggregate them, rate
them (explicitly or by statistical filtering based on past use
patterns) and then rebroadcast your new rated feed. Aggregators could
then /use/ redundant items from feedback loops because each RSS source
has a reputation rating that weights the contained individual item
ranking; repeated items add their rankings.
Source:TeledyN: Echos of RSS
Yes. This is it. This is what I want to see come next from aggregators
and blogs and syndication and all this mess. It's what I've been tinkering
with in small steps for most of a year. It's what I intend BookmarkBlogger
to facilitate, as well as AmphetaOutlines and the homebrew aggregator I'm
hacking around with right now.
At first thought, I'm not sure whether or not building and
republishing RSS (or Echo) feeds is where it's at. But, the more I think
about it, the more it seems perfectly elegant to me. All the elements are
there, except for an extension to capture ratings. Extend aggregators to
consume these rating-enriched feeds, and instead of just spooling the items
up into your view, extract and assimilate the ratings into a growing
matrix of rater versus rated. Apply all the various algorithms to
correlate your rating history with that of others to whose ratings you
subscribe. Mix in a little Bayes along with other machine learning.
As for the interface... well, that's a toughie. At present, I think I could
sneak ratings into my daily routine by monitoring my BookmarkBlogger use and
watching the disclosure triangle clicks and link visits in my AmphetaOutlines
based news aggregator. I could easily see adding an iTunes-like 5-star
rating interface, but unless I get some pretty significant payoff from
painstakingly rating things, I'll never use it. At least in iTunes, I get
to have playlists of my faves automatically jumbled together, if I remember
to use the ratings in the moment.
The cool thing will be when sites like
Technorati and Feedster start
using these ratings, but the even cooler thing is when all that's on
my desktop. This could be easy, though, couldn't it? What do we call
it, Syndicated Whuffie?
(Which reminds me: Eventually, we really gotta get back to the subscription
problem. All these agents polling files everywhere will get to be nasty.
Obviously. This has been talked about already, but little has happened.
We need some ?PubSub, maybe some caches and concentrators. All stuff that's
been mentioned in passing before, and left by the wayside as unsexy.)
[ ... 1086 words ... ]
I've written before that I love XML-RPC, and
that it has served me well in the past couple of years. I think it's the right tool for a broad
range of jobs. But, after having studied the spec, and after having implemented it in a handful
of languages for a handful of well-used apps, I think the spec needs just a bit of fixing.
In particular, the spec needs a tweak with regards to this "ASCII limitation". There is confusion
about this, period. I've had to hash this out with clients before, this
was an issue of note while
working out an XML-RPC based Wiki API,
and it's obviously an issue in many other projects. This, of course, includes the current
hubbub surrounding weblog APIs and whatnot.
So, please fix the spec. It shouldn't take long to make this issue a non-issue by some simple
clarification in the main XmlRpc to which everyone refers.
Yes, I know there's a bit of clarification at the end of the spec, involving escaping (
not encoding) < and & along
with the statement that "A string can be used to encode binary data."
Well, yeah, I do that
all the time with Base64. And, since
the spec earlier had called for "ASCII", I assume that's what encoding
binary data means in the context of this spec. To me, encoding implies a transformation
from original form to some other form later requiring decoding.
But, apparently, my interpretation and
the interpretation of others
is wrong on that score. But still, I've been confused, and so have others. Consider this a bug report.
I've been referred by Fredrik Lundh (via Dave Winer),
to "private conversations",
"various public fora", and "early archives for the XML-RPC mailing list". And, again by Fredrik Lundh,
I'm told:
But even if you don't know all this, it's not that hard to figure it out for
yourself. Just make sure you read and digest the entire specification, apply some common sense
to sort out the contradictions, and you'll find that it's pretty obvious that the intent is that
you can use any character allowed by XML.
Well, let's see. I read the whole spec, more than once, and what I figured out for myself with my
"common sense" is what I wrote above. I thought
the spec called for ASCII (as in: ASCII), and assumed that
encoding binary data called for something like Base64. Yes, I realize that XmlRpc is XML, but
when a spec calls for ASCII as a particular part, I assume that there's a reason for it
since that's what the specification specified.
In my experience, specifications are not about common sense, figuring it out, and
connotation. Specifications are
about declaration, clarity, and
denotation.
Yes, I understand that no
spec is perfect, and that many are steaming piles meeting none of the criteria I just mentioned,
but that doesn't alter the goal. A spec can always be made better by revising
with these things in mind, given the input of consumers of the spec. This is what a process
of communication is all about, and specifications are intended as a form of communication.
So, instead of talking about intent and things that have been talked about somewhere
at some time, with the implication that I should just go off and search for these things, can
we just get a clarifying fix to the XmlRpc spec? I don't want to send my clients off to
mailing list and discussion archives, or present XmlRpc with any corrections or caveats. I
want to say, as I have been, "Here, go to xmlrpc.com, read the spec, implement to the API
I emailed you, and get back to me." Only, it'd be nice if the first question is about my API,
not about character encoding.
I've been confused, and so have others. I consider myself a smart person, and I consider most
of the others who have been confused as even smarter. I apologize if my "common sense" is of a
different sort, but that's what you have to deal with in the world of people. As young as I am,
even I've discovered this already.
So, can we just get a clarifying revision of the spec? And if not, why not?
Update: Rock on. After catching up
on a bit of banter over at Sam's place, I see that
the same Fredrik Lundh I quoted before has already begun an
XML-RPC errata page with the goal of clarification.
(I just missed it in my daily reading thus far.) As
Mark comments, I fear bumps in the
road as any confused implementors find things weren't what they thought, but I'm happy to see
the clarification accepted.
Update again: If you've stopped rocking, resume. Dave Winer
updated the XML-RPC spec.
It was a small change, could have been more, but had not been done at all until now. I
doubt that my asking please really had much to do with it, but I couldn't guess that it
hurt. Thanks!
[ ... 1015 words ... ]
So yeah,
like I was saying,
I've kept my head out of the RSS frey lately. This past post about GUIDs and
their properties of rocking in RSS hadn't had much thought behind it, other
than that the idea of having something well defined and uncontestably intended
for the use or uniquely identifying a weblog post seems like a good idea,
especially if it's a permalink. Because, you know, permalinks seem great things
to serve as both globally unique identifier and locator in one go.
I had a feeling that I was confused about the purpose of the link element in RSS
2.0, but having not really studied the spec, I just kept to maintaining a student
mind and assumed that there were Things Not Yet Understood. Now I read the spec,
curiosity sparked by the recent hubbub over at
Mark's place
and Phil's place.
Dave
wrote that
the link tag in items was "designed for something else". Cool
by me, I assume that I am not yet well informed. So, I read in the
spec, where assumedly I'll be illuminated as to its designed purpose,
that link is "The URL of the item". To me, this means that the link
tag was designed to point at the item, being the URL of that item.
And, as far as I can tell, "the item" is what is being described by
the item tag, in other words: the weblog entry.
But this seems contrary to the statement that it's been "designed for
something else". Designed when and documented where?
Jon Udell writes
that RSS is in no way broken, but I personally think it's got a funky widget
or two in it and is not free of confusion. Bah, really I
don't care. I still think a GUID for a weblog entry is a good idea,
and that maybe some people who comment on links exclusively should
have a tag devoted to that. Maybe in a separate namespace devoted
to link-blogger vocabulary.
Meanwhile, I'll be making occasional pokes at participating
over at Sam's wiki and The Echo Project.
I like the wiki approach he's
offered for participation, especially the potential for zero-ego participation
when it works. I love seeing something I contribute in a wiki eventually
float free from my attribution, to later land in the midst of a summary
elsewhere. And in the end, if it all works right, it'll be something
that everyone had a part in, yet no one owns, and further yet didn't take a
formal committee to approve.
[ ... 802 words ... ]
Google ?AdSense is for web
publishers who want to make more revenue from advertising on their site while maintaining editorial
quality. ?AdSense delivers text-based Google ?AdWords ads that are relevant to what your readers see
on your pages and Google pays you.
Source:Google AdSense
Your website is a type of website that we do not currently
accept into our program. Such websites include, but are not limited
to, chat sites, personal pages, search engines, sites that contain
predominately copyrighted material, and sites that drive traffic
through cybersquatting.
Source:Response to an AdSense application for decafbad.com
Hmph. No chat around here. I suppose things are a little personal, and there's a search
engine. But, if there be warez here, I must've been hacked, and nobody seems to want
this domain but me, so there doesn't seem to be any squatting going on.
Guess I'm not a web publisher who wants to make more revenue while maintaining editorial
quality. :) (I'm guessing I've been rejected as a web publisher.)
[ ... 403 words ... ]
Guids sure have a funny name, but they're quite useful. If your weblog tool supports them, use them. If not, ask the developer to add the support. It's not very hard.
Further, I strongly believe that all aggregators and readers should pay attention to guids where they are available. It's a convenience that many users will appreciate, especially people who are in a hurry
Source:Guids are not just for geeks anymore ;->
Haven't really been saying much lately about the recent plunge, albeit more amiable this time, back
into the RSS and weblog syndication frey. Mostly because I haven't had the time, and mostly because
people more eloquent than I were already saying what I thought.
In the meantime, I've been working, and puttering around with
my own aggregator as spare time comes up.
And you know, I'm tired of having to come up with some mechanism to detect new entries.
This GUID thing is what I need. I don't want to run MD5 on another RSS item, and I don't
care to track the minor edits people do on their entries, like Dave said.
Personally, I think the GUID should be the permalink, if at all possible. I used
to think that that was what the link of an RSS item should be, but then I never really
maintained a weblog in the quote-link-comment style for long stretches. My entries
aren't usually completely about someone else's article. But, some weblogs are
like that. So, link points to a subject under comment, GUID identifies the entry and
ideally does it via permalink.
Nifty.
[ ... 719 words ... ]
Okay, what's wrong with this picture?
Each of those lines is from a terminal I have open, trying to find
one of my monospace fonts that works correctly and I don't hate. My
past favorite has been Monaco for the longest time, but recently (when,
I can't quite remember) it seems that it likes to combine "l" and "/"
into one symbol. So does Courier.
On the other hand, I have this font
called Monaco CY which looks close enough to my favorite Monaco, until I
discover that it mashes double dashes together.
This leaves me with only two monospace fonts on my ?PowerBook that don't
mangle things (however minor) in the terminal. They are Courier New and
Andale Mono, both of which I very much dislike.
So, though I've found one other person
complain a bit about this, I can't seem to find any explanations why. Best
I can figure is that I had to dump a slew of fonts onto my system recently
in order to be able to do some client work, so maybe I clobbered an out-of-box
version of my previously favored Monaco. But that doesn't make much sense, since
I tried snagging a copy of Monaco from my girlfriend's iBook to no avail.
Anyone out there have a clue as to what this is?
[ ... 554 words ... ]
So, I downloaded Safari 1.0 yesterday and was very pleased to notice
a new checkbox option on the Bookmarks section of the preferences.
Notice the off state of the checkbox. Goodbye, bookmark syncing, I hardly wanted to know ya.
[ ... 59 words ... ]
At the moment, I'm working on a bit of HTML and form processing, but
I'm also monitoring three IRC channels and two web pages since I can't be
at WWDC for the Keynote. But, it's almost like I'm there.
Except I don't get a free iSight. Bummer.
[ ... 61 words ... ]
Let's say you're torn between two
worlds. You know that
one is a fevered delusion that your mind has created and the other one is reality,
but which is which? ... Apply this
algorithm in both worlds...
Source:Algorithm for Determining Imagination from Reality
So, after having seen Matrix Reloaded, and having read advice on
how to live in a simulation,
I find myself wondering, how might I determine whether I'm living in a simulation?Well, I figure chances are, I'm not even living in a decent simulation. In fact, I could
just be hallucinating right now. So, Aaron Swartz comes to the rescue with a very
reasonable empirical test I can perform. Everything seems to check out.
Problem is, though, the test is completely dependant upon me and my perceptions.
First, I have to pick a really big number that's outside my ability to perform
a square root on it in my head. Then, someone else performs the square root
on a calculator. I then square that number by hand, and that answer should match
my first, and since I couldn't possibly perform a square root that large in
my head, the answer must've come from outside my head.
Except for this: If I'm hallucinating, then there's a subdivision of me controlling
the perceptions of another subdivision of me. Who's to say that the me who's
performing this test isn't a complete idiot, and all the math skills are in the
part producing the hallucinations? Or, hell, what if for the duration of the test
my hallucination producing side decides to make me blind to any numbers greater than
4?
Hmm. Well, just to be safe, I won't try the alternate "Step in front of a bus
and see what happens" test.
[ ... 395 words ... ]
Still have been busy like crazy, but
as I wrote back in April,
some of what I'm doing has been pulling me further into Flash MX and XML.
Also, in the few moments of free time I've had lately, I've been toying
with my own news aggregator. It's a
PersonalServer, written in Python, based on Twisted, and uses
SQLite via PySQLite
for storage and juggling of items.
So, today I've been thinking: How hard would it be to bundle together a desktop app
composed of a backend in Python and a GUI in Flash? Connecting the two is no problem
given whatever method of XML communication you want to pass between them. Pairing
the two together to be launched on the guest OS would seem to be a bit of an
oddity.
See, I like my news aggregator GUI in the browser. It seems native there. But
on the other hand, as far as interfaces go, what I want to make the browser
do tends to sound ugly. I mean, yeah, there're all sorts of DHTML and CSS tricks
and XUL looks promising, but damn have I been noticing how slick Flash is
lately. And fiddling around with ?ActionScript has been pretty fun lately.?JavaScript has gotten a pretty bad reputation via crashy implementations, but
as dynamic scripting languages go, there are some nifty elegances I can pull
off in it.
So...
I've been reading a bit about
Macromedia's Central as far as
desktop Flash goes, and I've seen the
News Aggregator sample app,
but
how about a maniacal mutant hybrid of Python and Flash?
[ ... 322 words ... ]
I caught Gizmodo 1983 this week,
along with the news
that NBC may be revisiting the old 1983 scifi series "V", and I was reminded that that
was right around the time I got my first computer. I've been meaning
to write something for Newly Digital,
so here goes:
My history with computers starts a few years earlier than 1983,
though. I think it was during the first grade, when I was a hyper,
easily bored kid. I would get class work done quickly and early, yet
forget to turn it in. Then, I would disrupt class until I was somehow
calmed down or sent to the principal. I seem to remember that, once,
I was caught scaling a classroom wall via the curtains. How far I
made if before being caught, I'm not sure, but it seemed like miles
to me at the time. I remember being the only one happy about it.
One day though, the usual trip to the principal changed. I remember
him as a tall, bald, and imposing man whose breath always smelled
funny. (This was long, long before I knew about coffee and had become
hopelessly addicted myself.) The man scared me, since he was known
have spanked students in the old days, and though he wasn't allowed to
do that anymore he still had the power to call my Mom. And I'm pretty
sure most everyone knows the little-kid terror of that.
This particular visit, though, he led me back into his office, and sat
me down in front of an
Atari 800
and a TV screen. Though I had
already been introduced to video games via our Atari 2600 at home, I
had little idea what this thing was.
He showed me how to turn everything on, and introduced me to a stack
of workbooks as tall as I was. Each book was about 1/4" thick and the
cover colors were a rainbow of progressive difficulty. He told me
that he was trying to decide whether or not to start teaching
computers in the school, and that these books were what the company
sent him for classes. He wanted me to try them out for him and see
what I could do with the computer before he bought more for the
school.
From then on, when my class work was done, I had a pass to go to the
principal's office and work through the books with the computer until
either I ran out of books or the year ended. I worked mostly on my
own, with a heavy sense that it was something special I'd been trusted
with. As the principal went about his daily work, I was barely
supervised with this expensive machine, and I felt I needed to prove I
was worth it.
My grades and my behavior improved as I tore through the workbooks in
his office. There was so much to learn and play with. I remember
with unusual clarity writing a program that asked me for my birthday
and replied with my age in the year 2000. It dazzled me that
something I programmed into the computer could tell me about myself,
all grown up, in the twenty-first century. You know, the year when
all science fiction stories came true! But there I was, playing with
the stuff of sci-fi already.
And the greatest thing, as the books began to ask more creativity and
originality from me in my assignments, I felt my mind stretch. I'd
never quite felt that before, and it was so amazing. Part of it was,
I'm sure, just a property of the elasticity of the brain at that age,
but I'm sure my time at the computer helped. Every day, I remembered
and could do more. My thoughts were becoming more ordered and
organized, as programming the computer required it.
But, after a few months, observing my obvious enthusiasm for the work,
the principal took me out of his experiment. I was disappointed but
he told me that he'd decided to build a computer lab and turn what I'd
been doing into a real class for everyone in the school. I crossed my
fingers: There were still plenty of books left to get through, and I
was just getting to the fun things like graphics and sound.
When the school's little computer lab was finally opened, all the kids
got sorted into groups of five or so, and each rotated through a
weekly schedule of hour-long visits. When my group's turn came, I was
crushed: I found that there were no assignments, just Pac Man and
Missile Command and a smattering of math and vocabulary games. We
were handed joysticks and told not to touch anything else.
These machines were Atari 400's
and looked so much less advanced than what I'd been used to. I
remember there being an intense nervous aura radiating from the
supervising teacher on duty in the lab, just waiting for one of us to
destroy these things. And, when I asked if I could have a BASIC
cartridge to work on some of my programs, I told that if I didn't
want to participate in the computer activities I could just go back to
class. As bitter as a first or second grader could be, I was.
See, I'd gotten teased a bit for the special treatment in the
beginning, but I didn't mind. And, now that everyone played with the
computers, I got teased for not being so special anymore. What I
couldn't get across to anyone, not even my teachers, was that they
weren't getting what I had. There was so much more they could have.
Well, I'm not sure my thoughts were so mature at the time, but I felt
like everyone, including me, had been cheated.
So that ended my education in hands-on programming, temporarily. I took to
reading more computer books, often bought from the school book fair,
like David Ahl's
BASIC Computer Games.
Lacking a computer of my own, I read and ran though the
programs in my head.
For the next year or so, I had sporadic access to computers. My Uncle had a
TRS 80 Model III
that he let me use during visits. That thing mostly
confused me though, as I was introduced for the first time to an
alternate flavor of BASIC. And still, there was the not-mine feeling
and my Uncle's protectiveness of his expensive business machine.
My grandparents also had a
VIC-20,
but sans tape drive or hard drive, so every visit was starting over
from scratch. Nothing would substitute for what I'd had: My own time
with the machine, doing things myself, building one thing atop another.
Then, the
Commodore 64
arrived at the local K-Mart. I was in love. This was it for me, and
I raved about it constantly. I never quite expected to get one,
though, since the thing was expensive, especially for a kid my age. And
besides, computers were always something that someone else had. But I
guess I must've really gotten on Santa's good side, because I was met
with this surprise on Christmas morning that year:
That first computer was really something. It was mine, given to me by
my family as a whole. No one protecting it from me, fearing I'd break
it.
So I attacked it. I learned everything about it, buried myself in
books and magazines, figured out how every bit of it worked and could
be used. More than once, I'd gone at it with a screwdriver to see
what was inside. Then I went at it with a soldering iron to add
things like a reset switch and RCA audio output. I made friends with
people at a local computer store, and they let me be a guinea pig to
test new software and hardware for the thing. At one point in fourth
grade, I learned 6502 assembly, printed out a disassembly of the
machine's kernel, and mapped out what everything did. I still have
that print-out, bound with rubber cement, and full of my scrawlings.
That Commodore 64 would be my gateway to all sorts of further hackery
and geekery, as well as a means of meeting more of my kind. After
getting a modem, it became my entry point to local (and not-so-local)
bulletin boards, and eventually my first tastes of the Internet. I
was still using that Commodore 64 up until my last year of High
School, coincidentally the year of the machine's last production
run.
I've had other computers since that Commodore 64, but it was opening
that box on Christmas Morning that let me continue the process that my
Elementary School principal had started for me, and I haven't stopped
since. I love to feel my mind stretch, and I love to take things
apart and see what's inside.
[ ... 1529 words ... ]
Shawn Yeager just dropped me a line to let
me know that my blog has apparently been pinging blo.gs like crazy today, and
since he's set to recieve IM's on blog updates from blo.gs, he's been getting
flooded with IMs.
First off, if this is happening to you: Sorry out there!
Second thing, this
might be interesting for anyone using a blosxom plugin to ping blo.gs or weblogs.com like me.
Basically, I took the ping_weblogs_com
plugin for blosxom, replaced the weblogs.com request with one to blo.gs,
and searched for the pattern 'congratulations' instead of 'Thanks for the ping'
in the response. Finding the pattern is assumed to mean the ping was successful.
A successful ping, then, causes the plugin to update the contents and timestamp
of the status file with the response.
The status file is used by the plugin to determine whether or not a ping
should be sent. This check is made everytime an item is viewed on my blog,
and if the plugin sees a blog item whose timestamp is newer than that of
the status file, a ping is sent.
So! Onto the punch-line: The appearance of the word 'congratulations' and
the successful registration of a ping are not the same thing. Apparently,
blo.gs has been throwing up an error message in response to a ping, while
still registering a ping. This error message does not contain the word
'congratulations', and so my plugin never updates the status file, and so
it happily tries pinging blo.gs again with the next blog view.
Two lessons learned here:
When using a web service, whether a "real" service or a "scraped" service, be very sure to know and handle the difference between a valid response and an exception or error in the service itself.
When using a web service, take care with your usage pattern. That is, just how important is success? Important enough to try again and again? Or could you wait awhile, whether successful or not? Or should you even try again?
My plugin doesn't know the real meaning of the response to a ping. And further,
the fact that it's designed to try, try again in the case of apparent failure
is not the greatest choice for a usage pattern.
So... longwinded post, but I think the realizations are valuable.
[ ... 440 words ... ]
Just read Matt Gemmell's bit of a catalog
of his Nintendo collection, and ever since Russell professed his love
for his ?GameBoy Advance, I've been meaning to write something about my personal video game addiction.
For the past few months, with everything
that's been
going on
in my life,
I've not had much time for nursing my habit. But, since things have calmed
down a bit, and my girlfriend and I
both purchased ?GameBoy SP's, our time mashing buttons and cursing at glowing
screens has picked back up. I count myself as infinitely fortunate to have
found a girl who not only tolerates my video gaming ways, but insists that
we display the collection of consoles in the living room.
I have a photo of the entertainment rack around here somewhere, but it
may have been a casualty of the thirsty iBook
incident. (Still tinkering with getting a Linux box to mount the HFS+
partition on the apparently undamaged hard drive.) From where I'm sitting,
though, I see the following systems either connected via switchbox to
the TV, or stowed away in a mesh drawer:
Nintendo
NES (classic frontloader)
SNES
N64
?GameCube
?GameBoy
Classic
Pocket
Color
Advance
purple with TV connector mod
pink
Advance SP (x 2 platinum)
Sega
Genesis
Dreamcast
XBox
PS2
Stowed away in closets and, possibly, at my Mom's house, I've also
got an Atari and ?ColecoVision. Also, I have a small start on a
computer collection as well, including a C64, Atari 800, Amiga 1200,
and of course a smattering of random PCs.
Eventually, I want a house, and a room in this house will be dedicated
to the display and use of these machines. Also, eventually, I want
to work on a proper collection of these things and their games and
software. (For instance, I'm in desperate need of a second generation
top-loading NES.)
The funny thing is that people still ask me occasionally if I really
need or use all this stuff. How could the answer be anything but yes? :)
[ ... 472 words ... ]
Oh, and I've been meaning to post a little note of thanks to everyone
who're still reading this blog. I haven't done or said much of note
around these parts in some time, with the only saving grace being my
automated BookmarkBlogger posting every night. More than I expected,
those posts have actually caught the interest of a few people.
But I never wanted this
place to turn into just another link-blog. And I also have been feeling
a bit guilty that my Quick Links give no indication of source where
I found these tidbits. They are, more often than not, gleaned from
the 320 or so sites whose RSS feeds I slurp down 12 or so times a day.
I really need to get some sort of blog roll going again, but somehow I
doubt that everyone wants to download my RSS feed list when they visit
here.
Anyway, that's all. Thanks for reading and sticking around as I get
things sorted and stitched back together in the offline world. I hope
to come back with some nifty things soon, since I'm itching to hack.
[ ... 187 words ... ]
RSSify is a rather horrible hack that shouldn't be needed any more. Please ask the owner of the site you're reading (...) to change to a system that generates RSS natively such as Blogger Pro or Movable Type. Alternatively consider hosting RSSify yourself rather than using my bandwidth.
Source:22-May-03 Moving away from RSSify
Noticed this show up suddenly today as the new item to a surprising number of
feeds to which I subscribe. I knew Julian Bond's public RSSifying service
had gotten used far and wide, but wow. The bandwidth bills must've been getting
quite annoying, having become a sort of adhoc bit of the
Rube Goldberg blog
infrastructure. So, as for my own consumption, thanks for the use of your tool Julian, and
all apologies for being a leech!
Well, I'm still working a bit on my own Java-based transmogrifier robot
to scrape disparate sources of info into RSS feeds for me. I suppose I
should get to work trading my RSSify-based subscriptions for my own
DIY-scraped versions. If I get some time soon, I'll wrap this thing
up and release it. But first, I hope to get it fully automatedly working with the
iTunes Music Store, as I've been tinkering.
[ ... 306 words ... ]
A copy of Programming Web Services with Perl
surprised me yesterday by arriving on my doorstep. I'd forgotten that back in March,
Paul Kulchenko
(one author
of the book's two) had offered me a free copy of it response to
a quick thought of mine about
a more Unix-like model for filtering web services (something I want to get back to).
Anyway, I've yet to get very much into the book, but a cursory skim tells me
that this looks like a great book. Thank you very much for sending me a copy, Paul!
[ ... 95 words ... ]
I've just started experimenting with integrating
Sam Ruby's autoping.py with my blogging
rig here, and discovered that I really had rushed things a bit and didn't
understand what the thing was doing. I think my caffeine intake for today is
way below baseline, so if yours happens to be one of the sites I mistakenly
vandalized or spammed with broken or erroneous trackbacks, I apologize profusely!
Update: Speaking of Trackback, I just duct taped an initial implementation on
the receiving end with a revision to my BlosxomDbcomments plugin. It needs some testing,
so if you see this, and don't mind, pummel this entry with trackbacks! Next, I'm
considering integrating referrers, thus bringing this new blogging rig up to
where I was a little over a year ago.
[ ... 416 words ... ]
I've given the aggregator a concept of whuffie. I can give any item that has been aggregated a thumbs up or thumbs down, increasing or decreasing the item and site's wuffie. I sort the sites out as I display them by their whuffie. It is a simplistic way of keeping the sites I'm interested in at the top of the list. I'd like to wire in a Bayesian classifier too, and see if that helps me get the items I like to the top.
Source:Serval, an aggregator with Whuffie via matt.griffith
Yay, an aggregator with whuffie-tech! This is very similar to what I was doing with
AmphetaOutlines for AmphetaDesk - when I click on an item from a channel, I increment
a counter for that channel. And, when I sort channels for display, I use that count as
a factor in the sort.
And, of course, I want to use Bayesian filtering to see what I do want.
What would really be whuffie-riffic about aggregators that support this kind of
thumbs-up/down tracking, would be to have some P2P sharing of these decisions
to come up with something actually more like whuffie. That is, I would like
to see how much right-handed whuffie some item has gotten, and possibly
bubblesort up or visually tag items I've yet to read based on that whuffie.
Right-handed whuffie being, of course, the accumulation of whuffie an item
has be given by authors to whom I've given lots of whuffie.
[ ... 458 words ... ]
Okay, no.
This new Matrix-inspired phone is ugly as hell and not cool at all. Do they actually use this thing in the movie? I hope this isn't a sign for what the movie will be like -- clumsy, bulky, cartoonish and not at all subtle like the original. See, the first movie had a phone. I forget the model number, but I think it was a Nokia. its sliding keypad cover was modified especially for the movie with a switchblade-springload action for extra cool factor. And, unlike a lot of phones at the time, it was slick and sleek and tiny.
So what the hell is this thing? It looks like a walkee-talkee for grade school kids, not the "ultimate conversation piece".
[ ... 942 words ... ]
...Personally, I'm getting SICK of running into my OWN BLOG while doing research into any of the topics that I've ranted about here. I spend a couple posts talking about a technology with questions or thoughts, then later I go to implement this tech and need specifics and yet 2 or 3 of the top ranks are filled with my annoying blather. Urgh!...
Source:Russell Beattie Notebook: Those who Live by Google...
Amen. More and more, I'm running into myself on Google. I'll be looking for expert information
on something I'm trying to tinker with, and discover that one of more of the top
search results are me writing about looking for expert information on the thing I'm
trying to tinker with. Just occasionally do I find myself having actually provided
the information that I'm currently seeking.
I mean, it's not a gigantic shocker-- my interests are relatively stable over
time, and I circle back to things after long periods of time, so this is to
be expected I suppose. But I'm starting to feel like I'm in a bad time travel
movie.
[ ... 317 words ... ]
I've never gotten much spam. I closely guard the email addresses I care about. Spamex makes it simple but I did it before without Spamex. My problem is information overload. I'm much more interested in seeing the same thing for RSS. Instead of blocking stuff I don't want I want it to highlight the stuff I might want.
I've been out of the loop lately because I can't keep up with all of the feeds I would like to monitor. I need help.
Source:matt.griffith: Where is RSSBayes?
Ditto. Using a Bayesian approach, or some other form of machine learning, as applied
to my aggregator and my viewing patterns is something I've been wanting for awhile now.
I've done some very, very primitive self-monitoring with AmphetaOutlines, but I'd
like to get back to some machine learning research and build an enhanced
aggregator that learns what makes me click.
[ ... 216 words ... ]
Yeah, I know I gave the iTMS a 'bah'
last week in response to discovering DRM under the hood. But I've softened in
my opinion since then. And bought a few more songs that I haven't heard in years.
And burned an Audio CD. And wasn't too inconvenienced.
My girlfriend and I almost
bought iPods last night, and though we resisted the temptation this time, I expect that
we'll end up with them before long. And when that happens, I imagine we'll try sharing
tracks, and that doesn't seem to be too inconvenient either. And then, there's the
fact that the iTMS seems to have a pretty nifty set of underpinnings that look like
fun to play with.
So now, like anything I'm interested in on the interweb, I want to swallow it up with my aggregator.
Thus, I attempt a new project: ItunesMusicStoreToRss
Progress so far, but I've hit a stumbling block. Anyone want to help?
Update: A little bit of cut & paste from the wiki page:
If you spy on iTunes while browsing to a "Just Added" section of a genre, you'll find that a URL like the following is accessed:
(it's a long URL)
The response to that URL is some very interesting XML that looks like a GUI language. Buried in the GUI recipe, however, is what I want flowing into my aggregator. So, I dust off my XSL skills and have a go at mangling this content into RSS. I seem to have been successful. A test run appears to validate, and is accepted in my aggregator.
The problem, though, lies in the aforementioned URL. Everything seems pretty clear and straightforward, and I can change genre's by supplying discovered ID's to the id parameter. However, the "fcid=145690" parameter is an unknown to me. It seems to change, though I haven't yet investigated its derivation or how often it changes. I was working on things yesterday, and the value was one thing, this morning it was another. If the number is not valid, unexpected results happen, sometimes resulting in HTML output describing an application exception. So, until the fcid mystery is solved, I've yet to automate this transformation.
Any ideas out there on the lazyweb? Visit the wiki page (ItunesMusicStoreToRss) and feel free to poke fun at my XSL skills.
[ ... 716 words ... ]
Posting this just in case anyone needs it. I've been getting the
following strange message lately in logs and consoles under OS X:
## Component Manager: attempting to find symbols in a component alias of type (regR/carP/x!bt)
As it turns out, I had just installed Toast. A quick Google search
leads me to blame Toast and remove a QuickTime component supporting Video CD.
That's pretty obscure. Hmph. So much for never again worrying about strange drivers and
cryptic error messages under OS X. :)
[ ... 122 words ... ]
How unobservant am I? It took
an article from The Register
to make me realize that this new Apple music store does indeed
use DRM to lock up purchased music. The files aren't mine. (Though, whoopie, I'm
allowed to use them on up to 3 computers.)
Crap. No thanks. I guess
that 10% of the catalog doesn't look quite so attractive at a buck-a-song now.
I mean, I've already destroyed one computer
with a tumbler of water, why would
I want to lose all my music with the next one I douse? And what happens in 10
years or so, when I want to listen to all those hypothetical Talking Heads
tunes I bought? Of course, I'm still listening to CDs and tapes I acquired back
in junior high, and I don't need to query anyone's permission to do so.
I hereby bestow this award to the Apple Music Store:
[ ... 243 words ... ]
Umm... what is iSync doing? I didn't know that it had anything to do
with my bookmarks. Lately I've been using bookmarks more since I started
using BookmarkBlogger. Nearly every time I try dragging a bookmark into a
toolbar folder, though, I'm rebuffed by this dialog. What gives? The bookmarks
don't show up on my PDA, or my calendar. With what are they being synched?
I see that Scot Hacker has
discovered the same thing happening to him. Lots of comments, but still no
answer as to what's up with this. Hmm.
[ ... 230 words ... ]
Okay, so in between all the other hecticity currently ongoing in my life,
I managed to check out Apple's new music service. Although I'm not interested
in approximately 90% of the music offered so far, that still leaves me with
2000 songs whose "buy" buttons call my name. The process is simple, the files
are mine and not locked up with DRM, and although I hope and expect the price
structure to change (ie. maybe price based on popularity?), a dollar a song
isn't horrendous considering that I get what I want on demand and without
hopping in the car and going anywhere. So far, so good.
So... This got me to thinking in the last 10 minutes: What about an indie
clone of the Apple Music Service? One using RDF or some other XML format to
offer up the catalogues of record labels? Include all artists, albums, songs,
and any various and sundry bits of trivia about all the above. Establish a
modular mechanism for specifying payment process (ie. paypal, credit card,
free, upload a song), and make the whole interface as slick and easy as
iTunes'.
The real trick I see in this, though, is to make the file format for music
vendors fairly easy yet flexible. It should be as easy or easier than an
RSS feed for a blog. Let a hundred of these mushrooms bloom, aggregate,
search, and buy. Make it distributed and not dependant on any particular
music company or technology company.
Not a terribly original idea, but that's what I just thought of. Sounds
like a good semantic web app that could have some umph going for it in
the immediate future.
[ ... 366 words ... ]
I take rsync for granted. It's just the best way to keep stuff out there
up to date with stuff over here, and vice versa. And lately, I've been
using it to supplant my usage of scp. And it works. Brilliantly. And until
recently, I hadn't stopped to realize: Hey, you know, this thing somehow works
out differences between files out there and over here long before
what's here gets there. I know, duh, but I just hadn't considered it.
Well,
Paul Holbrook reminded me
of this tonight, with links to Andrew Tridgell's
paper on the algorithm, among other things. Damn, things like this remind me
that I'm supposed to be getting my butt back into school...
[ ... 179 words ... ]
Was thinking about learning new tech, and well, I haven't gotten much
farther into .NET
as I'd wanted to,
given moving and a sudden appearance of work. Instead, I've had
a project hurled at me that combines Flash MX and XML, something I've
just barely touched before.
Wow, is this stuff fun. And I write that without a trace of sarcasm--
this app I've inherited for maintenance and extension, though it's a
bit grungy and shows some signs of late-night expediency, does some
neat things with actions and buttons dynamically wired up in response
to XML config files loaded via URL, which are in turn generated from a
database managed by a simple end-user admin interface. Not sure how
much more I should write about it, but I'm dying to post a link. Of
course, this isn't revolutionary stuff in general. It's just a revelation
to me.
The last time I had an opportunity to really, really dig around in
Flash was just about when Flash 5 came out. I was immersed daily in
Flash in the years between the initial acquisition by Macromedia, up
through version 4, and just started drifting away, sadly, when things
started getting really interesting with v5. That was when my daily
job swung entirely into the backend, and client-side concerns were
no longer my task.
But now I'm back in this old neighborhood, and I can see why some
people would love nothing better but to build entire websites in
Flash. Yeah, that's evil, but it's sexy. Despite some clunkiness,
there are some very nice possibilities I see now. I love Java, and
loved cobbling together funky applets 5 years or so ago, but Flash
makes me want to toy with rich client-side apps again.
And then, there's this
Sony Clie PEG-TG50
handheld I've recently started pining for, and it appears to run a
Flash 5 player. It's probably underwhelming, but who knows?
Anyway, back to work, but just had to spill some enthusiasm for
Flash.
[ ... 543 words ... ]
Mark Pilgrim asks: What's your Winer number?
I duck & cover under our new futon. The one that I broke already, but it's better than nothing.
[ ... 27 words ... ]
Wow. Missed this from Mark over
the weekend, and then further missed Sam's link to it
and the subsequent whirling mass of shitstorm that rolled past in its wake. Well, at least everyone
just ends up being an asshole in the end, and no nazis or ethnicities
or monsters were invoked in the process. And no one co-opted any acronyms, though I think
someone got ketchup on their tie. Hope it wasn't silk. And does anyone know if all us assholes
are actually alive or dead in Schroedinger's Trunk?
[ ... 127 words ... ]
Finally got around to reading Cory Doctorow's Down & Out in the Magic Kingdom,
and though I loved it, I wish it were longer. Or, at least,
I'd love to see more stories from the same setting or playing with the
same themes of the Bitchun Society. I have seen some of these things
in stories before, though. So, hey, I haven't posted anything here in
a few days - have some babble and book links (feel free to comment and
leave some more links):
Of course I love the notion of ubiquitous computing and personal
HUD's. I've babbled about that at length for sure. If you want more
of that, go check out Vernor Vinge's
Fast Times at Fairmont High.
Mediated reality with P2P computing woven into clothing and projected
across contact lens displays. A little less obtrusive than
seisure-inducing in-brain electronics, but just as post-human.
And then there's backup-and-restore and the cure for death. Although
in David Brin's
Kiln People,
things start with disposable
doppelgangers, survival of personality after bodily death is promised
in the ending. What could change human nature more than transcending
mortality?
As for deadheading, check out Vinge's
Across Realtime
series. In
particular, read up on bobbling in Marooned in Realtime. There's also
Orson Scott Card's The Worthing Saga.
A one-way trip into the far future
through geological periods of time seems particularly external to
known human experience, especially when combined with immortality.
One thing I've yet to see much in stories or speculations is how
society could function in a post-mortality and post-scarcity
conditions. I've never been satisfied with the way Star Trek dodges
the day-to-day realities of a post-capitalistic Federation of plenty.
Walter Jon Williams' Aristoi
explores an interesting track with a
meritocratic society whose top members have godlike powers matched to
godlike creativity and self-possession (not to mention possession by
multiple selves).
But so far, Whuffie and its currency in reputation is the best game
I've seen yet. Since, even if the problems of mortality and material
scarcity are solved, human attention and cooperation will never be
gratis. So, how else do you herd the cats when you can neither
threaten nor reward them via any physical means? Seems like the
blogosphere, gift culture, and open source noosphere brought to
reality.
Kinda makes me want to get back to fiction writing meself and finally
get out the dozen or so stories I've had bouncing around in my head
these past years. Doesn't necessarily mean I'd churn out anything
good, but who knows? Maybe after some work and some stumbling I could
produce something passable. All those creative writing classes in
college and short stories in spiral-bound notebooks from high school
have to count for something. I'd even love to squat in the Bitchun
Society for a few stories, but that might be a bit presumptuous, even though
Mr. Doctorow himself has let on
that he's not likely to write more
tales from the same Bitchun universe.
Better to get some practice in before jamming in someone else's club.
[ ... 703 words ... ]
In my intermittent online presence, I've been happily watching Dave Winer's
ramp-up with OPML toward OSCON with things like
"How to implement an OPML directory browser".
I love outliners, and though it's been a little while since I played with Radio, I loved Instant Outlining
and the transclusion of outside outlines into the
one at hand via URL. And when Dave first introduced the idea of an OPML-based distributed web directory,
I figured it was the start of another nifty twist in the web fabric. (You know, the kind that makes wrinkles?
The kind of wrinkles that make brains smarter?)
Anyway, even given all this, OPML has always bugged me, and I'm not alone. In fact, today I found a
link to OML, the Outline Markup Language project on ?SourceForge,
which seems to seek to address many of the same things that have bugged me. That is, things like
UserLand application-specific tags, and extension via arbitrary attributes. Though I'm no master
of deep XML magic, these things struck me as grungy.
But you know, we're designing for recombinant growth with the lazyweb here
(or at least, Dave Winer was and is), and OPML looks like one of those dirty things that got
thrown together quickly in order to enable a laundry list of further projects. It works, isn't
all that hard to grasp, and has gotten adopted quickly. There's momentum there. As
Dave says, there is no wait for
tools.
So, now there's also OML starting. Hopefully this won't become another rehash of the RSS fight.Because, I sense many similar issues between the two. Maybe it would have been better still if OML had been named something
completely avoiding the letters O, P, M, or L. I already see mailing list charters being called out in order to quiet unwanted
discussion of fundamentals, but, hopefully we can avoid anyone claiming that they have the One True Format, all fighting for the
same name and slapping each other around with version numbers. Gah.
Anyway. I like OML but see some grunge in it as well. At the moment, I'm using an OPML-supporting tool. I can't imagine that
conversion would be more than an XSLT file away. Well, maybe more than that. Beyond that, let's agree to disagree and viva le
fork. Let the best, most demonstratably capable format win. Meanwhile, I'm still considering that Tinderbox license to see if I
might like multi-dimensional outlining...
[ ... 741 words ... ]
So yeah, I wanted tabs in Safari. Or something like tabs.
But since discovering that the "Window" menu in OS X is not painful to
use, and that CMD-Backquote rotates between open windows, I've not missed
tabs an incredible amount. I think my tab usage was a response to my experience
with Windows and Linux window managers, though even those have changed since
I started using tabs in my browser.
However, I still love using pwm as
my window manager under X11, with its tab collections and windowshading. Go
figure.
[ ... 91 words ... ]
Been out of touch with my usual online haunts as of late, and have barely had time to think straight,
let alone write.
My girlfriend and I have moved just from one end of town to the other, and we have an overlapping
month of leases between the new place and old. In theory, this is plenty of time to accomplish moving
and cleaning and decorating. But, some things are hard to move gradually, especially when both she
and I have compact cars and trucks rent by the hour. And then there's the fact that our new residence
is found on the third floor, providing much exercise to the both of us. So, it's been a hectic couple
of weeks so far, though well worth it for us to start settling down in new and improved digs.
And then, right in the middle of things, I was offered an opportunity for a few months' work as a
contractor for a startup located almost (but not quite) within walking distance of the new apartment.
So, I decided to snatch that up, and since then things have been doubly busy. Whew. This'll give me
some breathing room to figure out what's next, hopefully.
So anyway, here's hoping things settle down a bit and stop feeling like I've jumped the tracks. After
getting life in general into some semblance of happy chaos, I hope to get a chance to catch up on
happenings and maybe even take a stab at some of my projects around here again.
[ ... 340 words ... ]
0xDECAFBAD (I love that name) has a new design, powered by Blosxom. I like it. You're going in my bulging blogroll, Les.
Source:Time is Tight: 0xDECAFBAD v2.0
My referrer monitoring scripts have been out of action since shortly
after I revised my site design, so I've been missing links. Today, I
fired things up again for the first time since the beginning of the
months and caught the above. Wow, and I'm an Elite Geek, at that!
Welcome to 0xDECAFBAD! You can do anything at 0xDECAFBAD! The
unattainable is unknown at 0xDECAFBAD! Yes, this is 0xDECAFBAD, and
welcome to you who have come to 0xDECAFBAD! Welcome!
(Please tell me someone out there knows what I'm going on about.)
[ ... 232 words ... ]
Sheesh. Okay, come back to us when you get a real phone.
Source:Mobitopia: Slashdot - Life in 3G
So says Mr. Beattie. And I say, "Hey, that's my phone!" And then I
say, "Oh yeah, that's right, that's my phone." I like my phone, it's a
nice phone. I had a Treo Communicator, but it went kaput. I thought the
A500 would be a decent 3G device. It's not. But it's a nice phone...
[ ... 75 words ... ]
Apologies in advance if this post-cum-essay runs a bit long...
We could conclude that modern human intelligence is an unfinished product, and something that nature hasn't quite got around to polishing yet. The problem-solving intelligence part can be tuned and revved up to high levels, but it becomes unstable like early supersonic jet prototypes that shook themselves to pieces just after reaching the sound barrier. Nature has outstripped itself, producing a freak organism with a feature that's obscenely over-developed but under-refined. We've seen examples of evolution getting ahead of itself before, like the rapid conversion to an erect, bipedal skeletal frame without properly modifying the spine to withstand the back-aching load of pregnancy. To get a better grip of human failings, and human stupidity, you have to realize that modern Homo sapiens sapiens just isn't done yet.
Source:Disenchanted: * Early prototype, expect instability
When our own instincts are inadequate, or become a hazard, and the surrogate activities to control them aren't sufficient anymore, then there certainly will be a push to change human nature to fit his new, self-crafted niche. And the answer to my original question?that man will invent something that knocks him out of his niche with fatal consequences?is yes. Homo sapien will die, and homo modified will inherit the earth.
Source:Disenchanted: Invent this and die
There's only an essay or two per month published over at Disenchanted,
but they're gems, each and every one. And what I read almost never
fails to resonate with something I've been thinking or musing about,
from my perspective as a geek wondering about life, the universe, and
everything and as a fan of Kurzweil, Vinge, and all of post-humanity.
But my anticipation of the Singularity is constantly swayed by things
such as the theses of the above quoted essays.
See, as an irredeemable believer in the ways of better living through
technology, I look forward to our increasing ability to further
self-improve and bootstrap to higher levels of living, longevity,
ability, understanding, and exploration. But, there's a neopagan
mystic and naturalist in me who keeps looking for the catch. There
must be natural limits we don't yet understand.
No matter the precocious cleverness of our species, there's got to be
plenty of good reasons it takes millions of years to achieve progress
in forms and patterns of life. There are lots of little subtle
details to be easily missed. We're smart, but not yet endowed with
the patience and wisdom that eternity grants. I both breathlessly
await and fear the arrival of our ability to fundamentally change
human nature directly through genetic manipulation and device
implantation.
As the first essay quoted above asserts, I believe the human species
is unfinished. But as with the second essay, I think we've outpaced
evolution in terms of changing the conditions under which the process
itself occurs.
Just look around you. You're likely indoors, in a building composed
of simple straight lines which register easily on your visual pattern
recognizers, with corridors and doorways and rooms proportioned to
your bodily dimensions. The air is conditioned to your respiratory
and temperature tolerances. Things are padded and accessible. Food
and drink are likely plentiful. The only predators you're likely to
meet up with during your day are of your own species. Nothing really
challenges your basic nature.
Yet, this is just what the universe has been doing to forms of life
throughout the history of evolution. Only now, we've jumped the
tracks, reversed the flow of control, and have reshaped our corner of
the universe to fit our status quo. So, where does that leave the
natural process of evolution with regard to us? Stopped or slowed to
a crawl, that's where. Maybe falling backward, since we have
prosthetics, glasses, and other forms of propping up imperfections
that would have otherwise been faced with disincentives by natural
selection.
So, where are we without a natural evolution? We're left as an
unfinished species, with a peculiar mix of awesome abilities matched
with amazing disabilities. Very clever people, but with a lot of
blind spots. There are certain ways in which it is very difficult and
sometimes nearly impossible for us to think. We have biases toward
grouping things by similarity, dividing them by difference - which
allows for a very elegant economy of memory and thought, but allows
for peculiarly devastating things like racism and xenophobia.
Critical thinking is counterintuitive, yet is one of our most powerful
tools.
And there are definite flaws in our perceptions of reality, as any
book of optical illusions will tell you. One thing that struck me
like a thunderbolt came from a human biology class: Ever try following
a common housefly with your eyes? Isn't it frustrating how it just
seems to vanish from your sight? I can't find a reference to back
me up, so this is just from memory: I was taught that flies have
developed a particularly zig-zaggy and erratic flight pattern to evade
just our kind of mammalian vision system. But, studies of fly-eating
frogs have shown that their vision systems appear particularly tweaked
to react to a fly's midair dance. Imagine what else slips past us, or
comes to our attention garbled because our very apparatus contains
biases of which we're yet to even conceive?
Here we are, then, flawed and incomplete yet with a growing ability to
self-modify. As an amateur computer scientist, I shudder a bit at any
code that's self-modifying. It can be done, and it can be powerfully
enabling, but it's just so damn easy to blow a foot off with the
technique. So too with ourselves, then. There's a possiblity that we
can push ourselves into a richer level of thought and perception and
ability without destroying ourselves completely. But, we're going to
miss things, important things.
If we're lucky, we'll roll with it and survive. But, as the second
Disenchanted essay explores, we'll most certainly render the species
as we know it extinct, and push ourselves our of a natural niche and
into a wholly artificial niche in need of perpetual maintenance and
renewal. Maybe this artifical niche will be easily sustained and
portable enough to take with us if we want to leave the planet. On
the other hand, maybe this artificial niche will prove our undoing as
it outstrips our ability to keep it up.
So, given all this, I think the inevitable predicted verticality of
the Singularity's curve has an incredibly strong counter-force
stemming from human nature itself. What does this mean? Not sure.
What to do? Not sure. But it tells me that the Kurzweilan and
Vingian predictions of which I'm so fond face some severe reality
checks.
More thinking to do. Thanks to Disenchanted for making me think this
far today. :)
[ ... 1507 words ... ]
It comes out the box with an English manual, a PC link cable, the GP32
uses PC smartMedia as its Hard disk and has 8meg of internal ram + its
(upgradeable) OS, a USB port, a large hires screen (which is SO much
better than the GBA one), two stereo speakers (one on each side), a
joypad and 6 buttons (4 on front and 2 shoulder buttons), a 3v in
socket, a headphone socket, volume control, battery compartment (2xAA
for 10-14 hours) & an EXT out port which allows you to do many things
including using the gp32 on your TV or for wireless multiplayer.
...The console is open source and fully supports people making their
own programs for it, there is a GCC based devkit complete with
graphics and sound libs.
Source:GBAx.com review of the GP32
Just read a review of the GP32,
a handheld game console I'd never heard of before.
Pictures of it look amazing,
and the specs aren't too shabby either. Powerful enough to run
emulators of a sickening array of game platforms, uses ?SmartMedia
cards, support wireless multiplayer via cell phone. And, oh yeah, it
looks like you can actually see the screen.
The biggest flaw I see in this thing is that it would be so easy to
pirate games for it. Supposedly there were some attempts to provide
for a mechanism to "lock" games to a particular handheld, but that
appears to already have been circumvented. So, while the thing looks
like a dream machine to me, it probably looks like a nightmare to game
producers.
Still, though, I want one. And I bet Russell Beattie wouldn't mind
one either, if he hasn't heard about it yet, given his
professed love for his GameBoy Advance.
And, speaking of Russell, I wonder just how well that wireless
multiplayer support works...
[ ... 307 words ... ]
Playing with a few other little widgets here and there, I thought I'd
fire off a new revision to the BookmarkBlogger for Safari I've been using
off and on. This one's a big more OS-X-ish, and uses a properties file
for configuration instead of completely confusing command line options.
ShareAndEnjoy!
Also working on a lil DOM4J-, JTidy-, and ?BeanShell-based scraper
for producing RSS from arbitrary web sites. Yeah, it's been done before,
but not by me and not quite like this. And eventually I think I want to
try turning both this and the BookmarkBlogger into dual-purpose standalone
and AgentFrank plugin packages.
[ ... 132 words ... ]
So, while my time is mine, I've decided that I want to expand my
practical horizons. And, one of the first things I can think of is to
go lateral and approach something I've looked upon with mild disdain:
Microsoft technologies. In particular: .NET
I already understand Unix well enough to do damn near anything -- this
is not to say that there aren't still years worth of things left for
me to learn in that sphere, but I'm not nearly as adept with
Microsoft's offerings. And, besides the practical concerns with being
flexible enough to take on what work the world offers me, I also have
a hunch that this .NET thing will make me think as differently about
Microsoft as OS X made me change my mind about Apple.
Maybe. But it's still a good attitude with which a punk unixhead can
approach the subject, I think. I'm going to assume that brighter
people than myself have applied themselves to the creation of .NET and
prepare to be surprised. This attitude has always served me well in
the past when trying something new. (Take Python, for instance.)
Okay. Got a good attitude. Have installations of WinXP and Win2003
preview (which I'm kinda, grudgingly digging so far) running in
Virtual PC on my ?PowerBook. Could even draft a PC at home into
service running an appropriate OS if need be. Have downloaded the
.NET Framework and installed it on XP and Win2k3.
Now what? Were this Java, I'd pop open an emacs window and start
playing. I'd grab some free app servers and check some things out.
Being on a fixed budget, I don't think I can spring for any packages
like Visual Studio .NET. And being a unixhead, I'm used to being able
to find dev tools for free.
Anyway, this absolute newbie is continuing to poke around.
[ ... 1204 words ... ]
So, as I'm working to recover all the old tools I knew and loved on my
iBook, I see this on the
Searchling home page:
Work on Searchling has ceased to focus on its successor
-- iSeek.
...and there are no downloads for searchling available, neither binary
nor source. Harumph!
And the screenshots of iSeek don't please me much -- I see a search
field wodged into the menu bar in place of the nice, slick ghostly
search field that would materialize with a quick Cmd-Space or a click
of the magnifying glass. Gagh. My menu bar's already crowded enough
with menu entries on this 12" screen as it is.
But, if I'm completely wrong, and there ends up being a feature to
make iSeek work and feel just like my old friend the Searchling...
well, then I say congratulations to its author for cobbling together a
saleable lil widget, and I'll be waiting impatiently for its release.
:)
[ ... 237 words ... ]
Here's a little something I whipped up last week: BlosxomPaginate.
I've been using Blosxom and Blagg for my news aggregator lately, just
for a change, and one thing I was really missing was some way to see
entries that fell off the end of the front page.
So, I made this. It
lets me flip back and forth between pages of Blosxom entries, and I
even went so wild as to include full flavour-based template support of
the display of the navigation elements.
ShareAndEnjoy
[ ... 342 words ... ]
I hadn't written much last week, between the job search and getting
myself hooked up with a new laptop. I'd meant to revise my initial
post announcing my being laid of - but instead, I simply lost it
when the iBook got doused.
So, to those of you who haven't heard my news: I was laid off a little
over a week and a weekend ago. No hard feelings or fireworks, just
typical bad economy reasons. Nevertheless, it took me by surprise.
So now I'm shopping my resume around.
If you're interested, my resume is available here:
http://www.decafbad.com/2003/03/l-m-orchard-resume.doc
http://www.decafbad.com/2003/03/l-m-orchard-resume.pdf
Last week was strange. Having been let go on a Friday, I had a
weekend to pretend things were all as usual. But, when Monday hit,
things were different. I still got up at the usual time, did the
usual morning things, and got out of the apartment as if I were going
to work. But instead of heading for the highway, I headed for a
coffee shop
near campus with wireless internet. Trying to keep the old
patterns as normal as possible, only now my job is finding a job and
getting myself in shape for what's out there.
It wouldn't be news to anyone to hear that the job market, at least
what I've seen of it so far, is nothing like the verdant plains and
valleys of even 3 years ago - which is about the last time I took a
serious look. After a first survey of a few job boards online, I
fired off a handful of resumes and apps, and took notes on what's
being asked for so as to prepare some semblance of a learning plan
while I'm off.
So by the end of last week, I'd accomplished these various and sundry
things:
5 cups of coffee consumed per day
1 resume updated and revised
6 resumes emailed and 4 online applications filled
5 profiles completed at online recruiting sites
1 application for unemployment filed
1 12" G4 ?PowerBook acquired and configured
3 Microsoft operating systems installed and configured under Virtual PC
1 .NET Framework installed and exploration begun
1 novel finished, Close to the Machine by Ellen Ullman
6 hours of Metroid Prime played
There's been more, but it's the amount of Metroid Prime play I'm most
proud of - had I not gotten out of the apartment in the morning, the
hours invested in that would have been immensely greater. Maybe after
I've fired off a few more resumes, I'll feel better about actually
taking a rest since my brane's been going full speed for months now at
work.
Thought a bit about striking out on my own with freelance work, but
the Ellen Ullman book has given me a bit of a strange mood. She makes
working for oneself sound both promising and desolate at once - though
the promising bits would seem to be the things that disappeared with
the 90's. So that leaves it sounding pretty unpalatable. Who knows,
though - I always wanted to work from (but not at) a coffee shop.
Well, back to searching and my first baby steps with .NET - wish me
luck. And if you happen to be in town, stop by and say haloo.
[ ... 812 words ... ]
Just for future reference: No matter what your cats think, iBooks
never get thirsty for a nice big tumbler of water. Nor do they
ever have a need to soak in the contents of said tumbler overnight.
Although now, I have an expensive, dead laptop that makes white
noise sounds not unlike the ocean when it's plugged in. And it
smells like the magic blue smoke when it's let out of the chip.
I just hope that the hard drive is recoverable. Updates will be
sporadic as I try to reconstruct my environment and remember passwords
and try to find serial numbers.
Oh yeah, and still on the trail of the job hunt. Going to be
tweaking some things around here as I have time, to make things
a bit more presentable for company.
[ ... 552 words ... ]
Simon Willison writes
that he'd read my blog more if I
pinged weblogs.com
more often. I used to, via MovableType, but my new blog doesn't. Enter
ping_weblogs_com,
a Blosxom plugin to ping weblogs.com. I've
just installed it.
Let's see if he notices. :)
[ ... 182 words ... ]
So on this day last year,
I was excitely thinking about pipelining webservices together like commands in a
UNIX command line shell. Lately, I've been doing quite a bit of work at the
command line level, more so than I ever have before. And for all the clunkiness
and inelegances to be found there, I think the zen has stuck me.
Sure, it's an ass-ugly string of characters that connects commands
like find, sort, awk, sed, grep, and ssh together. But, in constructing such
monstrosities, I find myself generating new disposable tools at a rate
of at least one every minute or so. And, though a few have found themselves graduating
into fuller, cleaner, more general tools, I would have been stuck for
hours were it not for a quick multi-file grep across a vast plain of comma-separated
value files digested by a tag team of sed and awk. Then, like magic, I toss in
an incredibly slow yet, at the time, convenient call to mysql on another server
behind a firewall via ssh with a SQL call constructed from the regurgitations
of said sed and awk brothers.
So, I'm thinking again: How hot would this be if it were web services replacing
each of my commands? How hot would it be if there was a STDIN, STDOUT, and STDERR
for a whole class of web services? Imagine an enhanced bash or zsh piping these
beasts together. For awhile, I thought my XmlRpcFilteringPipe API was the way to
go, but lately I've been thinking more in the direction of REST. I have to admit
that the XML-RPC API is a bit clunky to use, and besides, no one's really paid
it much notice besides using it in the peculiar fashion I do to make my WeblogWithWiki.
How about this for a simpler API: Post data to a URL, receive data in response.
There's your STDIN and STDOUT. What about STDERR? Well, I suppose it's an
either-or affair, but standard HTTP header error codes can fill in there. What
about command line arguments? Use query parameters on the URL to which you're
posting. This all seems very web-natural.
Now I just have to write a shell that treats URLs as executable commands.
[ ... 725 words ... ]
Okay, I don't think I made this up: I was reading Wired Magazine a
few months ago, and I saw a phone featured in the Fetish section
that was designed like a KooshTM ball or a sea-urchin.
The idea is that it would be used in a teleconference, thrown back
and forth across the room from speaker to speaker.
We need this at my work.
Has anyone else seen this thing, remember what it was called, or
where they're selling it? I can't seem to find it again in any of
the Wired issues I can find in my apartment and office.
[ ... 203 words ... ]
So, sometime around last November, my iBook started having battery
problems. It went from 3 hours of life, down to an hour, and finally
down to about 15 minutes' worth of life. Being lazy and busy, and
having my iBook mostly at desks near outlets, I put off taking it into
the shop -- I'd just taken it there to replace the hard drive, and I
didn't feel like parting with it again. Stupid, I know. Lazy, I know.
Well, since then, the problem hasn't gotten better, and I was just about
to get off my ass to do something about it when I see this:
MacNN: iBook users experience 10.2.4 battery bug
So after browsing around forums a bit, I learned how to reset my Power Management Unit,
did so, and discovered that the battery began to charge again. I left
the iBook off and watched the 4 LEDs on the battery gradually light up
over a bit of time while working on my desktop. Looks like the problem's
solved for now.
Ugh. I'm glad, at least, that it wasn't a physically dead battery.
[ ... 206 words ... ]
Oh yeah, and a giggle for me today:
Go to Google.
Enter "I'm Feeling Lucky".
Click "I'm Feeling Lucky".
What do you see? If you're seeing what I'm seeing, it's this very site!Now, I'm not sure how long this will last, or whether it means someone at
Google H.Q. loves me, but it's pretty dern nifty.
Thanks to Nathan Steiner of web-graphics.com for the tip!
[ ... 439 words ... ]
Thanks for bearing with me out there in the blogopshere. This transition, though
smoother going than I'd thought, is still exposing some rough spots and things
I hadn't thought to check. Seems my RSS feed hasn't come through quite as intact
as I'd hoped -- and an unexpected bug in the rss10 plugin for ?Blosxom seems
to have caused some news aggregators to implode. Apologies all around!
But, I'm watching, and tweaking, and will be shortly reporting all that I've done
around here to change things. I'll be cleaning up and releasing my small pile of
blosxom plugins and patches, once I have a bit more time to do so. In the meantime,
I've got an error log rolling in one window, and I'm keeping an eye on comments and
email. Hopefully all this will be nice and smooth before the end of the week.
[ ... 151 words ... ]
Not much to see here yet, but I've burnt down my old weblog and
replaced it with this. Planning to start out simple and gradually
re-introduce features from the previous incarnation very slowly and
carefully. I've enjoyed many of the toys I've piled on top of this
blog, but its time to revise and simplify.
I've also been thinking of expanding the focus around here a bit: Up
until now, this place has just been the home of my nerdy brane dumps.
But, I'd like to entertain the notion of opening the place up to more
of my writing. Assuming, that is, that I can reacquaint myself with
certain muses and notions of free time and management thereof.
I really appreciate every reader of this site, though, so I've tried
to minimize the impact of changes. Broken links are bad. Links to
individual blog entries from the old site should redirect themselves
to their newly converted counterparts. And, no matter what new trash
I start publishing here, the old RSS feed will continue to show mostly
nerdy brane dumps. Should you want to follow any expanded content I
start to spew here, you'll need to update your links and
subscriptions. It's up to you.
Anyway, thanks for reading, bear with me, and wish me luck.
[ ... 299 words ... ]
By the way, Namber DNS at mysteryrobot.com (found via DiaWebLog) is damn nifty. As I understand it, it works from a set of 256 very short and simple words. Assemble four of these, and you can represent any IP address. Seems like this would make for very easily remembered IP addresses, as well as fairly simple to recite over the phone.
For example: decafbad.com is sing.far.dry.today.mysteryrobot.com
[ ... 294 words ... ]
Whew. Still really busy. Times like these, I wish I had my Blosxom and link-blogger action going, because I'm still out here, grazing on the links everyone else is publishing. I haven't had much energy to write much while wrapping up this work project and getting AgentFrank lumbering about. And there hasn't been much I've wanted to say that others haven't said. So, at least nodding my head by echoing some links would make me feel like I'm still making some useful noise.
Maybe I'll have time for that burn down and rebuild next month. :)
[ ... 104 words ... ]
Oh, and I completely forgot to toss a link his way, but Kevin Smith of electricanvil.com is working on a Java PersonalWebProxy project also. With AgentFrank, I've been leaning toward patching the core together as quickly as possible to enable the plugins and scripting I wanted to play with. But it looks like Kevin's spending more time carefully architecting the core using Jakarta Phoenix & some homebrew proxy work. Would be nice to borrow from his work soon.
Who else has code out there that could be assimilated? :)
[ ... 218 words ... ]
Les has been very quiet lately, but that's because he's been heads down working on his Personal Proxy he's dubbed "Agent Frank" (it's got a little logo and everything). He just set up an Agent Frank ?WikiPage with download and install instructions.
I'm downloading now (it's pretty huge - like 11 megs), but the Wiki page has lots of good info, including Les' new acronym, PIIC. ... Very cool. I'm going to start playing right now.
...
Later... Urgh! It's GPLed! Bleh!
Source:The UPP Lives: OxDECAFBAD Launches Agent Frank .
So Russell noticed my late night release of AgentFrank. Cool! Hope it actually works for him.
Currently it's very big, because it's got everything in it, all the JARs and the kitchen sink from everything I thought I'd start using at some point. My actual original code is likely less than 100k so far, if that. Suggestions are more than welcome.
The same goes for the license - all I want out of this thing is to share it and get interested tinkerers tinkering. It'd be nice if anyone who tinkers with it gets credit for said tinkering, but that's about all I care about. Hell, if it gets incorporated into a commercial product, I'd like some credit, and some cash would be nice, but otherwise I'd just be flattered. Is there a license to cover that? Maybe I should research a ShareAndEnjoy license.
This first code dump is very much premature - I'm not even pretending that this deserves a version number. It's more a conversation piece and an a tangible starting point to play with things I've been thinking. It's 99% crap code that apparently works, at this point. I fully expect it to get rewritten before it rates a version number.
So... have at it. Play with it, make fun of it, send me patches and abuse.
[ ... 1343 words ... ]
I've been quiet - too quiet. Work's had me busy again, as has life in general. But I still have had something in the PersonalWebProxy works:
It's ugly, but it works and does stuff. And I was feeling pretentious enough to give it a quick logo and a wiki page. Enjoy!
[ ... 116 words ... ]
Of course, along with changes I want to make around here, one of the first is the design. Thinking I might follow in Mark Pilgrim's steps a bit, and just strip the thing down to essentials and then more carefully consider what I slap back on the thing. I've been meaning to pay more attention to his accessibility work for awhile now, among other things.
I'm also thinking of ditching Movable Type for pyblosxom - since although I want to tear down the hierarchical filesystem, there still are a load of decades-old tools that I know and love under UNIX to manipulate directories and text files. That, and the MT-to-blosxom converter that came with pyblosxom, along with some tweaks to the genericwiki preformatter, seems to have brought nearly all of my entries across without harm. I'll just have to work out some way to redirect requests for "old" URLs to the new content.
Of course, after that, I'll have to reconstruct my comments and trackback system, among other things... might be fun though.
Oh, and a PS to Wari Wahab of pyblosxom: It works just fine on my iBook, and I plan to use it to preview my entries before they get rsync'd up to my decafbad.com server. :)
[ ... 357 words ... ]
Now using Kalsey's SimpleComments MT plugin. Planning to integrate referrers into it at some point, also, along with an easy yea/nay interface via email or Jabber to ask me whether I want to allow a new referrer to be published or not. Having had my site used to advertise adult movies and anal sex this week was not appreciated.
This blog's first birthday is coming up, and though I doubt I'll have time, I've got a few things I'd like to renovate around here...
[ ... 157 words ... ]
Well, it doesn't look like I'm getting the new Java-based PersonalWebProxy code released last week or soon this week, but if you'd like something to poke fun at, try this...
BookmarkBlogger - a quick hack for Safari users to generate blog entries from bookmark folders.
Hope it's useful, bet it's ugly, but it was fun in the making.
[ ... 321 words ... ]
So... has anyone gotten to making a Perl engine for the Bean Scripting Framework? I can't seem to find a decent archive of the dev mailing lists, and the links from the Jakarta home page are broken. And, of course, Google doesn't help me much except to point me at all sorts of pages saying that BSF supports scripting languages "like Python and Perl", but without actually showing me the Perl money.
Well, if not, I have a horribly hackish and inefficient idea that might just work, involving either pipes or sockets to external perl daemons and extreme abuse of perl's AUTOLOAD and Java's reflection to build proxy objects. Yeah, yeah, someone could maybe embed Perl in a JNI-ish thing, but I'm not at the level of wizardry to be mucking about with Perl guts - nor do I want to be. But, I think this idea of mine just might work.
Why bother? Because it's depraved and possibly very fun.
[ ... 162 words ... ]
Mark Pilgrim is going to unplug for awhile.
Sounds like he's been going through the same woods I trudged through recently, or at least some paths in the same thorny forest. But, it sounds like he's gotten himself even more inextricably bound up in ties to work then me - so much so that he really needs to unplug even from personal net presence to escape. Not just to avoid falling to some abstract sheep-farming burn out, but to avoid the immediate reach of The Client.
So, not that I want to assume to much about you and me, but I think many of us are passionate about the things we're lucky enough to get paid to do - so much so that many of us do work-like things for play. And oftimes, actual work spills into play/personal time. Sometimes it's heroism, sometimes it starts as fun, but eventually, as Mark also recently observed, there remains no demarcation. No amount of human passion or personal love for work can survive when the demands of work inevitably grow to consume all available bandwidth. And y'know, no amount of human sanity can stand for long when one's capacity for effort is described as 'bandwidth'.
Bah. So how do you strike the balance, and where do you dig in? How many do you take for the team, and how many times do you shrug it off at five? The one thing that I saw as positive in the crash of the dot-com age was an anticipation of life-at-net-speed slowing down to something a bit more human, no longer powered by insane sums of money and crack-monkeys of hype. Are we getting there yet?
Good luck, Mark. I recommend trips to the zoo, and close observation of cats.
[ ... 329 words ... ]
Amen. I’ve always found it irritating that news aggregators insert their URL into the referrer field. ... It would be nice if there was some sort of browser header the aggregator could send to identify itself instead of using the referrer field. Oh, that’s right, there is. It’s called User-Agent.
The user agent field is designed for browsers, robots, and other user agents to identify themselves to the Web server. You can even add additional information, like a contact URL or email address. I’d like to see aggregators start using it.
Source:Kalsey Consulting Group: Referral Abuse.
Hmm, being mostly a standards neophyte, I thought this was a great idea, you know, NeatLikeDigitalWatches. I thought this was more a semi-clever overloading of the referer, rather than outright abuse. And this, I thought, was reasonably okay since there wasn't, I thought, anywhere else to stick a backlink to myself while consuming RSS feeds.
Well, yeah, now that I read some of the complaints against this use of referers, I agree. And, yes, now that I read the fine RFC, I see that the User-Agent string is more appropriate for this purpose.
So! From now on, hits from my copy of AmphetaDesk will leave behind a User-Agent string similar to this:
"AmphetaDesk/0.93 (darwin; http: //www.disobey.com/amphetadesk/; http: //www.decafbad.com/thanks-for-feeding-me.phtml)"
I tack my own personal thanks URL onto the end of the list within the parenthesis. In addition, I no longer send a referrer string when I download RSS feeds. How did I do it? Very simply.
First, I modify my AmphetaDesk/data/mySettings.xml file by hand to supply a blank referer and a new user URL (having some angle-bracket problems, bear with me):
[user]
...
[http_referer][/http_referer]
[user_url]http://www.decafbad.com/thanks-for-feeding-me.phtml[/user_url]
...
[/user]
Second, I modified AmphetaDesk/lib/AmphetaDesk/Settings.pm to account for the new setting:...
$SETTINGS{user_http_referer} = "http://www.disobey.com/amphetadesk/";
$SETTINGS{user_user_url} = "http://www.disobey.com/amphetadesk/";
$SETTINGS{user_link_target} = "_blank";
...
Third, I modified the create_ua() subroutine in AmphetaDesk/lib/AmphetaDesk/WWW.pm to actually use the new setting:
sub create_ua {
...
my $ua = new LWP::UserAgent; $ua->env_proxy();
$ua->timeout(get_setting("user_request_timeout"));
my ($app_v, $app_u, $app_o, $user_u) = (get_setting("app_version"),
get_setting("app_url"), get_setting("app_os"), get_setting("user_user_url"));
$ua->agent("AmphetaDesk/$app_v ($app_o; $app_u; $user_u)");
...
}
And voila - no more referer abuse. If you want to discover my thank-you message, examine the User-Agent string. Seems like this would be a good idea for all news aggregators to pick up. And if I get ambitious and have spare time today, I'll be sending off a patch to Morbus & friends later today.
Update: Gagh! This has been the hardest post to try to format correctly within the fancy schmancy auto-formatting widgets I have piped together. All apologies for content resembling garbage. I think I'll use this excuse in the future whenever I write something completely daft. (Which means I'll be using it a lot, most likely.)
[ ... 1145 words ... ]
I couldn't resist a bit of tinkering with NNTP, partly to follow up a little bit myself on RSS to/via NNTP, but mostly in fact to re-acquaint myself with the wonderfully arcane configuration of the majestic beast that is inn . In addition, there's been talk recently of aggregators moving out of the realms of satellite applications and into the browser itself. The Blagg and Blosxom powered Morning Reading page - my personal (but open) news aggregator - is already web-based, so I thought I'd have a look in the other direction.
Source:DJ's Weblog: Tinkering with RSS and NNTP .
I've been toying around with doing this with inn for quite some time now, so I'm happy to see someone else actually follow through and give it a whirl. And, using blagg with a plugin to do the posting seems just the right twist of clever.
Yeah, inn's a beast and meant for Usenet-scale beating, but it's Just There on many Linux installations. And blagg seems to do a decent job of prying content out of RSS feeds, with just a few regular expression incantations. DJ didn't have to reinvent an NNTP server, or create a brand new aggregator - just a few tweaks and glue, and two existing apps are joined in a completely new and interestingly complementary way.
Though one thing he says: "As I saw it, there are two approaches to newsgroup article creation ... Send items from all weblogs to the same newsgroup ... Send items from each weblog to a separate newsgroup." First thing I was wondering is: Why not cross-post the articles and have both?
And then there're the ideas for experimentation that come first to mind: "... Combining the various weblog trackbacking mechanisms with NNTP article IDs to link articles together in a thread; replying (to the newsgroup) to an article might send a comment to the post at the source weblog."
Kinda retro, kinda nouveau, joining the new distributed RSS net up with the semi-distributed NNTP net.
[ ... 389 words ... ]
So I'm thinking that I might prematurely release some code before the week is out, so anyone who's interested can point and laugh at my PersonalWebProxy exploits - this time in Java.
One thing that disturbs me a bit about this thing so far is that, for what I have in mind, I'll have built a mini-OS when all is said and done. It'll have a web server, a web proxy, telnet-able shell, scripting languages, scheduler, full text search and index engine, persistence & metadata storage, and whatever else I can eventually think to toss in. There are just so many nice toys for Java, and most are a snap to glue together. But, I can't really use any of the toys that come with the OS itself.
It's something I've rambled on about before, as has Jon Udell in his old Byte column: Zope Lessons Learned. If this thing is to run on more than one platform, it can't rely on the facilities of any particular platform. So, all these lovely things I like OS X for are somewhat off limits.
On the other hand, if I get tired of doing this thing in Java, I could always just finally embrace the platform and go straight for Cocoa. :) Yes, that would make for 3 environments tried, but hey - it's still fun for me!
[ ... 435 words ... ]
interestingly, it seems that besides myself there are a goodly number of people wondering about the etiquette surrounding foaf friend declaration. while it's mostly a social and not technical problem, it's precisely the sort of thing that will keep foaf from reaching any kind of critical mass.
Source:snowdeal.org, ex machina.
I've wondered a bit about this, too. If I've heard of you, can I list you as a friend? If I've emailed you once or twice? How about if I've dated your sister?
However, Eric Vitiello Jr. has an interesting schema for further specifying relationships in FOAF.
[ ... 283 words ... ]
Log::Log4perl is different. It is a pure Perl port of the widely popular Apache/Jakarta log4j library for Java, a project made public in 1999, which has been actively supported and enhanced by a team around head honcho Ceki Gülcü during the years.
The comforting facts about log4j are that it's really well thought out, it's the alternative logging standard for Java and it's been in use for years with numerous projects. If you don't like Java, then don't worry, you're not alone -- the Log::Log4perl authors (yours truly among them) are all Perl hardliners who made sure Log::Log4perl is real Perl.
Source:perl.com: Retire your debugger, log smartly with Log::Log4perl! .
Wow, I hadn't noticed this before. We've been looking for a Log4J-workalike in for our perl-based web apps at work, and thought CPAN:Log::Agent was where it's at - and it still may be - but CPAN:Log::Log4Perl looks very keen now.
[ ... 297 words ... ]
A new and better way to experience the "Dive Into" empire! For only a few cents a day, you get fast, uncluttered access to your favorite "Dive Into" sites, with premium features available only to subscribers.
Source:Dive Into Premium .
Finally! All of those pop-ups, pop-unders, DoubleClick cookies, and epilepsy-inducing banners were really getting to me. And if Mark Pilgrim can do for full frontal nudity what he did for web accessibility, I'm sure we're seeing the start of something big here.
[ ... 176 words ... ]
And one more post for the night: I wish Safari gave AppleScript access to read and manipulate bookmarks. If it does, I can't find it. I've been playing around with AppleScript folder actions, Matt Webb's link blogging folder hack, and BlogScript. I've been thinking, for good or bad, I'd like to do more link blogging. Well, in Safari, I've created a toolbar bookmark folder called "READ/BLOG QUEUE" into which I drop links for later reading and/or blogging.
So... If I could get at that bookmark folder via AppleScript, I could schedule and generate a templated blog entry for auto-posting every night, listing just the links I've left in that bookmark folder, and clear it out when it's all done. I could do the same thing with just a Folder Action enabled desktop folder, but it's just so much more convenient to drop things on the toolbar.
And then, there's the other wild idea I'd use scriptable bookmarks for: RSS aggregation. Imagine bookmark folders dynamically generated and updated from RSS feeds. Maybe even one big bookmark folder with RSS items aggregated from many feeds. This seems somewhat appealing to me.
[ ... 230 words ... ]
Have I mentioned lately that I ♥ BeanShell for Java?
I haven't said much about it lately, but I'm still working on my PersonalWebProxy - only this time I'm playing with Java and all the goodies I was wishing for while in Python. I've got Jena and Lucene and HSQL and BSF and Quartz and Muffin and... well, a lot of stuff that feels pretty nice to me.
But, with respect to BeanShell in particular, I've got a lot of the nifty live hackability that I had with the things I was playing with in Python. With no more than 5 lines of code, I've tossed a live interactive shell into my running proxy, into which I can telnet or access via Java console in a browser. With this, I can get into the machinery before I take the time composing a UI, inserting/removing plugins at will, tossing together new proxy filters on the fly, composing RDQL queries adhoc, tweaking Lucene searches.
Fun stuff, and so easy. But, sorry, no further code from me yet. It's very ugly, and barely works, but it's just a sketchpad at the moment. I hope to have a little something before the end of the month to pass around, should anyone still be interested.
[ ... 235 words ... ]
Apple's Script Editor 2.0 for OS 10.2.3 has support for Application Services . Basically, you can hilight some valid AppleScript text in any supporting application (like Safari, for instance) and
execute the script [or]
get the result of the script [or]
put the text into Script Editor.
Source:Mac OS X Hints: Run AppleScripts via system services.
Neat! Now... can we do something about making access to those services a bit more prominent? System-wide functions buried in a menu obscurely labeled "Services" under an app-specific menu label doesn't seem very inviting or intuitive. AppleScript gets insanely better treatment than this. I'd like to see these services pushed just as far forward, and more easily discoverable. It's been awhile since I played in Cocoa, but for awhile I was wondering if rearrange things a bit, maybe pull the service items for the currently active app into a menu extra or something. Or, at least pull the menu up a level, maybe stick it next to the "Script" where appropriate. And, I'd love to be able to customize the keyboard shortcuts assigned to them - some have shortcuts and I'll rarely use them, while others have no shortcut and I wish I could use them all the time.
It's good stuff, Apple, show it off.
[ ... 291 words ... ]
Vellum is a server-hosted application to run weblogs for you. It's like MovableType or b2, in that it's hosted on your web server. And it's written in Python.
Source:Vellum: a weblogging system in Python .
Need to check this out, have been itching to revamp this place and rethink what I want to do around here since it's coming up on my 1st full year out here in the blogosphere at large.
Funny thing, too, is that the coffee-ring-like background image on that page looks exactly like some of the first designs I played around with for my site. Only his looks much better than mine did. :)
[ ... 109 words ... ]
Apple's Cocoa library contains two very good table controls, ?NSTableView and it's close relative, ?NSOutlineView . However, both of these controls have one large limitation: All the rows must be the same height. This is an issue when displaying table cells with content that varies in height, such as large amounts of text or images. Luckily, Apple's Cocoa controls were also very well designed, making it possible to add this functionality simply by subclassing the table views. ?RowResizableTableView is an ?NSTableView subclass which allows each row to have variable heights, and ?RowResizableOutlineView is an ?NSOutlineView subclass with the same functionality.
Source:RowResizableTableView: Variable Row Height Tables and Outlines .
Wow. Although I think my Arboretum project is very likely asleep for good, it was the want for this particular component that most discouraged me from continuing with my outliner. Nowadays what keeps me away is the absolute brilliant quality OmniGroup's OmniOutliner and the fact that it supports AppleScript, and furthermore, the fact that AppleScript has its tendrils in abso-freaking-lutely every app that seems to matter to me. So, I can pretty much have everything I wanted to have out of Arboretum right now.
But I'd still like to come up with a decent project in Cocoa for myself. It's just so damn comfy to develop with.
[ ... 216 words ... ]
I've been wasting some of my time playing the superhero role-playing computer game Freedom Force, which turns out to be done in Python.
Source:The Happiest Geek on Earth: Python for superheroes .
Swanky! I've been thinking about getting that game, off and on, wondering if my aging 600Mhz desktop PC would run it. It looks like a hoot - and if it's that nifty under the hood, it should be pretty fun to hack with occasionally. :)
[ ... 78 words ... ]
It's only day two, yet I have nothing to Moblog today. Yesterday I was bopping around the city from my main office to the Sun testing center to lunch with my wife. Today I'm at the office in front of my computer, where I will probably remain until after dark. I guess I can moblog my lunch... It probably won't be that exciting.
Source:Russell Beattie Notebook: Moblogging Thoughts .
Is Russell losing the Moblogging faith already? :) He raises an interesting, mostly obvious point: After all the whiz-bang setup and build up - what do you have that's so important that it's worth covering in mobile multimedia splendor?
On one hand, some would say, "Nada mucho," and hang up their camera peripheral. Me, well, I don't have the hardware yet to deluge my corner of the web with instant snaps and clips of me, my girl, the cats, and co-workers. (Though I have gotten a start on it.) But, I find what Russell's posted so far to be fascinating and amusing. Of course, he's in an exotic locale with respect to me. Why else, unless he was a photographic genius, would his lunch seem interesting to me? Then again, I might be in an exotic locale with respect to someone else.
Anyway, after all the fun of connecting various bits together, you always come back to finding a reason to use it if you hadn't had one to begin with. Sometimes the reason ends up being that it's just fun to play with bits connected together, and that someone somewhere might just find the result interesting. No one's forcing anyone to look at all the pictures of the world's cats, you know?
[ ... 369 words ... ]
It seems that beyond carrying syndication information, RSS is a very useful and flexible way to get all sorts of application data pushed to a user over time. In the same way that a web browser is a universal canvas upon which limitless services and information can be painted, so (in an albeit much smaller way) an RSS reader/aggregator might also find its place as an inbox for time-related delivery of all sorts of information.
Source:DJ's Weblog: The universal canvas and RSS apps .
My thoughts exactly. Not sure if I've posted here about it, but I know during the whole RSS hubbub this fall, I'd babbled something about RSS being a messaging queue from machines to humans. Or a transport for timely ephemera to people. Or something like that. Basically, I'd like to see RSS, or something like it, used beyond just headlines. This is why I've leaned toward the RDF-in-RSS camp - I want to see lots of things besides titles and excerpts hung off the individual message events, and RDF seems downright nifty to me for this.
But either way, I like the expanded notion of RSS usage as a timestream-oriented stream of messages targeted at subscribed people.
[ ... 365 words ... ]
I used an HP 1200bps external modem. To connect to BBSes. When I was in elementary school. I remember tearing through the latest Focke's BBS list. It was the definitive guide to DC-metro BBSes. I'd print it out on my Okidata dot-matrix printer on fan-folded continuous feed paper with the holes on the sides. Then I'd grab a pen or pencil, mark up some interesting BBSes, fire up Procomm and try to connect.
Source:postneo: 1200 bps .
Oh yeah? Well, my first experience with dialing up in Jr. High was with a 300 bps modem on a C=64. I used to pour over Horst Mann's 313 area code BBS list and sneak in calls to long-distance BBSes throughout Michigan, for which I'd later pay dearly out of my allowance. :) I remember coveting my friend's hulking Tandy PC and its 1200 baud modem (nearly a full screen of text at one time when playing BBS games). Then, I bought a 2400 baud modem with an adapter, and became the envy of everyone - until they all moved up to 2400 and then 14.4K.
I'm sure someone else can give me an oh yeah, too, and we can work up a skit ala Monty Python's "We Were Poor". ("You were lucky to have a lake! There were 15 of us living in a cardboard box in the middle of the road!")
What I really miss from the BBS days, though, is the local community. Used to be that far away places were far away, and near places were near, and you had to go through the near places first before you could visit far places. So, communities formed around BBSes, even as those around be began changing into mere portals onto the internet, and then later to become fledgling dialup ISPs. Nowadays, the distance between points on the net is measured in terms of interest, attention, and affinity, without regard to physical location. It's so much harder to get together for a cup of coffee with the people behind the keyboards these days. :)
[ ... 444 words ... ]
If I did have comments on my weblog it would be like Slashdot, a very low signal to noise ratio. Don't blame me for that, it comes with longevity and flow. The longer the site is around and the higher the flow, the more losers one attracts. I can see where these things work for a lower flow site, but they would never work for Scripting News, I'd have to turn it off quickly because of the low-roaders.
Source:Dave Winer in comments on Simon Willison's Weblog.
Although I'm too lazy to search for the links at the moment, I've sung the praises to automatic trackback and referrers and friends. Like Simon, I've also bemoaned the apparent lack of participation Dave has in this self-organizing chaos of blogs auto-discovering each other.
But, Dave's right. Get too much flow, piss off too many people, say too many controversial or contrary things against too many camps - in other words, assert a strong opinion, right or wrong, and get it read widely enough and do it often enough - and your weblog will turn into a cesspool with all its graciously thrown open doors clogged with trolls.
At present, I'm safe. My rating is Mostly Harmless, so all my open systems are mostly free from abuse. But, the first time I really strike a nerve somewhere, I'm a sitting duck.
I've got some pretty pretentious ideas floating in my head about how this relates to an open civilization and culture in general, but I'll save them. Basically, I don't want to give up my openness, but I want to deflect the barbarians. Need to think more, but I suspect this may cross streams with the spam crisis, eventually.
[ ... 303 words ... ]
Oh yeah, and further along the lines of filesystem sacrilege, my most used OS X apps are:
Searchling
LaunchBar
Both of these give me lightning fast access with keyboard-shortcut finger twitches to what's on my mind and what I want to do. I want to find more things like this.
[ ... 88 words ... ]
Gosh, I've been quiet lately. What could be the reason?
1) I'm sick of blogging (not likely) 2) I've been having a life away from the computer (not likely) 3) I've been heads down doing something cool that I'll shortly be blogging about? Hmmm....
Source:Russell Beattie Notebook: Quiet .
If you're careful and look hard, you'll find what he's teasing about. Go look - it's not in the quote above.
[ ... 71 words ... ]
Dear Operating System Vendors.
I no longer want to know where my files are stored. I no longer care. I have hordes of directories on my various computers called stuff ,downloads and documents , and the effort that it would take to organise them into a proper heirarchy is just not worth it. The heirarchical filesystem is a really wonderful thing for programmers and websites, but it just doesn't cut it for personal use.
I no longer care where my files are stored.
Source:The Fishbowl: Filesystem sacrilege.
I'll be burned at the next stake over from Charles when the time comes, for this filesystem heresy. Just the other night, a co-worker was asking me about how diligent I was in organizing my email. I told her, "Not at all. I leave it all in one pile and then run the Find command on it later." She was shocked that I, alpha geek and info freako, didn't have some intricate taxonomy of folders into which mail was sorted by carefully crafted filters.
Years ago, when I first started using email, I did indeed do this with procmail and other arcane beasties. Then, I found myself cursing that I couldn't do cross-folder searches very easily. Also, the filters and folders started making less sense as their structure represented only one possible scheme for finding what I was looking for, and I was needing many possible kinds of schemes over time. So, eventually it all ended up in one pile, and searches became my way of finding things.
I abandoned bookmarks for Google by the same principle. Now, my bookmarks consist completely of bookmarklets and a few stray links to local on-disk pages like Python documentation. In fact, I'm wishing that I could create bookmark folders that are fed by Google API powered persistent searches.
So, now I'm looking balefully upon my filesystem. I haven't had much chance to play with BeOS, but I've read about the design of the BeOS file system and drooled. I hear about Microsoft's Longhorn and its WinFS and grind my teeth - I very much dislike Microsoft, but if they pulled this off, I'd have to sing their praises. Apple? Do they have any aces up their sleeves in this regard? Don't let a new fanboy down. :)
Anyway, that's what I want to see: Storage without explicit organization, but with super-rich metadata for super-fast searches. Allow me to create views made from persistent searches - my "project folder" is simply a collection of resources tied together by a common tag, one of many. And, if I want to form a project hierarchy, make my persistent searches into file objects too.
The main thing in all this, though, is that it be woven very deeply within the OS. I don't want a helper app. I want this to replace the standard metaphor completely.
RDF triples at the inode-level anyone? Heh, heh.
[ ... 940 words ... ]
I've been thinking about the whole "I need tabs in Safari" issue, and have come to realize that no, in fact, I don't need tabs in Safari. ... What I need is a way to manage multiple open web pages in a single window. ... I've done a quick and dirty mockup of something that approaches what I'm thinking about.
Source:D'Arcy Norman's Weblog.
So, yeah, not that anyone needs my US$0.02 added to the cacophony around Safari, but here it is anyway. Go check out D'Arcy's mockup. I think this is precisely what I want. I've been keeping myself using Safari since it was released, and I've been disappointed with it very rarely. Instead of tabs, I've been heavily using the Window menu, wishing for some window navigation shortcuts (ie. prev, next, 0-9 for first ten windows?)
Anyway, I say: tabs can go, but give me a sidebar.
[ ... 350 words ... ]
Wow, take a look at The Cocoanization of Kung-Log:During the New Year holiday I started getting acquainted with Cocoa programming by converting my ?AppleScriptStudio Kung-Log app into a Cocoa version. Well, smack my ass and call me Judy, it's done !
It'd been awhile since the last time I checked out Kung-Log - when it was working for me, it was my absolute favorite way to update this site, but then it started breaking in a few places such as recent post retrieval. So I gave it up. Then tonight, on a whim, I looked. And whew, a complete rewrite, apparently release just this night. Talk about coincidence.
Nice.
[ ... 143 words ... ]
Lazy Mac OS X: Weblog links sidebar: ...it's going to be about turning your Mac into a weblogging machine. As easy as the links-and-commentary genre is with all the blogging apps out there, I'm too lazy for the commentary bit, and so I tend to drag-and-drop links to my desktop for later posting -- and then promptly forget about them. Consequently my desktop is a mess, and my blog is stagnating. Bad.
So... what he made, with AppleScript's Folder Actions, is a magic folder on his desktop. When links are dropped into the folder, a script is triggered which posts the link to a weblog via BloggerAPI. I've tweaked it a bit to ask me for a link title, quote, and a tiny bit of commentary, but it still needs a bit more work.
I had never heard of Folder Actions before this. This is very nifty stuff - blogging woven into the OS X desktop itself with AppleScript. Whew.
What I'd really love is to be able to drop a folder onto my dock, and then drop things onto it there. I'm thinking of a bunch of "bins" on the dock that shuttle files off to different destinations and through various transformations, right there, always in view.
[ ... 341 words ... ]
Using OmniGraffle as an RSS News Reader with AppleScript: To learn about the capabilities of a new application in its enhanced AppleScript capabilities, a project is created that turns ?OmniGraffle into an RSS News reader unlike any that are out there.
This rocks. Been a little quite lately, busy at work, still tinkering with my proxy. And now I find myself poking around into AppleScript again. Wheee!
[ ... 68 words ... ]
Speaking of BML, what ever happened to it? I first wrote about it back in August and later got a response from Sanjiva Weerawarana, one of the original authors at IBM. Someone hinted to me that it was supposed to eventually land at Jakarta, and while the Bean Scripting Framework did land there, BML is still off the radar. Meanwhile, I'm still using it at work, still sitting on some dubiously-gotten source code, and want to use it in more public projects.
Anyone out there in Java-land besides me know about this thing and find it useful? While it's still very likely that I'm delusioned, I have yet to find something equivalent to what it can do for me. On the contrary, I've seen other projects rolling their own much less functional versions of BML. But, I have to assume that I'm not realy a know-it-all, and that I'm likely missing something that makes this not-so-great and relatively unadopted.
[ ... 182 words ... ]
I'm still not entirely sold on Python and Twisted as the foundation for my PersonalWebProxy. Yeah, I know I just release a bunch of code to that effect, but it's still just a proof of concept. While there are some impressive things in Twisted and Python, there's also a lot of flux and immaturity there. Not a bad thing, since the hackers in that camp are doing mad crazy things, but I don't want to focus on mad crazy things in my toolkit - I want to focus on mad crazy things built on top of it. The thing I've been hoping for is that some of those mad crazy things in the toolkit would enable even madder crazier things down the line for me. This may be true still - so I'm not tossing anything out, just still experimenting.
So far, this is just playing for me. For fun, I think I might do the whole thing over again in Java and play in parallel for a little while. Well, not quite all over, since I think I've found some pretty ready-made components:
Take Muffin, for example. It's a Java proxy that looks like it's been dormant for quite awhile, but seems ideal on the surface for my needs. Just today, though, I checked back in the project's CVS repository and it seems that there's new activity and checkins starting up in there. On the other hand, I've also been poking at Jetty and the proxy classes it comes with. Seems like there's a lot to work with here, and I have a better vibe about it.
Besides that, Jena seems stronger than rdflib for RDF support, and I'm just biting at the bit to pour damn near everything at Apache Jakarta into this thing. Also, I suspect I may be able to preserve the quick scripty hackability I want out of the this thing by using BSF and Jython, with some assembly and config in BML.
Hmm. Still tinkering.
[ ... 486 words ... ]
In case anyone's interested, I've been hacking like mad on my toy proxy since New Years'. Check out PersonalWebProxy for current downloads. It's got primitive forms of proxy filters, browser-based UI, RDF-based metadata management, logging, config, plugins, and some other goodies. So far, the major plugins include:
a noisy logger;
a content archiver that captures and saves all response headers and content in a directory structure loosely based on the requested URL;
an initial metadata harvester that fills up the RDF database with triples based on headers and details encountered during browsing
It works, and does stuff, but I'm sure it demonstrates a complete lack of understanding of large portions of the Twisted framework, Python itself, and likely causes forest fires. So, I hope many people will download it, snicker at it, and maybe set me straight on a few things and contribute a few patches and plugins.
ShareAndEnjoy!
[ ... 433 words ... ]
So... yeah. I watched the keynote, and I'm lusting over the new mini-me ?PowerBook with a plan to purchase in the Spring. I was aiming at a high end iBook but holding out for something better, and well, this new ?PowerBook is the precisely what I was holding out for. It appears to be the rightful successor to my formerly beloved Sony Vaio 505TR.
Then there's Safari. Mark puts it under the microscope, as does Mena. On the other hand, Ben writes that it's almost-shit. Oh yeah, and JWZ reports: "Apple says 'fuck you' to Mozilla" But he's not bitter.
I haven't got the chops to seriously test the thing, so I'll be watching the more spec-wise out there for info. But, what I do think about it makes me sound like an Apple fanboy: I think it's great.
It's not perfect at the moment, but I've got a feeling that this will change. And fast. Mozilla's shipped with talkback, but Safari's got a bug submission button right up front. And the fact that they did snub Mozilla for a dark horse like Konqueror seems a bit provocative (at least in techie / Open Source circles), and after all that talk of innovation I doubt that they're going to let it rest as-is or back down. I expect lots of movement from here. Think different and all that. And, from my minuscule bits of Cocoa dev, I'm looking forward to poking around with ?WebCore and the ?JavaScript framework. Unless it's a complete disaster, I expect the building blocks of Safari to pop up in projects everywhere.
These things tell me to expect good things from Safari. I hope Mozilla can keep up. As for IE, well, I deleted that a long time ago.
[ ... 332 words ... ]
I needed and found a little help enabling readline support for Python under Mac OS X. I love a lazyweb so lazy that solutions to my problems have already been posted. :)
[ ... 33 words ... ]
Okay, this is getting close to outstripping my enthusiasm and invoking my laziness: Does anyone happen to have RDFLib and ZODB working under Mac OS X 10.2.3? Have also tried compiling Redland and its Python and Java APIs, but that's not been a 100% success. Or can someone recommend another decent RDF repository to play with under Python? I've had fun with Jena under Java, love using RDQL, and dig switching between MySQL and BDB stores.
I want an RDF repository I can integrate into my proxy experiments, currently implemented in Python. I've been very tempted to switch to Java, which I know better and have a better sense of tools available. But I'm still pulling for Python. I suppose I could just go with an in-memory repository at first, but I don't want to stick with that.
I'm still finishing up the PersonalWebProxy notes and plan I've been working on, but I've still got an itch to play in code. The next major thing I want to do is extract as much metadata as I can from every HTML page I visit and load the RDF repository up with statements based on what I harvest. Examples would include things like HTML title, visitation date, referring url, any meta tags, any autodiscovered RSS and FOAF URLs, and anything else I could eventually dig out. Then, I want to amass some data and play with it. I'm thinking this could give me a kind of uber-history with which to work.
Update: Seems like I managed to get Python, RDFLib, and ZODB working, but I started completely from scratch and compiled everything from clean source. I guess Apple's build of Python has more hiccups in it than just the Makefile thing.
[ ... 420 words ... ]
Just in case this wasn't common knowledge, it seems there's a bit of a boo-boo in Jaguar's installation of Python that sticks it head up when one tries to compile extentions (like, oh say, the Standalone ZODB).
Line 62 of /usr/lib/python2.2/config/Makefile reads:
LDFLAGS= -arch i386 -arch ppc
But, I think should read:
LDFLAGS= -arch ppc
Making this change appears to have gotten the thing compiling, though it may also cause my iBook to eventually self-format since I barely understand everything involved.
Ugh, though now that everything's compiled without hitch, the test script goes belly up with a bus error. Time to go back googling to find a solution or somewhere to whine. I may also swap back into Java, since I like Jena better than anything I've found in Python for RDF support.
[ ... 304 words ... ]
Teasing everyone with a solution to something we MovableType users been hacking around with for awhile, Ben Trott writes:We envision Text Formatting options as complete, encapsulated formatters, handling both the formatting of structured text and any desired typographical details (smart quotes, etc), analogous to the way in which Textile handles quote education and its own miniature formatting language.
Plugins will be able to easily add new Text Formatting options to the menu on the New/Edit Entry screen.
Yay! Text formatting as a first class feature in MovableType - used in previews, as well as in publishing. No more including plugin tags in every single template ala MTWikiFormatPlugin and friends. Rock on! It's a good thing when hacks I write get outmoded by a more elegant treatment.
[ ... 126 words ... ]
Anthony Eden writes:I was so intrigued by having a proxy agent which would work for me that I wrote a little generic pluggable proxy this morning.
Show us the code! :) I want to play.
As for my code so far: This is extremely premature, and I'm not even sure if it will work anywhere besides my peculiar iBook, but here's a quick & dirty tarball of my experiments with a PersonalWebProxy (just web, not universal) with a simple plugin API, in Python using Twisted:
dbproxy-20021231.tar.gz
It's poorly commented, doesn't do much useful, but it's a few nights' work by someone just getting acquainted with Twisted - if you're even worse off than me and want to poke at this proxy thing, maybe this will help you. It does do a few things I thought were nifty, like use Mark Pilgrim's rssfinder script in a thread to dig up RSS feeds for every URL with text/html content you visit. There's no persistence yet, so they just appear in the log, but figuring out the integration and thread use so far was nifty to me.
Anyway, enjoy. I'm still tinkering, thinking, and working up a plan.
Oh yeah, and I'm watching Dick Clark and the ball drop with my girlfriend, so this post brings an end to hacking for the night.
[ ... 379 words ... ]
Following in Russell Beattie's outliner brain dump footsteps, I revised my PersonalWebProxy page with cut-and-paste from my own outline in the works. It's far, far from complete, especially in the planning department, but I figure it could be worth poking at just to check out the developing direction.
Having trouble getting to Russell Beattie's blog at the moment, so a link will have to wait.
[ ... 66 words ... ]
Continuing along with the PersonalWebProxy meme, Russell Beattie writes:I have a lot of trouble with motivation on something like this. I get excited then I flip out because of how much something like this could entail and I find other stuff to do for a while to calm down. This has been going on for months. ;-)
Yeah, and then there's that. Seeing what people are wishing for out of this class of app, we could wish it into the outer reaches of tinkerer feasibility and then get fed up and go home. That's what I'd like to avoid, personally.
I'm puttering around with a bit of a spec for myself today, laying out a limited wishlist drawn from mine and others' ponderings and rationing it out into chunks. There's no way anyone could handle creating the perfect proxy/agent for the next millennia without descending into insanity and obscurity some 1% into the process. But, if things can be worked out to where it's being cobbled together in a process of loosely structured madness, there just might be hope.
The crucial thing is that it move forward in tinkerer-sized steps, remain understood and tested at each point, and do some reasonably useful new thing after each lurch in order to remain interesting. The process should give tinkerers a chance to spend just a little bit of their non-copious free time to come up with something clever and nifty. This is how the lazyweb works.
Okay, before I start getting too pretentious here, I'd better get back to work.
[ ... 427 words ... ]
On the cite tag, Mark Pilgrim writes further: "All right, everybody just calm the fuck down. It?s only a tag. I didn?t expect the Spanish Inquisition." Don't I feel like a fan boy? :) Heh heh.
And, oh! that INS tag! Must be something in the post-holiday egg nog.
[ ... 50 words ... ]
Russell Beattie writes: The idea in my mind is for a project that would be a universal personal proxy (UPP) that sits between you and the internet. It would be a web proxy, email filter, spam cop, a place for agents and schedule tasks to run and more. It would be responsible for both receiving and sending of information - as web pages, emails, web services requests, ftp file postings, etc. In the middle it would do analysis like for Spam or RSS autodiscovery, intelligent bookmark history, etc. ... This sort of app would be for people like myself who spend an innordinate amount of time on the internet.
Precisely. Exactly. Even down to the combination of P2P and desktop-to-server mix he writes about. I think we're starting to ride a meme here. This is what I want from a PersonalWebProxy. I've been trying to think of a better name for this class of app - it's more than a literal web proxy. I want an agent and an assistant - something that sits shotgun with me while I putter around and can help me study what I do and see. I want something that can eventually do things in my name for me, if I allow it. I want basically all the things Russell wants, along with everything agents do for the characters in David Brin's Earth.
So. How to do this? I think I need to spend some more time fleshing out a spec before I do much more in terms of putting gadgets together. Need to reign in the fantasy, lay out some feasible first revision features, and start. I want it all, but I want to start out with something hackable, useful, and inviting for collaboration.
Still probably too early to be thinking about implementation language, but I have been experimenting and expect some of these things to become the base for my development. My ideas on choices have become less clear-cut now. When last I wrote about this topic, and languages, Donovan Preston left a comment enlightening me with regards to my Python/Twisted vs Java/Threads consideration. In fact, threads are available in the Python/Twisted environment as well. So, now I'm back to thinking about things like free library availability, environment maturity, possible collaborators, and my own comfort level in each.
Bah. At this point, I think I know all I need to know about what various environment choices can do in order to come up with a set of features that can be reasonably implemented in either or any environment. Need to solidify this wishlist into a task list and design and get going.
[ ... 730 words ... ]
Although I did begin my days on the web by pouring over the HTML and HTTP specs back in 1994, I soon abandoned that effort and learned how to make web pages by example like most webmonkeys and hacks came to learn it. I wasn't ready, back then, to read a document like the HTML spec. But now, Mark Pilgrim makes me want to give it another serious shot, having leveraged the CITE tag in his weblog writing to pull a view of his entries by cited source. He's good at sneaking in smarty-pants things like that - you probably never knew he was doing it, you think it's wonderful when later revealed later, and then you wish you'd done more homework. Maybe "you" is just me. :) You think he plans these things in advance? I want the Mark Pligrim syllabus.
Of course, the problem with the way so many webmonkeys learned to apply some semblance of web standards was the web browser. If it showed up nicely in the browser, it was Good. If ugly, it was Bad. If invisible or without apparent effect, it was Ignored. And this mindset worked great for the busy page builder up till 4:30am trying to cobble together the latest brochureware site.
But now, after all the rushing around and recontextualization of business, it seems we're in the Winter season around here on the Internet. Not so much new feverish development going on, but a lot of reexamination and introspection - and actual reading of specs. And some really nifty things are going on, like the "rediscovery" of things that were there from the start but not too many people were careful enough to pick up on them at the ass crack of dawn while trying to launch another blight on the web. (No I'm not bitter about those days at all - no wait, yes I am. :) )
So, anyway, Mark Pilgrim wrote: "Let?s try pushing the envelope of what HTML is actually designed to do, before we get all hot and bothered trying to replace it, mmmkay?" I really like his point. Now that we're done rushing around trying to solve the insane demands of the moment, or trying to "add value" for the stockholders, maybe we can do more mining into what's already out there that we all trampled and stampeded past in the early years.
Or, rather, maybe I'm a "we" of few or one here, since obviously some people have already started mining the hills for neglected gems.
[ ... 423 words ... ]
It's not incredibly complicated, but it's something I just hadn't gotten to until now: My AmphetaDesk subscriptions are now the source for my blogroll. I noticed the opml2html script that Jeremy Zawodny wrote, snagged it, and set up a quick cronjob to run the script and upload the HTML every few hours. It's ugly right now, but maybe it will finally make finish that new design.
[ ... 167 words ... ]
Chris Winters threw me a link to my recent ramble on completely planned perfection versus workable organic imperfection in software design. After citing a very good perspective on software as gardening from The Pragmatic Programmer, he writes:As I've mentioned before there are a number of software development practices moving toward a more humane process. And I think the ideas underpinning worse-is-better play a big part in this. The major one in my mind is this hypothesis: there is no such thing as a perfect software design. Have you ever seen or heard of one? What design hasn't been modified over time due to changing needs or conditions?
Good points. Still trying to find the middle ground between clean design and fecund dirt. There's no perfect design I've ever run into in my time so far, and I don't expect to. But, what I have learned, is that where there is no design at all, you have disaster.
So I guess the main thing I've learned so far is that this guilty love of a dirty yet elegant hack while giving myself a "tsk-tsk" with a hope to design it more fully next time is useless. There will be no time that I've participated in a design that ends up being marvelously perfect. But what I'm trying to feel toward is how to get the balance right between clean and dirt, given skill levels and team sizes and project complexity.
[ ... 239 words ... ]
Matt Griffith proposes a virtual project: Jog. For the most part, what he wants is what I want from my PersonalWebProxy, and more.
The big difference in the writing, though, is that Matt writes from features and what he wants, where I'm already describing things in terms of implementation. That is, I started talking about "proxy" where he's talking about "my personal Google and Wayback machine". I think looking at it that way makes a more compelling case for this thing being generally useful, rather than just some nerdy toy.
Another way I'm looking at this PersonalWebProxy is as an assistant in a sidecar attached to my browser. I want this assistant to watch me, learn, and pipe up from time to time with suggestions. I also want to be able to ask questions and to remind me of things I vaguely remember. Eventually, I'd like this assistant to be able to drive for me from time to time, doing some info hunter-gatherer work for me while I do other things.
I'm still working on this thing. So far I've got a proxy in Python and a simple-minded plugin framework. Two plugins so far: one is a cookie jar separated from any browser - that is, cookies are managed in the proxy, not in the browser; the other is a little thing based on Mark Pilgrim's rssfinder.py that quietly seeks out and gathers RSS links from every text/* resource I view. It seems to be standing up fairly well.
My next steps are something along these lines: Should I continue in Python? To do so means delving deeper into Twisted, using their web app framework for the management UI and staying within their event-driven paradigm in lieu of threading. The reason I first chose Python is because I wanted something that was quickly and easily hackable and fun to contribute plugins for. Does this still apply, if things are deep in the Twisted mindset which is not quite straightforward?
On the other hand, I took a peek at Jetty in Java, which also comes with a simple and hackable HTTP proxy implementation. I could easily cobble together in Java what I have in Python using this. I would also say that I could easily make it compatible with whatever plugins were written for the Python version, using Jython, but there's also a paradigmatic difference were I to go with Java: Threads in lieu of event-driven design.
Maybe I'm thinking too much about this and should just keep doing what I'm doing. I'm trying to think and second guess a lot about what anyone who might care to play with this thing would actually care about. As for myself, I seem to be having fun with things as is.
[ ... 1391 words ... ]
Mark Pilgrim writes: "I am now a card-carrying associate member of the Free Software Foundation. Software is free, but lawyers are expensive."
And from the FSF membership page:You will receive a personalized, bootable, business-card-sized GNU/Linux distribution as your membership card.
This GNU/Linux distribution is based on LNX-BBC. New cards will be sent to renewing members every year if and only if there is a new major release of LNX-BBC.
So, not only can you give a little something back to a project from which most of us have benefitted from - you'll also get a membership card that's as useful in and of itself as carrying a swiss army knife, and as far as I know, it won't get confiscated from you at the airport.
(Oh, and this entry is a test of the NetNewsWire Pro Beta weblog editor. This is only a test.)
[ ... 178 words ... ]
This week, at work, I cobbled together a hack for MovableType that hooks it up with an LDAP server for author accounts: MovableTypeLDAPAuthors. This is an early, early, early release of the thing, and is likely to do very nasty things for all that I know. But, I wanted to share, and it seems to be working for the proof of concept at work (that is, MT weblogs on our intranet for every employee). Hopefully soon it'll be approved, and I'll be looking into a commercial use license for MovableType.
You know, for all the praise I've read about MovableType, something I've really not seen much attention toward is the code itself. I mean, yeah this thing is great, and it's so simple to install and use by even non-techies. But, under the hood, there're some nice things going on - like a very decent object persistence approach; templating for pretty strict code/presentation separation; a workable servlet-like app structure with facilities for localization and a dispatch-table approach to executing web app methods. There are some spots that are a bit too if/else-ful for my taste, like the CMS' edit_object() method, but hey, it works.
In other words, MovableType isn't just a cobbled together tangle of code that happens to produce weblogs. I've seen piles of well-used code on the web before that all seem to do what they advertise, but present a nightmare under the hood. (cough Matt Wright's famous scripts cough) No, MovableType looks like the result of experience, and I feel biased, because it demonstrates a lot of the same perl web app design patterns I've been employing and advocating for years now. So, my LDAP hack was a bit of enjoyable fun, instead of a chore.
Along the lines of what I'd written last week about perfection versus good enough, I think MovableType is a good example. It's something I could have written, but didn't write and didn't release and didn't support and didn't make lots of people happy along the way. All the did-nots are the important bit. It's why I have two projects dead (Iaijutsu and Iaido) after a few years' effort, and MovableType is a gigantic success today.
So, these are the kind of lessons that are an important part of what this weblog is about for me.
[ ... 608 words ... ]
In case anyone's been wondering, I've not slipped back into oblivion. I've been a little busier at work again, but nowhere near a death march pace. And, in the free time I've been clearing up for tinkering, I've been working semi-obsessively on the aforementioned PersonalWebProxy idea. I dove back into Python, started soaking in the Twisted framework, and just about have an operable-but-ugly first attempt at a basic HTTP proxy with plug-in filters.
Thinking that I need to knock it around some more to work out some kinks, and then bang up some initial useful filters. But I want to get something packaged up and offered for ridicule within the next week or so. Not sure if anyone else is or will be as enthusiastic about this little toy as I am, but I think I'll be able to do some nifty things with it.
[ ... 181 words ... ]
Today's revelation while tinkering with my PersonalWebProxy: Decompressed content is larger than compressed content.
See, I was decompressing gzipped content streams in the proxy in order to fiddle with the content before it got to the browser, but then I noticed that browsers kept only displaying part of the content. I remove the in-proxy decompression, things are fine. Put it back in, things get cut short. I poke for a few hours at various bits and parts, to no avail.
Then, finally I remember... "Hey, you know, I think browsers pay attention to that Content-Length header. And hey, you know... decompressed content is larger than compressed content." Bingo. Problem solved by keeping the Content-Length header updated with the length of modified content. This makes me feel very dumb, because it's not like I haven't written a handful or two both of HTTP clients and servers. And I've written code that uses the Content-Length header, over and over again. I'd've thought this would be something I'd remember more quickly.
More often than I'd like to admit, remembering simple and obvious things like the above are what unlock problems that I'd been banging my head against. The last revelation of this nature I had while frustrated at a project at work was: "Not all months are 31 days." And before that, "Not all days in a year are 24 hours long, due daylight savings time."
Trying to think of more, but I thought I'd share. Maybe I'll start a wiki topic for sage bits of the ObviousInHindsight.
[ ... 430 words ... ]
Okay... This really is the LazyWeb. I barely mention writing some sort of RDF-based Tinderbox-a-like, and I see a link to Ideagraph on the #rdfig scratchpad .
[ ... 98 words ... ]
Is it just me, or is it pretty damn ironic that Mac OS X: The Complete Reference is available in Acrobat eBook Reader format, yet the Acrobat eBook Reader is not available for MacOSX?
Yes, I'm bitter. And stupid. While I didn't buy the MacOSX reference, I did buy a book in eBook Reader format. Dumb, dumb, dumb. Can't read it now. Bastards. And no returns on eBooks. Crooks! Mental note: Next time remember to buy books whose only compatibilty requirements are sight and literacy. Unless I decide to learn braille or go for audio books, that is.
[ ... 142 words ... ]
I hadn't had a bon mot for it until yesterday, but I've been thinking about the concept of recombinant growth for awhile now and how it intersects with the LazyWeb / blogosphere.
In particular, I've been thinking about design. I'm of two minds. As a perfectionist, I want sparkling gorgeous gems of elegance. It feels so good to be playing with something polished that so obviously has been imbued with immense thought. But, as a realist and a guy trying to make a living, I also appreciate adhoc rusty tools that still turn a screw. The thing might fall down in some cases, but otherwise it's a pretty steady companion.
Looking at it another way, though, many of those otherwise sparkling gems won't let me use them as a hammer the same way I misuse the screwdriver on occasion. And oftimes, they don't have any control panels to open so I can reroute EPS conduits and exploit leaky abstractions. And then, there's the problem domain: on what classes of nails is this hammer indented for use? In one case, a particular hammer shines, in another, it leaves thumbs throbbing.
I see infernos of flamewars start over principle, predictions of falling skies and doom doom doom. (It's not maintainable! It won't scale! It'll be the end of the web!) And then I see mischievous wizards and cantankerous veterans pull out a much-abused old standby and knock it out of the park. (Only the feeble-minded need strong types! Goto considered harmful - to you, maybe!) And then, sometimes, when you're in the realm of recombinant growth and the lazyweb, what initially looks like a jumble of wrinkled paper takes one more origami fold and turns into a perfectly formed swan. It gets confusing sometimes.
So anyway, this all leads up to my questions as a naive, wannabe computer scientist: By what processes of design do we best facilitate recombinant growth? How deeply and to what level of detail? How dirty should it be, how unspecified or left with holes or shrugs? (Plants need dirt to grow.) How meticulously clean should it be? (We don't want to attract any bugs.) How much should be chalked up to bootstrapping, and how much should be wrangled and hogtied into perfect working order?
I doubt that it there's a single fully valid answer to all this. But, I'm always interested in any of the answers I find anyway.
[ ... 403 words ... ]
Another little train of thought, whose conclusion will probably be obvious to anyone:
I wonder how hard it would be for me to make a little personal idea processor like Eastgate Tinderbox using RDF? Very likely much harder than it was for its author to create the original - I'm by no means smarter than Mark Bernstein, and he's got years on me in developing tools like Tinderbox. So why would I even consider rolling my own in this case? Certainly not the price - for a tool like that, the price is a steal.
No, I think it's because I don't have full access to hack the thing, and it has a few itchy spots for me. At least, that's the way it looked when I last tried a demo on MacOSX. I wish I could fix them, and rolling my own is the best way I know for that. And besides, I'm in a real RDF love fest lately.
But... Is it really so bad as it is? Bad enough to try to play catch up with what someone else has already devoted so much to? Nope. Bad idea. Best to promote recombinant growth, and rephrase the question: I wonder how long it would take me to get used to the tool's quirks as I percieve them, make suggestions to the author, and then use the extraordinary hackability already present in the tool to get it soaking in RDF?
This is a lesson that's taken me awhile to resign to learn, so I figured this would be a good exercise to document it. And to think, I once spent a year or two trying to re-implement Zope, by myself, mostly in quiet, and with not much to show in the end.
[ ... 443 words ... ]
Mental note: Look into Jical, Java iCal Group Scheduler, as part of an Exchange replacement when the current server comes tumbling down when they try to upgrade it. Yeah, I know, it'll most likely be just fine. But I can dream.
[ ... 42 words ... ]
So I'm singing the RDF praises at work today. I've gone through creating a very small proof-of-concept task tracking vocabulary in RDF. Initially, it covers things such as clients, projects, tasks, workers, time card entries. So far, I just have a vocabulary in RDFS and a sample load of data - both built by hand - but thanks to the BrownSauce RDF browser, I've been able to show off some nifty things. I know I've linked to that project two days in a row now, but I think it was seeing things through that browser that finally turned the last tumbler in my mental lock on RDF.
As a demo to co-workers, just clicking through the linked resources, I can show who's managing what projects, who's been assigned what tasks, what a given person has worked on, etc. And I just keep drilling through links showing one view of relations after another. It's fun. Someone said it looks like how they breeze through data on fake computers in TV shows.
Eventually what we want to do, if this proves to be useful, is expand this thing from just task tracking to slurp down more and more knowledge from around the organization and form a semantic intranet. And, I think it can do it. I just started getting Jena stashing statements into a MySQL database, so my next steps are to start actually working up an application around the data.
So far so good. I hope I'm not insane to be thinking this is easy. Waiting for the enthusiasm to calm down so I can realistically take account of what warts are to be found in the current state of RDF art.
[ ... 380 words ... ]
Along with tweaking my RSS template today, I've been tweaking my FOAF file after perusing the FOAF vocabulary again and having spied on the FOAF files belonging to some of the bloggers in my neighborhood.
Trying not to fall prey to simple cut-and-paste copying, and trying to keep in mind the underlying RDF model as I push things around. I've been browsing things with BrownSauce, but I have to keep reminding myself not to fall for the "looks okay in the browser, must be okay" fallacies that plague the entire HTML universe. Just because it seems to render in ?BrownSauce doesn't mean it's okay, and just because it might not look okay doesn't mean that it isn't.
Must learn the model and the vocabulary. Repeat this 100 times.
Whew. Anyway, the more that I look at it, the more that I'm thinking that FOAF is the perfect LiveJournalFriendsReplacement format. I can't believe I hadn't seen this before and gone completely gonzo over FOAF already.
I think I'm grasping RDF and the FOAF vocabulary, so I don't think it would be a herculean task to build something similar to the user info editing pages over at LiveJournal, and to build a FOAF display page like my user info page on LiveJournal. Perfect.
In fact, I wonder if I might not be able to work out a conversion between the two, maybe create a supplemental vocabulary to supply details that LiveJournal does yet FOAF doesn't. (ie. bio, IM accounts, birthday, blogrolls, etc.)
More study to come...
[ ... 335 words ... ]
Still working on my RdfNotes and learning RDF. I hadn't realized it, but my RSS feed was still being produced from a vaguely constructed v0.91 template, so I decided to update it to a v1.0 template for MovableType I found via Bill Kearney. I also got a little brave with the RDF and decided to start tweaking, stealing a few extra metadata elements from Eric Vitiello Jr.'s RSS feed such as a pointer to my FOAF file.
If I'm lucky, everything validates and I can start poking at my own metadata with RDF tools.
Update: Yay, according to the RSS Validator, my RSS template passes:
[ ... 106 words ... ]
Well, it's not earth shattering, but after some research and some more feature brainstorming, I've gotten a start on a PersonalWebProxy. At the moment, it's not much code and is transparent except for the fact that it transforms every appearance of "0xDECAFBAD" on pages into "0x31337D00D". What's exciting to me though, is that I tossed it together with an hour's hacking in Python, using the Twisted framework. So, starting work in a language and framework both mostly new to me is fun. Also, it's interesting to work in the event-driven style again, even though I still think I still want threads (see: Blog:000090). If I go to threads, I think I'd swap over to Java.
I was tempted to start the thing in Perl, since I already know my way around the language, and I already know my way around POE, a major event-driven framework in that scene. But, I've been programming in perl almost to the exclusion of other languages for a little over 10 years now, not counting some excursions into Java or assignments for college classes. I think it's time to expand, and force my brane wider. I've touched on this topic before, but it's been ages since I had any energy to devote to this place and its projects.
At least I didn't go completely apeshit and start this in Lisp or ?Scheme. :) Though I'd still like to make myself an assignment using one of those two, I'd like a few collaborators on this project at some point. I figure Python would be more hackable for this at present.
[ ... 265 words ... ]
Speaking of BlogWalking and ?MoBlogging, I just noticed via following a referring link that Matt Croydon has thrown together and released a proof-of-concept WAP-based blog client app. Swanky. Check it out.
I want to do the same thing, but using kinder-gentler-HTML templates for my Treo. My previous phone, a Touchpoint, supported WAP and thus WAP interested me for a year or so and I have a few private hacks laying around (ie. controlling X10-enabled house lights from my phone, trying to set up recording times on my half-working Linux PVR). But, being a fickle geek, WAP no longer interests me since my current phone supports richer things.
[ ... 108 words ... ]
Okay, now that I'm healthy, my girlfriend is healthy, my job is healthy, and my iBook is back to being healthy - I might just get a chance to sneak some time in for my Projects again.
At the moment, I'm considering building a PersonalWebProxy. I've been playing with them and thinking about them off and on for years now. You can see a short list of them that I've poked at in the PersonalWebProxy wiki topic - you're welcome to add to the list if you know of more. In particular, the WBI project at IBM got me initially hooked on things. I really thought it was nifty how they edited HTML on the fly to weave in the WBI UI and add indicators on links in the page. And the idea of storing a history of one's web browsing in a local cache, available for review and later search, has always seemed incredibly attractive.
Lately, I've been thinking of a few more things that might be useful in a personal web proxy:
Marking pages to be periodically checked for change notification.
A browsing "shopping cart", in which to collect pages now for later browsing.
Auto-harvest RSS, FOAF, and whatever other associated page metadata that might be useful now or later. Maybe suggest subscribing to the site after a few visits.
Use a ubiquitous rating mechanism, machine learning, and maybe some off-peak spidering to have new content of interest suggested.
Publish and share browsing patterns, generate "Friends who viewed this page today also viewed this today..."
Generate RSS feeds for all notification features
And then, of course, there are things that I've seen already in other projects:
* Rich browsing history
Collaborative annotation
Ad filtering & pop-up blocking
Content summarization
I'm thinking it would be nice to put together something like WBI and its modular API, maybe in Python, and make this thing super friendly to quick hacking. Could be some fun. What do you think?
[ ... 881 words ... ]
So, I finally got my iBook into and out of the shop, and I'm back on the reinstallation road to recovery. Not only that, but I got a little bit extra - seems that since my model of iBook is no longer available, the repair tech found that he was required to replace my dying 9GB hard drive with a quieter 15GB drive. Not a gigantic improvement, but it ends up being just enough to be nifty and was free to boot. Also, I splurged a little bit before starting Christmas shopping, and replaced the 256MB of RAM with a 512MB module. The improvement from 384MB to 640MB under MacOSX was much more marked than I'd anticipated. I don't know what kept me so long.
So, my desires for a new iBook or a glitzy ?TiBook are dampened for now, and my pocket book thanks me. And, if/when I decide to toss this thing up onto eBay, the extras couldn't hurt the value. Also, I imagine that my expectations of OS X will have set me up for amazement once I get to play with a machine that supports Quartz Extreme and has a more decent processor speed.
[ ... 199 words ... ]
Tonight, I was perplexed about a comment claiming to be from DaveWiner - though it could just as easily be from an impostor - on the final installment of my extended XmlRpc ramblings:Pretty arrogant if you ask me. What has LM Orchard contributed to the world? Add more value, less bluster and bullshit.
I suppose I should have stopped while I was ahead, refraining from rambling on about my case study to begin with, let alone responding to this comment. But, nonetheless I was bothered tonight, and responded:Your comment confuses me.
I've written that your work has helped me and given me food for thought - despite other disagreements I may have with you. And I've written that a tool of yours I've come to consider imperfect has, nonetheless, worked perfectly for me. These things remind me that I don't know it all and have much to learn and hash out. If this is bluster and bullshit, I certainly didn't intend it as such.
As for my contributions and value - I'd like to think I'm doing something right in this field, given that I still have a well-paying job and a non-zero readership of my weblog.
I was trying to give a compliment and a positive testimonial, while addressing some of the standard criticisms I'd seen before. And I wanted to back it up with my own experiences while tempering it with my admitted inexperience.
But, after having had a decent dinner and a measure of time watching soap operas with my girlfriend on the couch, I've decided that this is what tweaks me about the comment: What's a weblog for, if it doesn't make room for arrogant bluster and bullshit? My assumption in writing here is that I know enough or can figure enough out to write things valuable to someone - or at least, if I'm wrong, I can still provide myself as a foil of ignorance to someone else's enlightenment.
Attacking the process, or the village idiot himself, is not constructive.
Hope that helps. Have a nice day. Please drive through.
[ ... 784 words ... ]
About the difference between BlogWalking and Moblogging, Bryce writes:Moblogging is about capturing the moment with multimedia.
Moblogs exist in a seperate space from traditional weblogs, and that's where the disconnect with Blogwalking occurs.
Blogwalking is about taking our weblogs with us.
Originally, we'd written about BlogWalking as literally walking with your blog, publishing & management software and all installed on a mobile device. The spirit of it, in my mind, was mobile blogging.
Then, I read about Moblogging and assume it's the same thing. But, Bryce points out an important distinction that I think I get now. BlogWalking is coming from one direction, trying to make the blog mobile. Moblogging comes from the other direction, trying to make the mobile blogged.
I'd off-handedly wondered what it would be like as a BlogWalker, if I could add a camera, GPS device, temperature sensor, and other various things to a PDA loaded with blog software - I already have the blog, but I want to add multimedia to it. Well, Mobloggers already have multimedia devices, with voice and imaging and more to come - they want to capture that content in a blog.
It's a subtle difference, but somewhat important, I think. And after experiences with my Treo, an admittedly underpowered device versus the Zaurus, I'm leaning toward Moblogging. Keep the blog software off the mobile device, but make the mobile device into a multimedia blogging terminal. I think Moblogging is really the spirit of what I want from BlogWalking.
I'm hoping for a color HipTop after my Sprint PCS contract is up. The Treo has been nice to me, but it hasn't amazed me. Although the grass is always greener, the HipTop seem the more amazing device to me.
[ ... 425 words ... ]
Sheesh, have I rambled on forever about this or what? I think it could have all been summed up so much more concisely, as Paul Prescod did for me: "For the 20% that XML-RPC solves, by all means use it!" With my case in particular, his 20% is 80% of my problem domain.
I guess the vehemence and volume of my reaction, which surprises me now looking back, stems from three things:
First, I've gotten used to seeing statements along the lines of "XmlRpc and its ilk are complete and utter useless shite, will be the end of the web as we know it, and what kind of brane damage have you suffered to continue using it?" So, I fully expected to be smacked around for even vaguely hinting that I'd found, in my experience, that XmlRpc is extremely useful. But, to the contrary, I got a very nice and thoughtful response from Paul Prescod and the flames never rose.
Second, on the level where my purist perfectionist self sits, I've bought into the "XmlRpc is shite" meme. So the fact that I do useful work with it from day to day introduces a bit of cognitive dissonance for me - how can it be complete shite if it's a money maker for me? I've got to justify this to myself somehow. Granted, there are warts in XmlRpc - but warts by what measure? A measure of ideal perfection, or a measure of real world experience? Well, what Paul gets across to me is that it's the latter, but my experience thus far is very much a small subset of the experiences of people who feel they need to go beyond XmlRpc. My experience with my problems is valid, and XmlRpc is useful. It's just that there's a larger domain for which XmlRpc falls down.
This, I think is the key: XmlRpc is not complete shite. It works just great for the right problems, which happen to be mine. The question to which I don't have an answer is this: How many developers' problems fall into my kind of domain?
Third and lastly, though I didn't get any flames for XmlRpc advocacy itself, I got a few private nastygrams flaming me for talking nice about DaveWiner's work after I'd talked not so nice about him some months ago. With regard to that, I have to say that I'm not on any particular crusade, other than for that which I find interesting. That said, I dislike many things Dave does and says. Though I'd rather not add fuel to fires, I might fail to resist on occasion - as noted above. However, I'm not the guy who's going to change his ways, he obviously doesn't feel a need to change, and I frequently don't have all the facts anyway. But I do like some of the guy's contributions to the world, so when occasion arises (as it did with XmlRpc), I'll say so. In any case, DaveWiner has given me much food for thought.
[ ... 642 words ... ]
This really confuses me. Seems that I've gotten 2 pieces of comment spam on one of my more visible blog entries (due to controversy) from back in September, More on the Monster Mash. The first one expresses confusion, then links to something about zip codes, and links again to something about business plans. The second one is apparently a strange flame at DaveWiner, then links to something about vehicle history reports.
I'll likely delete these in a lil while, but it really confuses me. Do things like this really bring in financial results to the spammers? Random links in nonsensical comments and inappropriate flames? Do they really have some metrics on this, before & after spam revenue results? This, and other spam, is really seeming like superstition in pigeons, where various kinds of spam are tried and maybe money is made so more kinds of spam are tried until the oddest forms appear.
I really do hope that, some day, the full fury of hell and recipients of spam scorned rain down on the heads of all those slimy bastards.
[ ... 801 words ... ]
You know you're an info freako and coding junkie when: Your trusty iBook - home to all of your projects in development, news aggregators, and blogging tools - goes into the shop for repairs, and all you're left with is a Treo 300 for convienient from-the-couch computing over the long Thanksgiving weekend. Most people would settle into a good book or maybe a James Bond marathon.
Instead, being thankful for unlimited data access and at least having a screen at which to stare (albeit tiny), you install LispMe and a handful of editors and tutorials in a sudden, inspired effort to a) learn a new language (Scheme) and b) write a news aggregator and blogging tool for PalmOS as your first project. I mean, hey, LispMe has access to net sockets on PalmOS - XmlRpc and REST, here we come!
Then, you go have Thanksgiving dinner, doze on your mother's couch in a food coma, dream about hordes of attacking parentheses (too much Scheme and NetHack), and all but forget about the whole thing. Watching the James Bond marathon isn't so bad after all.
[ ... 185 words ... ]
Noticed http://example.com linked to via the #rdfig weblog, and had this thought: Thank goodness that someone had thought to register that domain, or else my boss would have more likely than not been viewing porn after clicking on a link it in our last meeting.
[ ... 169 words ... ]
So, while I was catching up on T Bryce Yehl's blog since missing his transition to MovableType, I caught an interesting blurb he wrote with regards to Phil Ringnalda's ponderings on FriedPages and BakedPages in weblogs:"Funky caching" could be useful for a static publishing system as well. Weblog archives can consume a great deal of space, yet those pages are infrequently requested. Why not GZip entries from previous months and use a 404 handler to extract pages as-needed?
The funky caching to which he refers involves implementing a 404 (page not found) handler that, instead of just supplying condolences for a missing page, actually digs the page up out of cold storage if it can. I think I need to look into this for my site - throw all the old blog entries away into gzipped files, or maybe a tarball per month, and have a funky 404 handler dig them out when needed.
There are issues with this - such as what happens if I want to edit old content, or I change templates, or what not - but I think there could be decent solutions for those. Hell, maybe this is an easier way to blog locally and publish globally - don't rsync directories of files, just publish locally and upload a new tarball. Then, on the remote site, delete the index, RSS files, and other affected files and watch happy updates ensue. If a massive site change is made, rebuild locally, re-tarball every thing, upload the new tarballs, and delete all remote content to trigger revivification. Scary but possibly nifty.
[ ... 1031 words ... ]
So... I want to learn and tinker with C# and .NET, but I don't have and don't want to build any Windows machines. I have some headless Linux machines, but my main daily environment is Mac OS X. So now I see that The Shared Source CLI 1.0 Release compiles for OS 10.2, and I see that the DotGNU project has some news of a 100% free software release of Portable.Net. What about Mono? Any OS X news?
Or are things still basically in the "You can compile & run Hello World, barely, but don't expect access to any of the standard framework classes or GUI building" stage? Or are they in an even less developed stage that would make my non-compiler-building branes melt out my ears?
[ ... 172 words ... ]
With Syndication is not Publication, Mark Pilgrim elucidates in eloquence what I'd vaguely poked at in silliness. No, I agree with mark - syndication cannot replace publication, and publication cannot replace syndication.
Though, I think it's interesting to watch the thought experiments and the "what ifs" as Anil commented - and while I sense some eloquence in both approaches, neither answers all the demands placed on each. Hopefully, what dabbling in overloading one could provide is a little insight into enhancinging the other. In the end, as Dave commented and Mark demonstrated, there will be no fight - tinkerers will route around the solution they don't like.
[ ... 108 words ... ]
So, from my last installment, I left off with this: My daily situation with regards to integrating the web-based services of various parties boils down to what I can explain in 30 minutes to a developer of unknown competence to whom I'm barely a priority. So far, I've been able to apply XmlRpc as a solution to this problem with a great degree of success.
About this, endulging me although I'm sure issues like mine have been hashed out a million times already on various mailing lists, Paul Prescod writes:There's nothing wrong with the way you've used XML-RPC and I've used it that way myself. I only write to ensure that you (and anyone reading) understands the costs and benefits of this approach. You've given up on many of the feature of the underlying XML and HTTP technologies. If you don't need the features, then amen, let her rip. But people building more substantial apps do need them.
Yes. So, I know that my chosen solution has its blemishes and land mines awaiting my step. But, none of them have bitten me yet, nor do I expect them to for some time. On the contrary, for every practical application of XmlRpc we've deployed, we've had happy clients. While working in this industry, the 80/20 rule has been beaten into me - so if a solution that's 20% complete solves 80% of our problems, it's time to move onto the next problem.
This, however, is a dangerous thing to become complacent about - there're still 20% worth of problems out there for which this solution falls down. And each one will become a work-till-3-am nightmare when they hit. And besides, I'm a perfectionist and a purist at heart, so the dirtiness of this solution will never fail to irk me. It may be simple, but simple is not necessarily elegant. So what about the rest of Paul's points?
The first axis of flexibility you've given up is in character set. XML-RPC disallows Unicode character strings.
On one hand, my impulse is to respond to this by invoking YAGNI - since our use of XmlRpc involves messages between machines, I don't care about localizing those. I'll just keep to language neutral data in there. But, I'm naive. With a bit of pondering, I can identify at least one area where user-supplied input needs to be traded - shared registration and login for global promotions. And if I can identify one, there's bound to be more. I don't have as much experience with Unicode and handling languages other than English as I'd like, so I can't trust my assumptions here.
XML-RPC is brutally non-extensible. ... Dave Winer has been actively hostile to every effort to evolve XML-RPC.
In this case, I'd say this is a good thing, for XmlRpc in particular. It does what it does, no more and no less, and this will never change. I will never need to bring up versions of the spec in my 1/2 hour conversation with the junior engineer. And though I don't want to second guess Dave Winer, I assume this is the goal in his insistence on XmlRpc being ever frozen. The alternative at which he points, if memory serves, is SOAP.
The third aspect: XML itself. What will happen when and if your industry, whatever it is, canonizes a schema for what you do, like the hundreds of existing ones. ... Maybe your industry isn't organized enough to define a schema for whatever it is you do.
Bingo. Our industry is neither mature nor organized enough to conceive of any sort of schema. Our products and the concepts involved in our work are in constant change, not to mention the conditions of the market and what will continue to work.
Another way of attacking your interoperability problem would be to start from that point of view, defining the XML and then working back to the REST system. That's a much more natural way to define a REST-based web service and is arguably a better way to define web services in general. I would be curious whether you tried this.
Nope, haven't tried this. This is where I start calling things "ivory tower". To me, it makes elegant sense.
You say you tried "REST-ish URL schemes" but that isn't the same as trying REST. In particular, you don't say much about what your XML strategy was.
Calling our early interop schemes "REST-ish" may have been too strong an association with REST. No XML strategy. More like: "Make a GET to this URL with these query parameters, documented here. You'll get a simple text response back, documented here." This was always balked at, though I thought it was the simplest thing in the world. I might have some thoughts on the failure of this, if I think about it some more.
I don't know your suppliers, but in the vast majority of situations I have been exposed to, they "get it" if you tell them: "here are some XML example documents. POST things like that to me when you want me to do something and GET them from me when you want to get information from me."
Whenever XML is brought up, fear rises and eyes glaze. We're the "supplier" in most situations, and it's rare that our clients are tech-centered companies. They have a web site, and maybe a team maintaining it if we're lucky.
You depicted the situation as SOAP on one side (grungy), REST on the other (ivory tower) and XML-RPC in the middle. REST is basically the same old CGI-ish stuff we've been doing for a decade so I don't see how it is very ivory towerish.
Well, I'm mixing audiences here. SOAP, to me and my lack of time with it, seems grungy and in flux. To my clients, REST seems out there, especially if I ever try to explain to them what the letters stand for. :)
"What's a siggy?"
"You mean a C-G-I?"
In explaining XmlRpc, I usually say something long the lines of "your people's boxes talk to my people's boxes," then point them at the website that says largely the same thing. Of course, this begs the question of my effort and competence in explaining REST to others, which I feel is lacking thus far. Because, well, REST is also their boxes talking to my boxes. And, I haven't found a website at which to point both techie and non-techie audiences to "get it".
...perhaps REST doesn't apply to you. Yet. ... You say that REST doesn't "feel finished" to you. Nor to me. Our industry is in the middle of a huge migration to extensible formats like RSS which builds on RDF which builds on XML.
I don't think REST quite applies to us yet. I'd like it to. Maybe once we, as a company, have formed much stronger partnerships I can get past the 30 minute barrier and get to some real discussions and establish things like XML schema.
When people are comfortable with extensible, hyperlinked formats, REST will seem like a no-brainer.
The more I read and think about REST, the more I agree with this. It's just that I find it very hard to sell the idea yet. Again, this may be the nature of the beast for whom I work, and it may be my lack of ability to describe this simply.
But for now, it seems that the ability to throw a random unknown web developer an API and a URL with less than 30 minutes' accompanying discussion, and get results, seems to work for us.
[ ... 1478 words ... ]
So, my little off the cuff case study with XmlRpc from yesterday got a ton of flow from Dave. Got some comments and some email, and a very good response / rebuttal from Paul Prescod. Thanks to everyone for reading & responding!
I think a few things from that case study, the response to it, and Paul's comments need some more consideration. And, I think some more clarification of my situation would work as well. So I'll start with that:
The first thing is that I think the quote Dave pulled from my case study nails my situation: "I get it, my boss gets it, his boss gets it, the sales guys get it, and the marketing guy who's always our first contact at a client gets it."
I work at a promotions company. Because we act as a sort of application service provider and host everything ourselves, we can do and have done some pretty nifty things within our walls.
On our clients' side, though, they're hiring us to do nifty things that don't require them to do much at all. In fact, the vast majority of the time, our direct client contact is a marketing/PR person who has little, if any, access to technical resources. It's a major undertaking for this person to get an image tag or a javascript pop-up window slipped into an HTML page somewhere on the company website - anything further than that leads down a trail of tears and a week's worth of conference calls with grumpy people. We've spent more than 4 years streamlining everything down to the acceptance of this fact.
So then, in walks the client who wants a lot more, like the aforementioned client for whom XmlRpc worked swimmingly for integration between their site, their commerce vendor, and us. Our direct contact is still a marketing person, but she has a bit more technical support behind her. She might be able to get up to 4 hours' time from a junior engineer over there to whip up a CGI or JSP, assuming that the team in charge of the website approves permission to do so.
As part of that junior engineer's time, I have one half-hour conference call to explain our points of integration, how everything's going to work, and where to go for resources on how to do it. I barrage the person with email, offer availability on at least 3 different instant messaging networks, but when it comes down to it this 1/2 hour phone call is all anyone remembers. We've been working on improving this situation, but the only traction comes from where we've been able to gain the confidence of a client as a long term strategy partner. Otherwise, we're just some random vendor who gets tossed away if we make too much noise.
What this all boils down to is that I've needed to develop a scheme of integration between web apps that can be explained mainly in 30 minutes to a developer of unknown competence to whom I'm barely a priority. This is my situation at present. The situation has room for improvement - but the power to make those improvements are largely beyond my influence - so I've applied XmlRpc successfully so far as a solution.
So, I'll post this, and in the next installment (if you're still with me), I'll voice my concerns with the solution I've chosen, and consider what Paul's written. As always, I encourage you to tell me where I'm full of it, and why.
[ ... 588 words ... ]
About SOAP vs REST vs XML-RPC, Dave writes:By and large REST interfaces don't tell you how to serialize and deserialize complex structures, so you kind of start from scratch every time. If they use a SOAP encoding, you get some of that. But there just is nothing simpler than saying "Here's the XML-RPC interface, and some sample code in a few of the popular scripting languages." If you want developers to get going quickly, avoid the religious wars, just support XML-RPC. Now even this isn't bluster-free. Think of it as evangelism. Have a nice day.
Though I don't like his remarks on REST, I gotta give Dave an amen here and thank him for having XmlRpc out there for me to stumble upon. REST seems shiny and neat to me but incomplete - I'm pulling for it because it seems warm and fuzzy to my ivory tower branes. SOAP seems to try to be nice & clean, but feels grungy and toxic to me and I've always felt a vague sense of unease when walking past its house on the block. In the middle, XmlRpc seems to be the right balance of dirt and acidity to grow things in.
About XmlRpc, I can speak with some experience now. I first started tinkering with it a few months shy of a year ago, when I first launched this blog. I went to http://www.xmlrpc.com and learned it in less than an afternoon. Cobbled together a few Projects with it, and saw an opportunity to introduce XmlRpc as a new tech at work.
(In case you don't know about my job, I'm the guy who does most of the research & development, tool building, and overall platform architecture at a promotions company called ePrize. I grumble about the place from time to time, but on the whole they let me do an amazing amount of wandering around in finding new things.)
Anyway, we'd been poking around with a few different means of integrating our promotions into clients' websites. You see, we host the web part of all promotions on our servers, and work toward making inclusion of those promotions not much harder than slipping in a banner. But sometimes, there's just no avoiding more complex integration. And sometimes, it's exactly what you want with things like shared sign-up & login, awarding tokens & coupons, and coordinating between vendors' services. So, we had a few different REST-esque URL-based schemes, some FTP-and-PGP-based things, and even managed to convince one client to use a one-off protocol between two perl net daemons. Every time, it was something new, and we could seem to get no two clients happy with the same integration scheme.
Then one day I bring XmlRpc into the office, and weave it into our app platform at the ground floor. Overnight, just about every aspect of every promotion we do can be accessed via XmlRpc, given the proper switches thrown and the right access controls set. Producing an XmlRpc API spec for potential clients took mostly a bit of cut & paste massaging of our internal API docs.
(Your mileage may vary greatly, but our homegrown platform seemed pre-designed to fit with XmlRpc. This point right here may be what makes this anecdote fall on its face for you and your experiences. But, based on the success we have with it on the client end of things, I suspect that we're not that much an outlier.)
The next day, we had a meeting with a giant customer whose name I'm not sure I can mention, but suffice it to say you've heard of them and It's very, very likely that you've used their gadgets. We helped them put together a customer referral and rewards program, using XmlRpc as the glue between an online store vendor, the client's site, and us. It was a great success, and since then we've done another dozen or so cool promotions involving XmlRpc.
What makes this tech so successful here is that it's so simple and decently understood. I get it, my boss gets it, his boss gets it, the sales guys get it, and the marketing guy who's always our first contact at a client gets it. And when we finally drill down to a tech guy on the client's side, we just tell him, "Here's the API for your promotion, and visit http://www.xmlrpc.com for details on how to call it." And that's it - 75% of the time they get it and implement it. The rest of the time, we have to spend some time proving the tech and answering doubts, but it's always a pleasant experience from our end having all the answers.
I'll adore REST if/when it gets to this point in helping me get mine and my client counterparts' jobs done.
Anyway, this is sounding like a bad infomercial and I need to get back to work. But I had to toss out this bit of anecdotal dross in favor of XmlRpc.
[ ... 1403 words ... ]
In Formats for Blog Browsers, Dave writes:I wanted to add a facility that would automatically back up all your weblog posts... "I bet RSS 2.0 could do this," I said out loud. And now that the code works, the answer is clear. It can. ... Then another lightning bolt hit me. ... What if someone made a browser that worked with this format? Let's call them Blog Browsers, apps specially designed for reading weblogs.
About syndication formats, Anil Dash writes:I have a radical proposal for a ubiqitous content syndication format, applicable for almost any purpose, but extremely well suited for weblogs. ... My new syndication format is called XHTML.
In one corner, we have the syndication format taking over the document format. In the other corner, we have the document format taking over the syndication format! FIGHT!
Yeah, yeah, it's not quite that simple - but the opposed directions are interesting.
[ ... 413 words ... ]
About the "RDF tax" in RSS, Jon Hanna says:Ah, but you're missing the key point that a framework for making statements about web resources is of no use to a format that makes statements about web resources. It was obviously forced. :)
Heh, heh. Full point, RDF team. Now I go back to studying.
[ ... 54 words ... ]
Justin Hall of TheFeature, in From Weblog to Moblog, writes:Weblogs reflect our lives at our desks, on our computers, referencing mostly other flat pages, links between blocks of text. But mobile blogs should be far richer, fueled by multimedia, more intimate data and far-flung friends. As we chatter and text away, our phones could record and share the parts we choose: a walking, talking, texting, seeing record of our time around town, corrected and augmented by other mobloggers.
Touches on SmartMobs and collaborative journalism. He calls it ?MoBlogging (mobile-blogging), but I'll still call it BlogWalking.
Haven't had a whole lot of success doing any blogging on the go with my Treo yet, but then I haven't tried very hard at all yet due to a lack of copious free time. Have some ideas that should help. Liking the Treo, but after settling into it, I'm kind of wishing I could have gotten a HipTop. I expected the Palm to be mature, but it's just kinda clunky and creaky and elderly. I expect the HipTop to get slicker, and I'd like the bigger keys better - not to mention the lil camera. But, my Sprint contract is up in a little under a year, so around this time next year I'll retire the Treo and survey the landscape again. Hopefully there'll be a dream device out by then.
[ ... 227 words ... ]
Okay, so I'm probably the only one who didn't know this, but I've been wondering why it seems that every website owned by someone within a few degrees of separation from TimBL tend to use URLs of the form:
http://www.example.org/2002/11/nifty-thing
Just one of those things I figured kinda made sense, but was never sure why for. Then, today after a bit of wandering while researching things RDF and SemanticWeb, I found a link from Sean B. Palmer pointing to Hypertext Style: Cool URIs don't change by TimBL himself. Seems the example of this pattern is layed out there by the man himself.
Seems like it would work like a limited sort of concurrent versioning scheme, but it just looked wonky the first time I saw it. I mean - date-based website layout? I'd been raised on the high falutin' directory trees made by very well (overly?) paid Information Architect types. /2000/10/stuff? What about /about-us/corporate/ceo.html?
Of course, this is ignoring the fact that some webservers need not directly tie physical disk layout to URL layout. Or that site architecture is best presented via links in the documents themselves. It's just that plain vanilla Apache uses a 1:1 match between file path and URL path, and that's what most everyone uses.
Hmm.. Might play with it a bit around here.
[ ... 483 words ... ]
Remember that Slashdot story from the weekend - Gillette Buys Half a Billion RFID Tags? Boring, yawn, inventory management, who cares? Well, imagine if those things, along with their readers, got so ludicrously cheap and small that mothers would stick 'em to kids' underwear as they went off to camp, and readers came standard in watches and cell phones. Imagine that, somehow, the range was improved to at least 20 feet - your reader sends out a radio ping (MARCO!) and back comes a list of the contents of the room as every object responds (POLO!). Assume as well that your reader can work out the location of each of these objects.
Ignore the big brother fears for now - everyone will have this stuff, not just the MiBs. Also, ignore my ignorance - many of these enhanced tricks are likely impossible or at least very hard for these little gadgets. For now. Until someone does something clever.
But, imagine! Never lose your keys again! Find the cat! Owners manuals to everything you own - should you ever actually have the impulse to read one - are available with a tag ping and a lookup. Imagine the games SmartMobs will find for this stuff! Handle the tag code on objects in the world with a URI scheme - the Semantic Web reaches out to help create the Semantic World! It's CueCat on super steroids! Facial recognition in your PDA to remember my name? Bah - I've got a RFID business card in my pocket. Consider the combination of this with a WearableComputer, and the world becomes just a bit more active as previously inanimate objects can tell you their stories and stories told about them. High tech animism!
Okay, I'm winding down on this. I know I'm going wonky with this idea, but this is along a theme I've been playing with in my head: My favorite sci-fi stories and meditations on the future involve little clever bits of tech that get tweaked and leveraged in powerful ways few could have guessed at. Maybe this tagging tech I'm hyping won't be it, but it's one of the ideas that tweaked me in VernorVinge's Fast Times at Fairmont High.
Trying to stretch my brane more along these lines - squinting at the knee of the curve of TheSingularity. What else is on the verge of emergence, how much of it is crap and how much of it is the real thing? Will things like this and the WearableComputer and ubiquitous internet actually cause major change, or will it just turn into more chuckles for my grandkids when they ask me what it was like in the 90's and double-naughts, when I was living it up at conventions on the company tab, sipping a stout while getting my whites washed at a whacky laundry/bar in San Francisco?
[ ... 560 words ... ]
Just read E-mail as a System Console. Part I over at Linux Journal. It's something I've been meaning to implement for awhile, using CPAN:Mail::Audit and other tools. Got a bit of a start on things, with a sort of plugin system for adding commands available via email. Maybe I should hit this again.
Personally, it's been a long, long while since I had a dialup-based system - so I don't have to solve their exact problem. But, it would be nice to fire off an email to myself or some other mailbox I own, formulated just so and cryptographically signed by me that would cause some machine behind a firewall to open up an SSH tunnel to a predetermined location somewhere. Among other things.
[ ... 125 words ... ]
Whew, it's been a long stretch of urgency and emergency lately without much time for reflection or writing, let alone any general hackery. Don't want to go through a fully detailed recap - but my girlfriend moved in with me; mostly have survived a near ?DeathMarch project; took care of said girlfriend after surgery; was taken care of by said girlfriend after surgery myself. Managed to squeeze a birthday and dating anniversary celebratory break in there, but - not much time for blog, Doctor Jones.
I really want that to change now. A lot has been going on since I've had to take a step back from large parts of my life, but I think I can step back into things again now. Need to restart the social life, and start poking my head out of the lurker pool on the net. Time to finally regroup, exit the state of urgency and emergency, and get back to moving foward instead of moving in reaction.
[ ... 165 words ... ]
Just fixed the download links on these projects: RssDisplay, ShowReferers, GoogleToRSS. Just took me awhile to circle back around to it, ugh. So if you were ever interested in those projects, please try grabbing them again for ridicule. :)
[ ... 40 words ... ]
I've gotten some interesting comments and emails with regard to yesterday's semi-rant, Bitterness in the halls of Xanadu, that further expose some itches I felt after writing it. Two main things:Ideas are not completely worthless, and I have a certain adoration for sprawling cathedrals of vapor.Sometimes the best implementations from the best ideas go unremarked or unnoticed due to obscurity or a lack of understanding.
My recent and vehement attachment to the meme of ideas are fucking worthless is a reaction to my own time spent working on projects that seem to me, in small ways, to resemble what I've read about Xanadu - in terms of long development arcs and seeing similar (but flawed) systems released before my work is done. This presumes a lot - I've not published anything (besides this weblog), probably influenced less than a handful, and these projects of mine are more than likely nothing in comparison to Nelson's work. They certainly haven't consumed as much of my lifetime as his, by an order of magnitude. But still, it felt like some of the scenery along my road matched his. And I don't want to end up down that road, frustrated or bitter that my visions or work had been misread and appropriated by others. (Again, this presumes I have visions or work worth stealing! :) I can't say that I've demonstrated such, as of yet.)
And then there is the addictive quick fix a hacker like me can get in the blogosphere, with just a brief and clever twist of code one can improve the neighborhood and take in some brief praise. Spend a bit more time working, maybe a few weeks or months, and introduce a slightly more useful or complex contribution - you might receive kudos for some time running. But, work for too long, plan too far, build too high, and the blogosphere likely passes you by - unless you really have a deep grasp on what's going on, and your projects meet the blogophere where it later arrives. So I see the techie bazaar of the blogosphere as a kind of fun cauldron of hackers, throwing in ingredients and taking others out, kind of a hivemind without design evolving toward higher connectivity.
So where's there a place for longer-term design?
Okay... more to think about and write, but for now, I'm leaving for surgery. Plenty of time for babble while recovering. Wish me luck!
[ ... 405 words ... ]
I'm a little late on this, but I just read an BBC interview with Ted Nelson this weekend. I don't know the man, and am familiar with his work in only the most cursory way - I've read a bit about Xanadu, skimmed some articles on its history, but I've yet to download the code finally released a few years ago and see what's what. Having said that, this interview reads like the bitter mutterings of a guy who wants to slug TimBL and the rest of us web hackers for making him all but obsolete.
From what I've read, the body of work surrounding Xanadu seems to have a lot to say for itself, though some of that - the assorted collection of almost psychedelic jargon invented to describe its convolutions - seems almost self parodying. The history of Xanadu and Nelson's work with hypertext systems looks to me to be yet another proof that ideas are fucking worthless, and another vote in favor of bazaar- over cathedral-style development.
Maybe it's the fault of the interviewer, but Nelson comes across as a bit self-aggrandizing in trying to puff up how creative and multi-talented and immersed in media - I mean, he made his own rock opera for cripes sake! So I guess this should set the stage for his authority when he dismisses HTML as "a degenerate form of [hypertext] that has been standardised by people who, I think, do not understand the real problems" and the web as "... trivially simple ... massively successful like karaoke - anybody can do it."
But y'know, for all his criticism of systems here and now, and claiming that the people involved with the web don't know what they're doing - he has a surprising lack of working software out in the world. That's what I consider success - working and well used implementation. Who doesn't understand the real problems? One can only build architectures of vapor for so long up in the ivory tower before one must pit it against the world. I don't suppose he's ever tossed around the idea that maybe, just maybe, Xanadu hasn't stormed the world because it's too big and cumbersome and amazingly convoluted for anyone who hasn't worked with it for 30 years to put into use? There is much to be said for the benefits of Karaoke-simple technology.
So yeah, maybe on some Platonic plane of ideal forms, compared to The One True Hypertext, HTML is crap. Okay, maybe right here on my hard drive, HTML is crap. But it's on my hard drive, and I use it. It's been learned from, and attempts are being made to improve upon it. As far as I know, Nelson's ideas of perfection have never seen a pounding from the world of imperfection. That's the crucible in which things are really formed. You get your software in reasonable shape, toss it to the wolves, and see how it fares. Realize that some of your prized pet theories and designs were bullshit, and rework the thing for the next time around.
Okay, that's my rant. Now I'm back to work, and possibly maybe off to check out more things Xanadu and Nelson on my lunch break.
[ ... 1370 words ... ]
So, with regards to things SemanticWeb, I think I'm about to eat dogfood in considering a BlueSky project at work. We've been tossing around ideas for a kind of uber-space or organization-wide brain in which to gather all kinds of details about clients, projects, project details and components, lifecycle, etc.
We want this thing to be as flexible as possible, without filling up a wall with printouts of database tables and relations - in fact, we want the thing to provide ad-hoc relations we hadn't thought of at first. We want people (ie. project managers, sales) and robots (ie. metrics engine) to contribute data, and then people (ie. sales and clients) and robots (ie. automated project build) to be able to query and use this data. We want roles and access control. We want scalable centralization of data items. (ie. Why should the start date of a project be maintained in 12 different places?)
I'm certainly not naive or ignorant enough to think that this is virgin territory. There are entire industries devoted to these issues of business data integration - but here, budgets are very slim yet we love to play with new tech. It continues to astound, but with a little ingenuity (okay - a lot of ingenuity - we have smart people working here), this has led us time and time again to a combination of Open Source software and homegrown code that treats us better than any outside vendor solution. So, I'm hoping to pull another hat trick here and have some fun expanding my brane at the same time.
One of the first notions was to ease more information into our LDAP servers, since it has a very nice hierarchical layout and can accept arbitrary name-value attributes for items. But then the topic of RDF came up, and the discussion really caught on fire as everyone came to understand what RDF is - at least insofar as I understand it, since I seem to have become the local domain expert.
So, first thing is: I hope I really do grok this stuff, at least at a gut mojo level. No one's called me clueless about it yet. But the second thing is: Any practical tool suggestions, case studies, prior art, etc that I should be looking at? I've started with a Google search for RDF and I've been wandering W3C documents - but I need a Busy Developer's Guide. My ultimate hope through all of this, is that even if things are still baking, that there's enough out there with which to make something practical.
The goals are gigantic, but my intuition is that using SemanticWeb tech will let us start out small and simple and then add vocabularies and items as needed without massive tool rebuilding. This is the key thing - the ability to do some initial, fairly easy things that show early results without a heavy, multi-month process to get the thing providing value. My gut tells me it's possible. Am I mad?
[ ... 615 words ... ]
My referrer log harvester and stats were down last week, so I missed out on just how much traffic and flow my Semantic Web ramble had gotten. But, I followed the paths back to a riff on the Semantic Web by mrG of ?TeledyN, perhaps more appropriately predicting The Semantic Mycelia. And I think it's on the mark with what I've been thinking lately.
I've yet to really have time to dunk my head into the Semantic Web barrel for the apples yet, play with the tools, get some results, but I think I get the mojo. And it excites me. But, I've yet to really see any flowers bloom or any heads pop off. I hate to criticize or critique, not having walked the walk yet, but I worry that the present state of things Semantic Web and RDF are walking similar cathedral paths that Xanadu wandered decades ago. I say this in the sense that there seems to be a lot of heavy design up in the clouds, and not enough improvisation down on the ground. And it's the improvisation that kicked the web off to its heights.
On the other hand, it's not like one company has the Semantic Web in a stranglehold. There are groups which, had I the spare time and inclination, I could probably join and pitch in a hand. It seems an open and friendly group, normal birthing struggles and conflicts notwithstanding. So I'd say this thing seems more a bazaar than a cathedral.
But from my occasional stops by the farm, looking over the fence, I see equipment and activity, but no loam or topsoil tilled with things blooming. I don't see the mushrooms popping up in the moist dirt. I see lots of work on the tractors, but I don't see the ground getting into condition for all the little fungi to spontaneously appear. And that's what I see with the web now, and with the blogosphere. The dirt's nice and warm and space aplenty, so things are burbling up all the time. And it feels like I'm getting some neat things done without the need to commit a slab of time to a group or a process other than my own jazz on my own time at the keyboard.
I guess what I'm getting at is that the Semantic Web just doesn't yet seem to me to be sufficiently dirty enough for the grassroots to grow. But I'm still unsure about this assertion. Need to play more.
[ ... 459 words ... ]
Even though I've been in a whiny, self-pitying mood, there is a reason I got into all of this to begin with:
I have to keep this always in mind. And yes, that is authentic - from first grade, I believe. And there's another like that for second, and third, and...
[ ... 196 words ... ]
Mental/public note, things to catch up on soon as the Death March and surgery is cleared:
Fix all the broken links in wiki to download scripts & projects.
Revamp site design to use CSS, accessibility, and less ugliness.
Get back on IRC and in touch with Morbus and the AmphetaDesk clan. (I missed a release!)
Write a CPAN:Net::Blogger based blog post page for AmphetaDesk
Also write a fairly simple yet generalized CGI wrapper for CPAN:Net::Blogger to use with my Treo.
Toy with XmlRpc and PalmDevelopment on my new Treo - some lightweight native Palm clients might be nifty. Poke at ?MetaWeblogApi & others.
Play with the Java MIDP for Palm.
Look into more ?MachineLearning things, maybe apply Bayesian mojo to finding interesting RSS items to highlight.
Relax, recover, catch up on the world, enjoy quiet time with the girl.
Update: Copied things over to LesOrchardToDo
[ ... 154 words ... ]
Hmm, stevenf gives Zoe some love. I want to like Zoe, and I think I might try it again. But ever since I first found and later tried Zoe, I've not had much luck with any release. I think at one point I had a single email appear, but I'm just not getting the mojo. I think I sorta figured out what I'm supposed to do, but mostly it just sits there munching CPU quietly. Hrm. Not that my setup is exotic - I use Mail.app to access an IMAP server on my iBook. I see others manage to work it. Trying again...
Update: It appears that my setup is exotic enough - I'm foolishly using UW IMAP as a quick & dirty install. As-is, it points to the root of my home directory for email, and I set the IMAP folder prefix to mail/ in Mail.app. Well apparently, Zoe doesn't support this and instead tries spidering my entire home directory via IMAP. It appears that there may be hope in a future release, but not for now. I suppose I might switch IMAP servers, since UW has always given me the willies. And, I'm assuming that while I'm using IMAP, Mail.app doesn't have any mbox files for Zoe to auto-import.
[ ... 251 words ... ]
Looks like the Semantic Web hurts Russell Beattie's branes. Hurts mine too. But, I tried explaining what I think I understand in a comment on his blog and I figure it's worth reposting here for ridicule and correction:
Did you happen to catch Tim Berners-Lee on NPR Science Friday today? Not sure if you get the broadcast there, or listen to the stream. He was expounding on the Semantic Web a bit.
Maybe I'll take a shot at explaining, since I think I understand the idea. Likely I'll fail miserably, but here goes.
First simple thing: Look at your weblog page. What would it take to extract the list of people from your blogroll, just given your URL? What about the titles of all the weblog posts on that page?
You, personally, can extract that information very easily since you, as a learned human, grasp the semantics of the page quite quickly. (The semantics are, basically, what's what and what's where and what does it all describe.)
Imagine a document containing exactly all of the same info your weblog page presents - only the data is completely, easily accessible to a robot in a universal, easily handled format.
Furthermore, imagine that the schema describing the data to be found on your page is in that same format. And then, imagine that the document describing the construction of schema is in that same format. And then imagine that the decomposition continues, all of the way down to base data types and relationships. Eventually, the whole thing rests on the back of a turtle - er I mean a sort of universal client.
Now, what if every single page on the web were available in this manner? No scraping, no regex, no tricks. I could use the entire web as database and execute queries that draw from data available on a myriad of disparate URLs. My client can figure out what to do with whatever it finds at a URL by chasing descriptions and meta-descriptions until it reaches the level of understanding implemented in the client.
Going out on a limb here, but imagine a practical example: "Hello computer, find me 2 roundtrip tickets for 7 days anytime in the next 10 weeks, for under US$300 each, to a vacation spot where the weather this time of year is usually warm and sunny, the exchange rate is better than 3 to 1 US dollar, and is rated as better than average by Ann Arbor, MI bloggers."
Assume my semantic web client knows some URLs to airlines, to international weather services, to exchange rates, and to vacation spot reviews in weblogs in Ann Arbor, MI. Assume that there are schema available for the things these URLs describe. Assume that my semantic web client can parse my natural language query.
So, it takes my request, goes out and snags the URLs appropriate to the various topics involved. Once it has all it need to process the data in each URL, it can find me the answer to my query, based on data pulled from all over the place.
Now, get nuttier and bring in some intelligence with robots that can do some inference and reasoning. Say I throw out some facts: Mammals breathe oxygen. Men are mammals. Joe is a man. With the right client, the query "Give me all oxygen breathers," will include Joe in its results.
Whew. There. That's what I think I understand about the Semantic Web.
[ ... 716 words ... ]
Should I be concerned? About me, Les Orchard, Googlism says: "les orchard is going weird again" About the other name variations I've used online (ie. l.m.orchard and Leslie Michael Orchard), it has nothing to say. Though, it does tell me that "decafbad is getting left out of the pipeline".
[ ... 50 words ... ]
A bit more meditation along the geek-turned-shepherd theme: I've always joked with friends and co-workers that someday, I'm going to go off the deep-end, quit my job, and do one of three things:
abstain from touching another computing device for the rest of my life and live out my days gently raising sheep for wool.
renounce all personal wealth and possessions and enter grad school on a ?PhD path, intending one day to become a professor
go completely apeshit bonkers, develop a slew of dramatic twitches and tics, and speak exclusively in pronounced punctuation symbols until they gag me.
So I've got that feeling again, but any expressions of frustration and angst I've tried writing so far all strike me as spoiled whining. Professionally, I still have a job in the field I love and I doubt that this is in jeopardy, despite shipwrecks and employment carnage everywhere I see. And I'm not facing financial hardships, just minor budgeting dilemmas. Personally, I've only just turned 27 last week. I have a wonderful love and a mostly whole family. And other than some minor surgery approaching, I have my health.
So, in general, life's peachy. But, it only takes one solo death march project and a bit too much personal investment in one's work to lose perspective and make things taste sour. You can see the beginnings of it and my enthusiasm (and perhaps some of my trepidations) back in mid-July. The current project in question is not the web app platform rewrite I'd mentioned then, though, but rather a new major tool that seemed a good candidate as a "rev up for Java before the rewrite" and a break with Perl as the established in-house development language. So, despite a concerned trackback at the time from Brian Donovan of MONOKROMATIK, I've managed to avoid descent into that level of hell thus far. (This may still be naivete - but I'm not yet convinced that starting this over in Java is a bad thing.)
So, my project at present started off as a new venture, with new technologies and techniques, and a planned end product of immense value and demand for the company. But now, it's ending in a vague cloud of missed deadlines and frustrated expectations. A slew of "missing" features have been added far beyond the woefully incomplete original scope, yet features expected from the start have dropped, leaving a sum impression of a diminished result. Initial deadlines have been blown by months, leading to an abandonment of testing and documentation just to sprint to the next already unrealistic due date.
With whom does the blame lie? With everyone - with no one - but no matter: I'm a perfectionist, so I choose myself. I tell myself that I should have known better than to have agreed to that timeline - I should have better forseen the unexpected. I should have never let go of my pristine test-driven development for perceived speed - mystery bugs and instabilities are biting me now. And I didn't stick to my guns on feature creep - the "wouldn't it be nice if" genie is out of the bottle now.
All I wanted was to be accomodating - to deliver an affordable, massively flexible product in a perceivably reasonable timeline that satisfies all parties concerned. And as I write that somewhat convoluted sentence, I realize both that that really has been my motivating goal, and that the goal is unlikely to impossible. Infinitely more so for just one guy, left mostly to his own devices, to pull everything into order. Funny, at the time, I didn't feel like a one of the "hotshot programmers who are convinced that they can run barefoot all the way to the top [of Mount Everest]." (See: Yourdon.)
So what mystifies me now is this: I'm a smart guy, I've been through a few trying times and I read a lot and I try to pay attention. The development pattern I've just described is neither new nor unknown to me - I've been here before and I've read the accounts of others who've been here before. And I know the benefits in sticking to a clean test-driven dev cycle, and keeping a stern check on scope creep. I know these things, and I try to practice these things - I'm normally known as the guy who pees in the happy idea cheerios - so what hit me this time?
I'm carefully trying to steer clear from writing a rant or a whine - I know that my angst comes from a loss of perspective in being nose-to-nose with this project. I know it will get better once this is done, and I know from recent developments that this project can and will be rescued unlike many doomed projects. It will be good and well used and the disappointments will fade. But for the life of this project, the late nights and my absence from life online and off have been real, as have been the doubts and fears.
That said, what the hell happened? And how can I prevent it in the future? Is it just a matter of guts, principles, and discipline? I don't think I'm personally in the wrong line of work - but this sort of thing puts me in an unfortunate mood to question everything. Hmm, I know I've intimated that I'm well read - but I've yet to actually read Yourdon's Death March. I think it's time to dig into a pile of his works.
Anyway, it'll work out in the end. In the future, I need to learn how to steer clear of these rocks - though it seems Yourdon asserts that the rocks are unavoidable. So, even with the knowledge that this is not the end of the world, contemplating doors 1, 2, and 3 seems peculiarly attractive. I'm leaning toward #2 as the more healthy alternative, but it might be fun to pursue some combination of all three.
I'll let everyone know which I choose, when the time comes - but the message may come entirely encoded in non-alphanumeric ASCII.
[ ... 1020 words ... ]
Still alive... I think. Have worked about 40 or 50 hours in the past 3 days. First release of work project happens tomorrow, after which I hope to take a 4 day vacation to celebrate my and my girlfriend's birthday (Oct 24, same day).
Some revelations over the last few days:October is not 31 days long - it is 31 days and one hour long.Java has a class to handle date manipulations that I forgot to use, for some reason - but now that I know about it, there's some major rearchitecting in store to use it.I'm tired of bar graphs, web server logs, and explaining how the tea leaves are read.I like my new Treo Communicator - it is great for playing kMoria (but not NetHack) and quickly SSH'ing into a server from bed to restart a process about whose death I was paged on the same device. (ooh, what if the pager message could contain a button to connect to the server crying wolf?)I've come to realize that I enjoy playing NetHack and kMoria between compile-and-test cycles at 3AM better than I ever enjoyed Everquest in quieter times.On the drive home, as the sun was rising, I was trying to think of just what aspects of Everquest (beyond graphics and besides multiplayer) are better than the family of Rogue-like games. And... could someone hack together a Rogue-like UI with which one could play Everquest?Also on the drive home, I was thinking that I'd like to take a break from being a geek and a software architect altogether, and maybe raise sheep and make sweaters for awhile. What do you think?Hernias suck, and impending surgery is stress-inducing.
Hopefully I'll be recovered and returned to the world after next week. I've been vaguely poking my head in and around the neighborhood, but with my iBook suffering from seizures and my brain feeling like an alien abduction aftermath, I'll have a lot of catching up to do.
[ ... 1198 words ... ]
Still fighting my way through the following: iBook hard drive crash (it's still making that noise, though I thought I could cordon off the bad blocks)subsequent email loss (tried to mail me in the last month? try again, please?)final sprint to the end of a work projectMy girlfriend's moving in with me!It's my birthday and her birthday (Oct 24th), and our dating anniversary (Oct 27th) (strange alignment, that)
But, the work project's almost done. Going on a vacation this week to celebrate the birthdays and anniversary. And I'm not sure yet what to do with the iBook. But! I plan on torturing myself into prodigious amounts of writing again by having a go at NaNoWriMo.
[ ... 115 words ... ]
Ugh. Hard drive in my little iBook is going "brr-tick-tick-tick-tick. brr-tick-tick-tick-tick." while various processes inexplicably freeze up and go AWOL. These are things I've come to recognize as the death of a hard drive. So, since I've been putting everything on my laptop lately, I'm feeling a bit lost today. No email via local IMAP filtered through SpamAssassin and things. No news aggregator. No outlines. Currently running a disk utility that I hope will route around the damage, but I'm not sure.
I know it's gratuitous, but replacing my iBook with a ?TiBook that I don't have to pay off for 18 months sounds mightly nice. But, I promised myself and my girlfriend that the Treo was the last toy for awhile, until I have everything all paid off. That, and I keep hearing rumors of a new ?TiBook in the ether, early next year. Yeah, yeah, wait for the next latest and greatest and I'll be waiting all eternity, but waiting in this case would appear to align with other more prudent goals.
But either way, I'm feeling my lack of computing support today like a sleeping limb. I'm such a dork :)
[ ... 278 words ... ]
So I finally broke down and bought a new gadget. My phone was 5 years old and losing its antenna, and my Handspring Visor Deluxe (pre-ordered the day of introduction!) was showing its age. I was thinking that, for the phone, I'd get something small and sleek. Something that would likely fall through the little hole I inevitably have in every pocket of every jacket and overcoat I own. And I was thinking that eventually, I'd procure a Sharp Zaurus to replace my PDA. I would miss the Palm OS platform, it having done alright by me for about 6 years now, but I wanted excitement! and adventure! and modernity!
Well, after long deliberation, I saw that ?CompUSA was having an 18-months same-as-cash promotion, so I finally dragged myself in there and purchased... A Treo Communicator 300.
What can I say? I had a service contract with Sprint yet to expire, and had heard decent things about the device. And it turned out that I just didn't want to give up Palm OS quite yet, and all the other powerful phone-and-PDA combos were so hideously brick-like. (I know, let's take a standard Pocket PC, and Krazy-Glue a speaker and a stubby antenna on top! It'll look brilliant!) And along the BlogWalking theme, among other things, it does wireless internet admirably well and for a price that I'm not sweating too hard to pay. The HipTop might've done me better, but like I said: contract I'm still stuck in, and Palm OS that I know how to hack.
Before I'd gotten it, I obsessively poured over reviews. One of the biggest horror story themes I caught was with getting the thing activated on Sprint's network, back in August. Well, no sweat for me there. I called up the activation number and was walked through the process by a very polite gentleman with a pleasant Indian accent whose phrases and reponses were so identically spoken that I thought I was speaking with a machine. (Am I looney, or had I read somewhere that many call centers were being outsourced to India and lands abroad via some nice WAN technologies?) The new Treo was ringing and hitting Google within 10 minutes after I got off the call, despite his cautioning me that it might take upwards of 6 hours to get processed.
Once working, the earbud/mic supplied with the device worked very well. Holding the thing up to my ear is nicer than one might expect when pressing a small slab to the side of one's face, but I'll probably use the earbud more. Now if I only had an elegant way to stow and fetch the earbud on my person while I'm out and about. Unspooling that tangle is no way to quickly answer the phone.
As for applications, I had everything from my old Visor transferred in short order, including my body of data whose history went all the way back to my first blocky Palm Pilot. After that, I went out and snagged a large blob of net apps and synced them up. AIM, SMS, IRC, SSH, VNC, ICQ, email (via IMAP!), and most importantly Google via Blazer all worked great. (Although, you have to watch AIM. It does nasty things occasionally and seems to corrupt its databases, requiring a warm reboot, deletion, and reenabling of all your hacks and extensions.)
So, shortly I'll be looking for a way to combine AmphetaDesk or ?OffNews with ?Plucker to give me a way to package up and slurp down a day's reading like I used to do with ?AvantGo. The funny thing, though, is I don't know whether a single package-and-sync of reading is enough in a day. It used to be - I would slurp down News.com, Wired News, Slashdot, and a smattering of other sites and be set for the day. But now, I check my AmphetaDesk at least 6-10 times a day. Given that, and the fact that I do have a decent allowance for data per month, I may look at putting AmphetaDesk out on my JohnCompanies server and whip up a Blazer-friendly skin for it using some ideas from AmphetaOutlines to hide redundant items and save me some bytes.
It's such a difference now, using the Sprint data network with this slim and elegant little Treo, versus when I first bought a Novatel Minstrel for my Palm III and used it to vaguely, slowly, gradually poke around on the web with that solid brick of magic stuff. I can't wait until all of this finally converges with affordable, socially inobtrusive wearables.
I also just got done reading another VernorVinge story, Fast Times at Fairmont High. I blame him for this. I want display contact lenses, ubiquitous networking via computing clothes, consensual imagery overlayed across all I see. I want twitch-speed access to searches so that I can pick up on the song or poem someone starts quoting, and complete the line for them. I want to ping objects around me and have them respond with self-identification. I want to live-by-wire. But until then, I have a wireless net connection on my Treo with a keyboard that makes me look only slightly geeky when I type. That, and a desire to get my butt back into school so that maybe I can get the credentials to climb my way into research with tech like this.
[ ... 898 words ... ]
This is why I love the web & blogosphere these days. It's getting just a little harder to get away with bullshit every day. :) Threads cross at on Dave's site and Metafilter, among other sites, and Microsoft's counter-Switch ad is revealed.
Man. And they even used a clip art image for the "real person". I've not been in the web biz, ad biz, or promotions biz for very long at all, but I've already developed a cynical chuckle for clip art people. I've either searched through sources myself, or been at the shoulder of a creative director while she or he did the searching. It doesn't take very long until you can nail it when you see it.
But clip art in and of itself isn't bad - it's when an attempt is made to pass the clip art over as some kind of candid reality... that's when a company really shows how smart they think you are. :)
(Oh, and P.S.: Can you people please stop using those "photographer standing on a stool over a model looking up" posed images? It really doesn't convey hip, cool, or clever.)
[ ... 482 words ... ]
Mark Pilgrim implements something I've been thinking about for awhile: His "Further Reading Upgrades" now harvest what appears to be the paragraph surrounding a link on a referring page. Along with the RSS feed of "Further Reading" items he's made available, he's got a nice game of follow-the-leader set up for the rest of us referrer log watchers. Nice & elegant & makes me ashamed. :)
Update: Mark pulls back the curtain and reveals the secret. Yay!
Yet another demonstration to me that ideas are f'ing worthless and the making is what matters. Lots of things I've been thinking about doing, but never get done. (See also: Blog:000305) Just a few weeks ago, I managed to upgrade my referrer tracking to dig out the titles of referring pages. And I've had an RSS feed of referrers myself for a few months now, but mine's been ugly as sin and so I've kept it to myself. So now I'll need to think in earnest about how to do some extraction of the link-surrounding excerpt in referring pages. Mark's referrer handling really is elegant - it even seems to know how to collapse multiple views on the same referring entry (ie. front page, archive page, individual entry page).
More things to play with :)
[ ... 681 words ... ]
Funny, I've just been toying around the last few weeks with doing just this, for AmphetaOutlines, to cut down on the wodge of HTML it feeds the browser all at once. Marc Barrot presents Transclusion Breakthrough: The Endless Web Page. The post reads a bit like an advert for Amazing Live Seamonkeys!, but I think the enthusiasm is understandable:This is the in-browser version of what Dave Winer and UserLand created for Radio's outliner.
This is instant rendering, happening on the fly as you browse through the current page. It is totally recursive: try clicking on the 'endless web page' node that appears under my name in the demo page.
Now, I'd like to dissect and figure this out, and add it to my AmphetaOutlines hack so that I can stop loading 5MB (!!!) of HTML every time I reload the page. Beyond that, I can see some very cool applications involving live data navigation and outline rendering and... yeah. This is cool stuff.
[ ... 163 words ... ]
Hello everyone out there. I've been busy as hell these last weeks, for reasons personal and professional, but I wanted to take a second to say something:
Thank you for writing. You make me cheer, and you make me cry.
This makes me think about being a bit more human in this space, along with being the tech obsessive here. My LiveJournal has caught most of my personal entries and rants, but maybe I'll finally merge the two. Not that I've had much time for writing lately, unfortunately, but it's heading toward colder and longer nights here, and I'm sure the urge will strike.
[ ... 105 words ... ]
Like the MTCleanHTMLPlugin I released a little while ago, Brad Choate's new MT Sanitize Plugin appears to do the same job. I haven't tried it yet, but since I'm using a pile of Brad's plugins and have based all of mine upon his examples, I'm assuming it's good stuff. I'll likely check it out and see if I like mine or his better for my own use. :)
(Oh, and in case anyone wonders, I mean "competitor" in the "there's no competition because his code-fu's likely better than mine here" sense. :) )
[ ... 284 words ... ]
Seen at HipTop.com:Hiplogs Online Journals?It's your chance to be a star! You and your trusty T-Mobile Sidekick, that is. Share your deepest thoughts or wildest whims online with a public journal you can update on the go!
See? BlogWalking is a nascent meme! Or something. Yeah!
[ ... 90 words ... ]
More on Pingback vs TrackBack on Hixie's Natural Log.
How embarassing - he points to my referrers as a typical list. :) Mine are crap. Look at how Mark Pilgrim handles referrers. Yesterday I was working at making my referrer tracking harvest titles, clean out false links, and collapse redundant backlinks, but I'm far from perfecting that. But, at the same time, I agree: Referrers are not enough. They're one source, the most noise-ridden but the most effortless on the part of the outside contributor. But you can only do so much with almost nothing. :)
I think, when it comes down to it, my only issue with Pingback is not a Pingback-specific issue at all: How to harvest machine readable metadata from a web resource. This applies to my referrer links, Pingback, and TrackBack alike. TrackBack has a bit of a solution, with embedded RDF, but that's got its own issues. Ian suggests a few things to me in comments, such as harvesting the title from the HTML title tag (a no brainer), and then harvesting further data from DublinCore-based data in meta tags in the page. I've seen this last convention only once before, in the geographical data consumed by Syndic8.com.
Is this a pretty common convention? I've not seen it done much, but the I obviously have not seen everything or a large chunk of anything. :) If this is a known convention, it makes me happy and I think it would answer a question I asked back in May.
Update: Duh. Yes, it's a known convention. It's even got an RFC: RFC2731: Encoding Dublin Core Metadata in HTML Simple Google search. Sometimes I can be so daft. :) Now I just have to start using this more - and I wonder why more people aren't using it? Most likely because there's been not much in it for them.
[ ... 313 words ... ]
Dave writes on "RSS and Namespaces":... there are some XML parsers that don't properly deal with namespace attributes on the top-level element of a source.
Agreed. These parsers are often cheaper to deal with when you know that the format you're expecting doesn't involve namespaces. You trade some flexibility for some ease of development.For these guys, just introducing an xmlns attribute is enough to make them reject the feed. So while they could handle a 0.92 feed, as soon as we introduced the xmlns attribute, they gave up.
Yes, because they weren't expecting to be fed something with namespaces, since they'd been designed around v0.92 and family, and had been fed v2.0 with the expectation that it was 100% backward-compatible....Presumably RSS 1.0 doesn't have the same problem we tripped over yesterday with RSS 2.0. So I looked at a few RSS 1.0 feeds, and guess what, they do the same thing we were doing with the 2.0 feeds. ... I conclude that the same broken parsers that didn't like the 2.0 feeds with the xmlns attributes, must also not like the 1.0 feeds.
And your conclusion would likely be correct - because those parsers weren't expecting to consume namespace-using XML, and they shouldn't be expecting RSS v1.0. If an application is designed with RSS 1.0 in mind, then the author should be using a namespace-aware parser and correctly handle the namespaces, since that's the nature of the beast. To neglect or mishandle namespaces in consuming RSS 1.0 is a mistake.
Admittedly, some applications which apparently consume RSS v1.0 feeds correctly may be broken in this way - this is not unique to RSS v2.0. If they're broken, they need fixing. But that's another story...
So, on to the conclusion:If this is true, we can't design using namespaces until:
All the parsers are fixed, or
Users/content providers expect and accept this kind of breakage (I don't want to be the one delivering that bit of bad news, got burned not only by the users, but by developers too, people generally don't know about this problem, or if they do know are not being responsible with the info).
Anyway it looks to me like there's a big problem in the strategy of formats that intend to organize around namespaces.
Well, of course, end users should not expect breakage. This is obvious to me. No one really wants that.
The big problem I see in the strategy, though, is this: RSS 2.0 claims to be backward-compatible with the 0.9x family, but the addition of namespaces in XML is enough of a fundamental change to break this. I think what Shelly wrote in RSS-DEV is correct: "Namespace support is NOT a
trivial change, and will break several technologies, including PHP if
namespace support isn't compiled in. This isn't something that can be
hacked out."
When I originally read about the emergence of something called RSS 2.0, I said "Go man, go!" But I also said, "What's the catch?" Well, this appears to be a catch. But I think it can be worked through. This is not a fundamental problem with namespaces themselves. This is a versioning problem, and a problem with anticipating all the implications the new version brings to the table. This goes for RSS 2.0, as well as RSS 1.0.
The first thing is to nail a few things down about version numbers and reverse-compatibility. It's been my experience that, when some thing experiences an increment to its major version number, reverse-compatibility is not guaranteed. So, I would assume that from a v0.94 to a v2.0, things are sufficiently different that using it would require that, indeed, "All the parsers are fixed" to support the new major version. So for the most part, v2.0 follows the v0.94 tradition faithfully, but on this issue it parts ways - and yes, potential consumers of v2.0 feeds will need to adjust from their v0.94 code. Thems the breaks, I've been told, when it comes to major version upgrades.
So, again, I don't think that this is a fundamental flaw with RSS 1.0, RSS 2.0, or namespaces. This is an issue of versioning, understanding the technology's implications, and reverse-compatibility.
[ ... 918 words ... ]
Quick update to MTCleanHTMLPlugin: renamed the directory extdir in the tarball to extlib, which is what it should have been for easy drop-in installation. Thanks to John of illuminent.com, whose weblog gets me funny looks at work. :)
[ ... 144 words ... ]
Tonight, I borrowed LiveJournal's comment filtering code and made it into a MovableType plugin: MTCleanHTMLPlugin
After all that ramble about having open system and not having been the victim of an exploit, SamRuby inadvertently revealed one gapingly wide hole for me. Not that he did anything to exploit it - I just realized that a bug he tripped over could be used for more nefarious purposes. So, I closed the hole, and after a bit of quick research went a bit further and made a new MovableType plugin. Borrowing LiveJournal's code yields a filter which strips out most nasty ?JavaScript exploits, and attempts to close tags left lazily open.
Hope someone finds a use for it.
[ ... 416 words ... ]
I completely disagree with Ray Ozzie ("I'm thinking right now that I'd prefer to stick with human talkback rather than automated pingback"), John Robb ("I don't want pingback, trackback, or refererback."), and Sam Gentile ("Amen to that.").
I want as much automated and intervention-free invitation to participation in my blog as I can provide. I want manufactured serendipty to operate here while I'm away or asleep. I want this site to help me discover connections and uncover links, whether by automated agent or by friendly visitor. I want to lower the thresholds to interaction as far as I can. I love it when I've seen a few visitors to my site talk amongst themselves while I was on my drive to work.
Of course, I've never been cracked or assaulted by an exploit of my systems. I don't have unwanted stalkers or abusive anti-fans or malicious kids or babbling spammers after me in this space. Perhaps if I did, my systems might not tend toward such openness. I think this is a statement on many things beyond blogs, but that's a post for other days. Maybe some day I'll have these negative elements facing me, and I'll have to revise my systems and their direction to account for them.
On the other hand, I've got a naive notion that the openness itself can counteract much of the reason to become closed in the first place. Should the need arise, I think I can come up with some measures to deflect inane and juvenile attacks. As for spammers, I tend to think that their days are numbered anyway - but if they do arrive on my weblog I think I can leverage many of the technologies I use right now with great effectiveness on my email inbox. But, to defuse real frustration behind attacks, I tend to think that more communication, not less, is what's needed.
But I'm not sure at all, though, whether or not the threat of abuse is what motivates Ray and John to leave automated discussion channels closed. It's just one motive I've seen discussed before. I think they want more "human" and personal contact.
With regards to that: The irony in my life is that, with my lack of much free time, automated agents, aggregators, and weblogs have given me more personal contact with human beings than I might have been able to achieve without them. I'm trying to remember the thread a few months ago between DaveWiner, JonUdell, and others concerning humans with the uncanny ability to connect other people together. This very thing was supposed: That aggregators and weblogs could augment one's ability to act as such a superconnector. In that regard, I consider my agents, aggregators, and weblogs as integral to me as the new and improved pair of glasses I picked up last week. Just as I can't see road signs without my glasses, I can't keep track of people without my agents.
ShareAndEnjoy.
Update: And happily, Greg Graham, someone I've not met before, sends me an unexpected TrackBack ping and invites me to another blog I've never visited.
[ ... 781 words ... ]
Okay. Enough's enough - the phpwebhosting server's disk filled up again, and my JohnCompanies server has been idle all this time. I've moved everything over, made a cursory set of tests to see if everything's okay, and flipped the DNS switch.
Hopefully, you're seeing this post. Otherwise, you probably saw a test pattern until the DNS wave of mutilation reached your corner of the net. In the mean time, a few random things will likely be broken. I'll be sorting through those in the next week or so. If you feel like letting me know when you find something, I'd be much appreciative.
Thanks!
[ ... 141 words ... ]
And of course, Ben of MovableType is not unaware of Pingback:In current implementations of TrackBack, the user sending the ping must take some action: either by selecting the post he wishes to send a TrackBack ping to via a pulldown menu, or by retrieving the ping URL and pasting it into the entry form. And yes, we agree on the point that transparency is the ultimate goal*.
But note the emphasis on "current implementations"--there is nothing inherent in TrackBack that would prevent an implementation from making it completely transparent.
Interesting. Let's see where he goes with this. He does raise a concern with more automation though:* (I do worry slightly about the impact of content management systems fetching and scanning every external link in an entry to determine if it's ping-able. But that's not really the issue.)
Hmm - I suppose if a site gets heavily referred to, that's a double-Slashdot-effect? And this investigative process has the potential to add more overhead to the publishing process. But.. hmm, until I see some convincing ConsideredHarmful arguments, I think the flow producing qualities of this sort of thing are worth it.
[ ... 260 words ... ]
I've got some further thoughts on Pingback, provided that my server humors me.
David Watson says, "uh, no," citing a horrible experience in actually trying to see the spec in the first place, and a lack of working code. Not to mention that my site was having a seizure last night - not good things to recommend that one check out a new technology.
Well, I did manage to see the spec, but haven't tried implementing it yet. (Though it shouldn't be too hard, given a few round tuits.) A few things, in particular that I like about Pingback:
URIs are used to specify the source and target of the ping, no other information is involved in setting up the relation (ie. arbitrary IDs, etc). This makes site-wide integration of Pingback drop-dead simple - everything's already identifiable via URI.
If one implements Pingback HTTP headers, one can allow non-HTML resources to be pinged. (ie. Ping my FOAF file when you add me to yours, and I might add you to mine. That might be pushing the spec a bit, though.)
The XML-RPC server is not tied to any sites it may serve. I could offer one here, and you could point to it from your site, and if I allowed it I could record pings for you as a service.
All-in-all, Pingback just seems like a more direct, intentional form of referrer log.
One thing I don't like about Pingback, though (and the same for referrer logs): It's just about URIs and links between them. It says nothing much about titles or excerpts or comment bodies. The spec suggests that a Pingback server might retrieve "other data required from the content of Alice's new post," but makes no statement on how this is to happen. I like that TrackBack sets down how to provide a bit more information.
I've got a vague idea in my little head, and I think it's something Sam Ruby touched on: ShowReferers, form-submitted comments, TrackBack, and Pingback are all just different on-ramps to inviting open participation in discussion on one's blog. I want to take a shot at implementing Pingback very soon - but I might also try taking a shot at implementing a unified comment system that accepts comments for any URI from any of the aforementioned sources. I'd also like something that scans a blog entry I post for links, then investigate those links for Pingback/TrackBack availability - all to make the system even more automatic. I doubt that it would be very difficult, though I am notoriously naive. On the other hand, I've been on a run of making hard things simple lately. :)
But I sense my round tuits slipping away - back to work!
[ ... 1108 words ... ]
Amongst his heavily medicated rantings, Mark Pilgrim points at something called Pingback. At a cursory glance, it seems to answer all my initial gripes about TrackBack. So, I think I'm going to take more than a cursory glance, and make an implementation in the next few days if I can't find one ready-made.
Some initial wishes for Pingback: How about making it two way? Ping a URL via its autodetected Pingback server, and also retrieve a list of pings for that URL from that server. Another idea, add a pub/sub method: I supply a URI to monitor and a URI of my own, and the remote Pingback server will ping me at my URI (via my Pingback server) when the monitored URI gets new pings at the remote URI. Require that the subscription be renewed weekly/daily. Make sense? One way to track conversations.
[ ... 144 words ... ]
After following the thread on Sam Ruby's blog about Dave's comment tracking feature request, I figured I'd try RSS-izing comments on each of my posts. As things seem to have been going lately, I'd underestimated MovableType, and it turned out so much easier than I'd thought. :) I'd had an RSS feed for comments overall on my site, but now I have individual RSS feeds for each post. (Notice the in the comments section now.) The RSS feed is also linked in the head as per RSS autodiscovery discussions.
I don't think aggregators are really ready yet for these per-post comment RSS feeds, but the availability of the data gives food for hacking. Being that they're pretty disposable and of interest for a very short time, aggregators will likely need to implement expiry times for feeds, or watch for a period of inactivity before unsubbing. Grouing feeds would be nice too, in case I wanted to round up all my points of weblog discussion participation. I've got a few things of this sort in my AmphetaOutlinesWishList, with which I hope to play with further aggregator ideas.
If you use MovableType and you're interested in trying this, check out these two templates: recent_comments_rss.xml.tmpl, for blog-wide comments; and archive_entry.rss.tmpl, for per-post comments. The former template is added as an index template in MovableType, whereas the latter is an archive template. Also, the per-post archive template will need to be added to the list of individual archive templates in the Archiving section of your blog config. You'll want to give it a template for the filename, perhaps something like <$MTEntryID pad="1"$>.rss.
At present, I'm publishing in what I think is vaguely RSS 0.92 format. Whether it complies with the spec, I'm not quite sure because I was lazy. I plan to revisit this soon to make it at least comply with RSS 1.0. ShareAndEnjoy.
[ ... 681 words ... ]
So I was just reminded by Mike James about this tip on running Classic from a disk image on OS X that I'd previously found via Mark Pilgrim. I think I need to try this the next time I feel like wiping and reinstalling my iBook. I've been meaning to try a different file system under OS X - like, you know, one that's case-sensitive so that something like /usr/bin/HEAD doesn't overwrite /usr/bin/head. That, and I just don't have very much use for Classic anyway, other than for 2 or 3 apps.
[ ... 93 words ... ]
For the hell of it, I have a FOAF document now: lmo-foaf.rdf. I don't yet completely understand the spec, but via a referrer left by Tanya Rabourn, I found Leigh Dodds' FOAF-a-matic and gave it a shot. Need to do more research.
[ ... 51 words ... ]
Oh, and a quick thing I feel compelled to share: JohnCompanies is the best hosting I've had so far since I started this domain. I have yet to move everything over to it, but I'm so very impressed at the notices I've been getting. There were two brief outages recently, one planned and one not planned, but the important bit is that I received email telling me about them and what happened before I was even aware there was a situation.
I like that.
Update: Shawn Yeager commented that the outage wasn't really all that brief - 9 hours in fact. So... well, that does suck. Personally, I didn't suffer from it, having yet to completely rely on them. I do, still, enjoy having gotten the email. :)
[ ... 291 words ... ]
Saw this on Jon Udell's blog via the #RDFIG chump feed, from Sergey Brin: "I'd rather make progress by having computers understand what humans write, than by forcing humans to write in ways computers can understand."
Well, sandro on #rdfig writes "Why am I arguing with a sound-bite?" Why not? :) Here's a counter-sound-bite: Use Newton handwriting recognition, then try Palm's Graffiti and come back and tell me which seemed more worth while.
The way I look at it, people have muscle memory and can form habitual patterns and can adapt around interfaces that can become transparent and second nature. That is, if the interface doesn't go too far away from usability. I think Graffiti was a good compromise between machine and human understanding. Let the machine focus with its autistic intensity on the task at hand, and let the human fill in the gaps. This is why I fully expect to see Intelligence Amplification arrive many, many moons before Artificial Intelligence arrives, if ever.
I doubt that machines will ever come up far enough to meet man, but man and machine can meet halfway and still have an astonishing relationship. So, one can spend enormous resources trying to make computers understand people (who barely understand themselves), or we can make understandable interfaces and mostly intelligible systems and fudge the rest.
[ ... 657 words ... ]
Today's bundle of little discoveries:
DSBRTuner has been updated to support AppleScript since last I downloaded it.
DSBRTuner has been updated to record to MP3 on disk.
MacOSX has a command called osascript with which you can launch AppleScripts (among other things) from a shell.
Like perl, osascript has an option -e to run a one-liner from the shell.
Given these discoveries, I was able to cobble together a quick pair of scripts with which to schedule recording radio broadcasts to MP3 via cron.
Wow. Another little project that became, all of a sudden, so much easier than I thought. I love Unix and OS X. Before this, I'd been looking high and low for all the parts: a scheduler, a sound recorder, an app controller, etc & so forth. Given the source code to DSBRTuner, I was almost about to hack some solutions into it, but I'd never gotten the time.
Now, I can happily record and listen to my favorite late Sunday night radio show during the week again!
Oh yeah, and the ugly scripts:
dsbr_start_recording#!/bin/sh
FREQ=$1
MP3_FN="$2-`date "+%Y%m%dT%H%M%S"`.mp3"
OSA=/usr/bin/osascript
TELL='tell application "DSBRTUNER" to'
open /Applications/DSBRTuner.app
$OSA -e "$TELL set frequency to $FREQ"
$OSA -e "$TELL record to file "$MP3_FN""
dsbr_stop_recording#!/bin/sh
OSA=/usr/bin/osascript
TELL='tell application "DSBRTUNER" to'
open /Applications/DSBRTuner.app
$OSA -e "$TELL stop recording"
$OSA -e "$TELL quit"
[ ... 260 words ... ]
John Robb writes: "Wouldn't it be interesting to have an RSS variant (new name obviously) for subscribing to personal contact data off of weblogs?"
I read that DJ Adams was just playing with FOAF not too long ago, and at the time it made me want to dig into RDF more. But, work got busy and I promptly got distracted away. If anything, though, I could see something like FOAF being really nice as a start for this purpose. Of course, there's vCard, but I think it wouldn't be very hard to convert to it from FOAF. The universality and connectivity that RDF could bring to this seem terribly nice. Throw in periodic auto-refresh, either literally by scheduled re-query, or by pub/sub notification, and you've got a neat auto-updating address book just for starters.
[ ... 632 words ... ]
A very interesting side-effect I hadn't thought of yesterday when I integrated MT-Search into my wiki is that every wiki page is a mini-content index to my weblog. Even the really sparse wiki pages where I've only blurbed a sentence or so about a topic - now they have some decent content in their pointers back to the weblog where I mentioned them.
One idea that immediately strikes me is that I need this at work. I've got a barely attended-to experiment in journalling started there, using a LiveJournal installation. If I could get a similar search hacked into LJ, or scrap LJ and give everyone a MovableType weblog... we could very easily integrate up-to-date topic indexes into our existing company wiki.
For instance, wiki-word-ize a client's name, and create a short wiki topic page for that client. Or, refer to the wiki words belonging to our products. Then, be sure to include those topic strings in any weblog entries you post internally, and those wiki page will pull in your contributions. The cross-threading of this seems great to me. Show me all mutterings about ?ClientAlpha, and then show me all mutterings about our ?InstantWin product. In some cases, a particular weblog post will appear in both.
Wow. That's getting very close to what I wanted.
[ ... 367 words ... ]
One more thing, before I go to bed: An AmphetaOutlines update.
I'm not sure how many of you are still using the thing, but I've been using it hourly since I embarked upon the experiment. And then, very recently, the thing became insatiable with desire for my CPU and memory.
Turns out, in my spiffy new XML channel/item metadata files, I wasn't deleting data associated with old and no longer available items. This resulted in multi-megabyte XML files which AmphetaOutlines happily munched through for each channel to which I'm subscribed. Well, this update now regularly cleanses those files, leaving metadata stored only for those items that appeared in the current update of the channel.
So, if AmphetaOutlines has been becoming a dog for you, you might want to give this a shot. Upon the first run, the new code will wipe old data from the files. If your poor, battered machine can't survive another run in the current circumstances, then wipe the contents of data/channels_meta and start again. (But don't wipe your subscriptions or channel data! Just the channels_meta data.)
Let me know if this does good things for you. In the meantime, I'm thinking about what I could do by applying these ?BayesianAlgorithms (and those not-quite-so-BayesianAlgorithms) people have been tinkering with for use against spam. What if I could have AmphetaDesk initially sort my news items into ordered buckets of interest, according to my past viewing and scoring behavior? I really need to do some machine learning research.
Hell, what if I could go further and have a spider crawl blogrolls, looking for weblogs that seem to match other things I find interesting? Seems promising, though I think I'm still too naive about the subject.
Okay. Time for bed.
[ ... 783 words ... ]
I just discovered and integrated MTSearch into DecafbadWiki by using a TWiki include to pull in a search constructed with the current wiki topic's name. It took all of 15 minutes, including the time to login and download MTSearch to my server. This, along with my MTXmlRpcFilterPlugin, completes a simple but effective automatic loop between blog and wiki. I think this pretty much satisfies my original goal of a WeblogWithWiki.
That was so much easier than I'd thought it would be. One of those things I kept thinking "Wouldn't it be nice if?" but kept procrastinating because I thought it'd be so much harder.
I'm still amazed that ItJustWorks.
[ ... 599 words ... ]
In happier news, I'm very glad to see string of annoyances and disasters along the way. I still think she should've switched to a Mac though. :)
[ ... 40 words ... ]
I don't really want to add noise to the signal and would really rather just see some work get done, but I'm still disgusted by what Dave is writing:...One of UserLand's competitors Kevin Hemenway, the author of Amphetadesk
Competitor? He was originally a customer of yours. Then, just for the fun of it, he made his own implementation of the news aggregation features of your software, and even acknowledged his source of inspiration when he released AmphetaDesk, calling Radio "a wonderful piece of work". AmphetaDesk isn't for sale - it's free and open source. If that makes him a competitor to your selling product, I think you need to work harder or smarter....explains on his weblog how he intends to kill me. Even he says it's too harsh; and it may be a joke, if so, it's not funny. I don't see the humor in my own death, esp at the hands of a person like Hemenway. (He also coined the term Jewgregator,
Morbus is over the top on a frequent basis, and sometimes too far over the top. This is a known fact - his sense of humor is obviously dark and a bit off kilter. He also produces good working software, and writes useful articles. But three obvious things: 1) He didn't state any intention to kill you - it's just that it seems his mere presence would be enough to set you a-boil. 2) He referred to Kevin Burton's account of meeting you, which depicts you as someone very easily set a-boil. 3) You're providing an example in support of the account.and calls RSS 2.0 "Hitler" for some reason.)
The "some reason" to which you alude is this bit Morbus said in IRC: "I say 'proposed' rather innocently - its more 'shoved down everyone's throat by nazi dictator'... we should code name rss 2.0 'hitler'". There's frustration in there, and his wasn't the only head nodding in the room. Morbus is over the top and says charged things I'd choose not to, but the frustration is real and genuine, and shared by more than one member of the community out here. Yet, you always seem to "take the high road" by focusing on the over-the-top aspect, no matter the degree, ignoring the genuine gripe....Bill Kearney has sent me private email about my deathbed, and what he hopes to teach me there, so I've chosen to filter his mail to a place where I never see it.
Referring to private email is cheap - it's your word and his.I tried to come up with a word to describe how I feel about these people, this is what I came up with: monster.
What a nasty thing to call potential collaborators and customers. And what a viral, contagious thing, as you later demonstrate with Ben. This doesn't seem very cluetrain-ish....Hemenway has crossed that line. What happens next is stuff that will involve the police. I won't stand for these kinds of threats.
What threat was made, and when will you be calling the police? And how seriously will they take you? You said yourself that you knew he wasn't seriously threatening you. What stuff "happens next"?None of this means that RSS 2.0 will be delayed by even one moment.
Thus, you avoid having to address the concerns all the "monsters" raise.I thought competition in the software business in the 80s was rough, but this is so much worse. Competition used to require a certain collegiality and professionalism. It's not true today. Anyone who works with Hemenway or Kearney should be aware that these people are nothing less than monsters, who will stoop to any level to get their way. Their perversion may even be the reason they're involved.
But the funny thing about all of this is that most of this isn't business - it's hobby. You've got a business, he's got a hobby, yet somehow he's competing with you. I'm not a businessman by any stretch, but this comparison seems very odd. (Hint: Morbus is not acting as a professional in this context. He can correct me if I've mistakenly assumed this.)
These are people screwing around, trying things, playing with code. And in order for these people to "get their way", they have to be nice to people and convince them to help out. Otherwise, the cats wander off in search of fatter mice. It becomes apparent rather quickly what sort of people they are from just a short bit of interaction with them. And I've seen them "triangulated" as very nice people.Mr. Hemenway goes by the name Morbus Iff on his weblog, and writes for O'Reilly Associates, and for Ben Hammersley's syndication weblog. Mr. Hammersley is a reporter for the UK Guardian newspaper.
Postscript: Ben Hammersley threatened to sue me if I don't remove the previous paragraph. But every statement is true...
Specious reasoning, at best. Yes, Mr. Hammersley invited Morbus to write with him. So, you feel free to splash him with the monster paint by association?The Guardian requests an apology. For what? They ran a tainted review.
Oh, now we see the reason: He didn't plug your product in his review. Though, he did say in the article, "Did you notice how all those programs are free to use?" Perhaps he should have made that more a focus of the article, but he was writing about free programs. I'm neither in his head, nor in the head of any Guardian editor, but maybe they didn't want the article to become free advertising for a commercial product? Who knows. He didn't mention you. So that makes him a monster?Hammersley is a participant in the debate over the future of syndication technology, yet he wrote a review for the Guardian where that was not disclosed.
This is obvious: Many people who write about technology are involved with technology, even helping shape its direction. It's what makes them most qualified to write about it. This argument is starting to sound like politics - from whom did he get his funding? I don't see you complaining when a "participant in the debate" does mention your product in an article.Now, either Hammersley didn't tell them, or they don't care, or British newspapers run ads without saying they're ads.
Or maybe they didn't want to run unpaid ads?
Okay. I'm done. This has distracted me from work for long enough today.
[ ... 2403 words ... ]
Dave writes:Discourse in the RSS community has reached new lows.
Yes, yes it has, and I feel ill. There's more I'd like to say, but I've got to get to work now.
[ ... 32 words ... ]
From Kevin Burton:Are these guys serious? Blogwalking?
Yup. I'm vaguely serious. At the same time, I think it's funny as hell. Can't speak for anyone else.Do they actually own a Zaurus? Ha!
Nope, I said I don't, yet. Duh. :) But, he does.The keyboard is totally unusable. I don't even want to type 'ifconfig' and I couldn't even imagine writing this blog entry on the Zaurus!
Hmm. Well, I can't speak to that. A friend of mine is pretty happy with it and hacks perl on his. If anything, that endeavor exercises the keys.
Then again, I'm very tolerant of bad interfaces in early stages of an experiment. It's the combo of Linux and Java on a PDA that I'm more interested in. Hell, if the keyboard pisses me off after awhile, I'll implement a Dasher-like UI (and walk into telephone poles), or a dictionary-completing UI, or make it interpret a personal code of taps on the space bar. I used to put up with graffiti, and later FitalyStamp, to post entries to my LiveJournal account.
So my first interest, once I have a Zaurus, is to see how difficult it is to get it into the publishing loop of a blog. Then, I want to play with the UI. Actually blogging and walking at the same time, with the present UI, would obviously be comical at best and stupidly tragic at worst. But if it could somehow become streamlined, demand little attention, and become as easy as talking to oneself...
I'm reaching here, but I think it would be neat. I also think digital watches are neat. (See: NeatLikeDigitalWatches)
[ ... 268 words ... ]
Ahh, the joys of upgrading Fink for OS 10.2. I started it Monday morning on both my iBook and the dual G4 450 I have at work, and they're both still going at it.
[ ... 94 words ... ]
Getting religion, Dave says:Nathan Torkington is a humble servant of our lord, Murphy.
I wonder if Dave, or Nathan, or anyone would mind if I used CafePress to make available a set of merchandise based on phrases such as "Praise Murphy", "Murphy Willing", "What Would Murphy Do?", "Murphy Saves", "Have you accepted Murphy as your personal savior?" I might type them all up in a sufficiently imperious gothic font and set up shop.
See, although they might get popular, I wouldn't want to do it for the money. In fact, I'd give it away to charity. I just want the merchandise :)
[ ... 138 words ... ]
Neat! I love the blogosphere. Bryce is attempting to implement what I'd babbled about last week: BlogWalking with a Zaurus. I'm still saving my pennies, and I've yet to acquire a Zaurus of my own. So, I'll be watching this experiment eagerly.
I don't expect it to be perfect or necessarily go smoothly, but it's a first step. Someone had mentioned that a PDA is inappropriate to host something like MovableType, since it's usually off or easy to lose. Personally, I want to head toward having an easily wearable or pocketable device that contains (or at least has seamless access to) all my personal data, so a PDA seems ideal to me. However, maybe a large server at home behind my cable modem would work better as a personal data sink, with the the PDA being more like a personal data buffer. This was suggested in comments on my previous entry as well, I believe.
So, MovableType itself on a PDA and paired with rsync may or may not be nifty in the end. I'd like to try it, and then maybe think about doing something like a BloggerAPI / metaWeblogAPI client that can buffer up entries and fire off the XML-RPC calls at a given sync time.
Hmm... more to think about.
[ ... 214 words ... ]
About switching to Mac, Torrez says (among other things):I haven't loved a brand in a while. The last computer brand I had the hots for was the Commodore Amiga, and that was over 12 years ago. It's nice...but weird.
My thoughts exactly. My first home computer was a Commodore 64 (if you're curious, you can see a picture of me getting it for Christmas). While I was learning to program on the Apple ][e and the Atari 800, my C=64 was home turf after school. Man, I miss 6502 assembly and screwing with a kernal whose complexities I could mostly encompass in one brain.
And then, when the day came that I could afford a new computer.. I saved my pennies and bought an Amiga 1200 (sorry, no picture). That lasted me all through college as friends bought and upgraded (and upgraded) PCs. It wasn't until I was a year or two past graduation, when my poor A1200 was really straining to keep up, that I finally broke down and built a PC.
But now, I feel like I'm back full circle, and the PC's days are numbered in my home. The Mac is my new Amiga, and Apple my neo-Commodore. Now I just hope that they don't munge the whole company like Commodore did - I was there on [#amiga](/tag/amiga) on EFNet on the day when they announced the first of many buyouts.
I'm not too worried though - Commodore didn't have anyone like Steve Jobs.
[ ... 322 words ... ]
A strange little idea I had on the way home today: Movable Type on a Sharp Zaurus equipped with wireless ethernet? Or maybe Bloxsom if/when it has static publishing? Just use rsync to publish whenever the thing finds itself on a network, wireless or otherwise. Maybe that happens while you're out Warwalking - better yet, maybe that wireless network detector you cobbled together autoblogs what it finds while in your pocket.
But, beyond that, I wonder what else having your blog in your pocket might give you? Toss in a GPS unit somehow, maybe some other things like a thermometer device? A compass? Thinking about ways to automatically capture metadata about your present environment. Why? Why not, I'm sure if I thought longer, that stuff would seem useful.
And then there's the non-automatic writing you might do: jot down thoughts occuring on the spur of the moment; capture the scene as you sit in the park; report on the scene of an accident - or a disaster? If you have a digital camera, and if both the PDA and camera had bluetooth, integrate the two so that you can easily combine the picture and 1000 words while they're fresh in your mind.
But what about the other end of things - aggregation and reading? Install AmphetaDesk along with, maybe, a web cache and spider that proactively slurps down new news items when it's near a firehose net connection. If you're in a town with frequent dips into the bandwidth pool as you wander around, maybe you'll catch another BlogWalker in your referrers, linking to what you just posted. Meet up and have some coffee. Hell, become a smart mob with a few other BlogWalkers.
Eh, I think I'm starting to ramble and get carried away, but in between reading VernorVinge and RayKurzweil books lately, I'm in a mood to immanentize the eschaton and tinker my way on into the Singularity.
(And, oh yeah, I'm in a pretentiously linky mood. (And could that be a valid mood in these days?))
[ ... 931 words ... ]
John Robb says:Damn. I have 95% of my PC's processer available at any given moment. In a year that will probably be 98%, in three years it will be 99%. This model of the Internet is so messed up. The fact that over 90% of the computing horsepower on the Internet sits idle at any given moment is insane (in fact, 98% of my DSL connection is dead too). It is going to change. It has to change....
Exactly. This one of the main reasons I don't think I want to run a "LiveJournal done right, according to me" site. I'd rather help build a decentralized mutant spawn of LJ, Radio, Gnutella, JXTA, and other things I've yet to realize I should be looking at. I really need to get some time this Winter to research, think, write, and tinker.
And the thing John says about everyone converting to notebooks is dead on for me. I haven't touched my desktop in ages. My iBook is becoming more and more my primary computing device. When I first got it, I thought it would be a satellite. Instead, all my other computers have become peripherals for it - extra storage, little daemon processes, all serving me via my laptop. Now I just need an excuse to go get myself a ?TiBook :)
[ ... 411 words ... ]
Dave says about adding namespaces to RSS v0.94: Could peace possibly be that simple? Could RSS 0.94 be the format everyone agrees to go forward on? If not, how long would a 0.95 take to get in place?
I say: Go, man, go! And then, time permitting, weave some nice hooks into Radio's aggregator to let us make Tools that register to handle the intrepretation/display of a namespace's tags.
I'd like to play with some more RDF eventually, but I don't know that RSS is the place. The thing that I really like are the namespaces and the possibility to throw plugins into aggregators to handle alien elements.
[ ... 108 words ... ]
On the hypothetical RSS 2.0, Mark Pilgrim says:A basic RSS 2.0 document is no more complicated to learn (or type by hand) than a basic RSS 0.9x document, and a complex RSS 2.0 document can be just as metadata-rich as a complex RSS 1.0 document.
Great - I love it - let's go! If Rael already mocked this up many moons ago, why hasn't it been adopted?
What's the catch? I just snatched Mark's RSS 2.0 draft template for MT and tossed it into my config. Try out my 0xDECAFBAD feed in the RSS 2.0 draft format and tell me what part of it burns down your house or frightens the children.
[ ... 138 words ... ]
Got an email today from David F. Gallagher with regards to my pondering why LiveJournal seems largely ignored. He pointed me to his new article about LiveJournal in the NY Times: "A Site to Pour Out Emotions, and Just About Anything Else"
All in all, it seems a good article for which the right amount of homework had been done. Good exposure for LJ, yay! It also again answers my question in the same way a lot of you who responded to my first post did: It's the culture, stupid.
I also just noticed a referrer from over at Radio Free Blogistan that echo much of what I've been thinking: What's interesting is that feature-by-feature, LJ's functionality is comparable to or better than that of most other tools. The difference seems to come more from how the tool tends to be used than from its inherent capabilties. I wonder if having the word "journal" in the name (see also diaryland) tends to promote the more diaristic uses of application?
See, I think my problem is this: In a lot of ways, LiveJournal is my old neighborhood. My first successful attempt at semi-sustained online narrative happened there, so much of what I consider a part of the experience comes from LJ. Now, 0xDECAFBAD is my attempt to get a foot into the bigger neighboor out here. But ever since I stepped foot out of LiveJournal, I've been trying to figure out ways to bring things I miss from in there to out here.
In one of my quickies from yesterday, I vaguely mentioned maybe launching a LiveJournal-based site whose explicit goal is to be more outward-facing to the blogosphere, and to be more blogish than journal-like. I think a site like this would be a good idea, maybe.
But... here are my problems with being the guy to launch that site:I like making and breaking toys, not taking care of and feeding them.Unless you pay me a lot and then don't bother me at all, I don't want to host your junk. :)I've been wanting to see journals & blogs more decentrallized, to avoid the growing pains that LiveJournal has.
In short, I've seen what trouble the LiveJournal team have gone through, and I'm not all that interested. Besides, I think that a decentrallized solution could all but erase the maintenance side of things, if everyone's responsible for their own personal servers. Maybe a pipe dream, but it's the only one that I think will eventually work.
Hmm.. have to think some more, but must get back to work now.
[ ... 428 words ... ]
Et tu Dave?
I'm mostly in catch-up mode on the hubbub surrounding RSS, so I can't say much other than that I like both flavors though I prefer the RDF approach best. But... it's strange reading about UserLand's abandoned trademark application for RSS.
Chimera rocks my socks:
Mark Pilgrim likes Chimera. Personally, I've been using it as my primary browser for about 5 weeks now, and update to the latest nightly every few days. I had a glitch or two, but it's come light years from when I first started playing with it and it already seems to leave Mozilla-proper in the dust.
Caffinated scraping:
I've been cobbling together an (X)HTML-to-RSS scraper using what I've learned of Java, XSLT, and XPath lately. I've been tempted to slap together an aggregator of my own, too, but no: AmphetaDesk has not made me itchy enough to do it. The scraper might be of some use to someone though.
Strange connectivity urges:
I've been having these strange urges lately to start playing with P2P-ish things again and build a collection of rendevous that piggyback on a number of existing infrastructures (ie. IRC, IM, NNTP, email, etc). I want to get back on the path of investigating complete decentralization, or at least some robust thing which lies in between. At the very least, though, I want to start doing some sort of IM-RPCish thing between behind-firewall PCs. And this Jabber server I just installed on my new JohnCompanies system should be nice. (It's at jabber.decafbad.com)
Soaking in LiveJournal:
Blessed be, I need help: I've convinced them at work to let me pilot a weblog/journal system on our intranet - and I've started by installing the LiveJournal source.
I've also installed LJ here on my new server from JohnCompanies, but I'm not quite sure what I want to do with it beyond tweaking and personal hacking. I've been musing at possibly enhancing some bits - particularly with regards to RSS syndication and aggregation, maybe some backlink tracking.
Maybe I'll polish the thing up a bit and offer it up as a sister to LJ where the 15-year-olds will not reign and reciprocal connections with the outside world are encouraged and facilitated. Would any of you pay for something like that?
This seems pretty ambitious, and it's likely I'll never do it, but hey.
And on other fronts:
Still in the underworld with Java, trying to get this project dragged past the finish line. Jaguar rocks and I took my girlfriend to the Apple Store opening in Novi, MI; we didn't buy anything, though it was close. There's a second Apple Store opening in my area in Troy, MI; the danger has not passed. And finally, I have succumbed lately to playing Grand Theft Auto 3 and it has affected my driving and given me pedestrian-smacking instincts to subdue while walking around town.
That is all. For now.
[ ... 591 words ... ]
Hmm, just read that Charles Nadeau released an XML-RPC to NNTP gateway. I still think it would be neat to have an NNTP to XML-RPC gateway to use as a wonky, distributedish message queue.
[ ... 298 words ... ]
So I took the plunge and snagged a FreeBSD "colocation" account with JohnCompanies, to address my desire for more experimental freedom on a server hosted Somewhere Out There. I may eventually hook up with a few fellow hackers to spread the monthly rent, and I may even consider floating some trial balloon for-pay services - assuming I hack together something I'm presumptious enough to think is worth money. :) But for now, the cost is very affordable for what I get.
So, I haven't dumped my current webhost yet, but I'm slowly going about installing services and software up there, including but not limited to: Apache, mod_perl, PHP4, Tomcat, Jabber, INNd, IRCd and whatever else seems like a good idea (whether or not it actually is a good idea). I might even throw a LiveJournal installation up there.
And, once I come to my senses, I may pare this list down and disable things until I get around to actually doing real things with them. More soon, I hope.
[ ... 489 words ... ]
Caught this snippet on tweeney.com via JOHO: "...LiveJournal.com (which most weblog news stories overlook for some reason) boasts more than 650,000 [users]..."
Why does everyone seem to ignore LiveJournal? It's very, very, very rare that I see a LiveJournaller's posts linked into the Blogosphere at large. Granted, I know that the median user was a 15 year old female who complains about Mom and her boyfriend, when last I checked. But, as the adage goes: 90% of anything is crap. There are, nevertheless, a good number of worthwhile streams of narrative in that space.
On the other hand, I don't see many of the people behind LJ stepping out and making noise in the Outer Blogosphere either. I think many of them are just plain busy keeping the site afloat, or having lives, and LJ is world enough for them.
But 650,000 users... that's a lot. More than Radio and rivalling Blogger.com. Is there a real qualitative difference in writing between the groups? I would still imagine there's a lot of crap to be found via Blogger.com. I'm not sure about Radio, though, since I get the impression that the 15 year olds have yet to flood into the userbase and its following seems more tilted toward professionals.
But as for the software & service itself... As far as I can see, LJ is one of the easiest paths out there to starting a weblog/journal online. And it was one of the first sites I ever encountered that had a desktop-based client app for posting to it. And, though not prominently placed, they have RSS feeds for every single journal on the site. They're even working RSS aggregation features into the place by gatewaying external RSS feeds in as special LJ users to be added like any other LJ "friend".
So, to me, LJ sounds like a top competitor to every other blog/news aggregation product or service out there - yet I rarely hear about it. Hrm.
Anyone have a theory why?
[ ... 1126 words ... ]
Even more gas is flowing - from andersja's blog: Movable Type notifications to Instant Messenger?
I really want to see this, and I want to see news aggregators exploit this - why poll a feed once an hour when you can just have the feed tell you to come 'n get it? Basic publish/subscribe model.
But the advantage Radio has over MT in this regard is this: Radio is a persistently running app/server/daemon thing. MT is a collection of scripts that does nothing until asked to run. Radio can connect to IM and stay connected. Something like MT would need to login to an IM service each and every time it wanted to ping. Maybe that's not such a big deal, really. I also have a hunch that there would be some difficulties with web hosting sites who don't really want customers emitting IMs from their CGIs. Maybe not a big deal either.
Just seems like an impedance mismatch, though.
What I'd like to see is something like this: An XML-RPC/SOAP <-> IM gateway. And then, eventually, I'd like to see a decentrallized P2P network with XML-RPC/SOAP entry points that can smoothly replace centralized resources that have XML-RPC/SOAP entry points, maybe using IM networks as one possible rendevous point. (Just remembered this project: JXTA Bridge. Mental note - play with JXTA again and poke at SOAP some more.)
[ ... 483 words ... ]
Dave writes, "I have my instant outliner going again."
Kick. Ass. Now we're cooking with gas. I think I need to get a fresh install of Radio going on this iBook again, especially since it seems renice works now and can tame the CPU hungry beast to managable levels. I was kinda waiting to see if/when the people hacking with IM in Radio would close this loop. Now I want to see what this can do to news aggregation, pub/sub, change notification, etc and more.
[ ... 86 words ... ]
Sam Ruby responds to Dave's question:I am not a stakeholder in this naming issue, nor can I claim based on personal experience that any of the above references are authoritative, but based on these references alone, it seems to me that one could ask the converse to both of these questions: i.e, why is RSS 0.91 called RSS, and why did the RSS 0.91 branch use instead of [rdf:rdf]?
This is basically what I'd started writing as a response the other night, but I lost it in a browser crash.
I browsed around a bit, revisited some old links I'd followed when first I started hacking with RSS and frustratedly discovered the format fork. As Dave tells it, his adoption of RSS started in cooperation with Netscape, and the later resulted in his continued support and development after Netscape had wandered away from it and shed the developers responsible. So from his seat I would think that it looks like RSS was abandoned in his lap and thus he felt free to continue on shaping it toward his own ends, namely those of simplicity and real dirt-under-the-nails use versus further design and planning.
Then, later RSS 1.0 comes into the picture. About this point in history I'm fuzzy. Most accounts and articles I see do not mention how v1.0 came about and who birthed it. Most of what I've ready just basically says, "And then there was v1.0" But who said so and when and why?
That 1.0 has more in common with the v0.9 roots than any of Dave's v0.9x series is clear, so maybe in this respect one could say that this naturally lends v1.0 a "natural" claim on the name by virtue of bloodline and original intent.
On the other hand, one could also say that Dave's v0.9x series has a claim on the name due to virtue of having actually been in active development directly after the original v0.9. Call this a claim by virtue of squatting rights? By virtue of principles of Do-ocracy, as Sam wrote about Apache?
But then, on another set of hands belonging to another body altogether, why did Dave keep the RSS name if he was so radically changing the nature of the format by ditching RDF? (But the history confuses me - I seem to remember that change started when it was still in the hands of Netscape.)
So where does that leave things? Ugh. Seems like Dave's RSS should be so because he kept the torch burning in the Dark Times. But it seems like the Other RSS should be so because it's the heir to the original throne.
Then again, I could have the whole history mixed up.
I say, everybody get up! I'll start the music, you all run around, and pick new format names before I hit stop on the CD player.
[ ... 547 words ... ]
...that's what's got me so bothered about people musing in their weblogs about projects they'd like to do. Stop talking about it an just build it. Don't make it too complicated. Don't spend so much time planning on events that will never happen. Programmers, good programmers, are known for over-engineering to save time later down the road. The problem is that you can over-engineer yourself out of wanting to do the site... [Andre Torrez, Even You Can Do It]
Just found this post today, via Danny O'Brien. This is why I threw this site together, and why I have a link to ReleaseEarlyReleaseOften on the front page.
Before this, I would spend years working on something in silence, only to have it fall over on top of me and end with me never wanting to touch it again. For almost 2 years, I was working on a Zope replacement in Perl called Iaido before I finally created a ?SourceForge project for it and invited some people in to play. By then, I was already disgusted with my ugly code, wanted to scrap it and restart, but wasn't nearly enthusiastic enough to do that. And by then, there was just too much code - and yet too little documentation - for anyone I invited in to really dive in and muck about.
And this project was to be the core of a community site for coders, web designers, and general all around mad scientists. It would be named ?NinjaCode, at http://www.ninjacode.com. Well, you can see, the community never got off the ground, and I don't even have a hold on the domain anymore. It coulda been a contenda.
But you can see now, on my Projects page, that I've been gradually working up and spinning out little hacks and widgets. Eventually, they combine into bigger widgets, like MTXmlRpcFilterPlugin. I'm thinking that this is the way to go. And, even if/when I do get a grandiose idea, I need to start off releasing the widgets early and show the build up process here in this weblog. Then, there's some documentation from the start and maybe even some enthusiastic co-conspirators from the start.
[ ... 425 words ... ]
D'oh. Just realized that the download link for the fixed AmphetaOutlines was at the bottom of the page, so I was puzzled that I kept getting emails about it doing the same broken things. I seem to be missing many things lately. :)
Anyway, the correct download is here:
AmphetaOutlines-20020822.tar.gz:
This should include the corrected "URL=" redirect.
[ ... 76 words ... ]
Well, that sucked. I managed to get an all but complete dump of my comments.db file with db_dump on my server, but then nothing would parse or load that file after that. Banged around with it for awhile until I finally realized how to parse the dump file myself with a perl one-liner and rebuilt the comments DBM file that way.
Immediately after that, I migrated everything to MySQL. Not a silver bullet, but it seems a better idea than relying on those DBM files. They seemed neat & clever at first - but now that I have a bit invested here, they're an annoyance.
I think I managed to recover the last few comments I got while things went wonky, but if I happened to miss one of yours, I'm sorry. I'm glad I recovered the comments, though, because I tend to think that comments left here are often more valuable than whatever dross I may have spewed in the first place.
[ ... 164 words ... ]
Grr again. As a few of you have told me in email, and as I noticed toward the end of yesterday, my comments feature here is dead. Seems that as the disk filled up on this server, someone tried leaving a comment, and as Murphy came into play, the comments DB file got corrupted. The odd thing, and fortunate thing for me anyway, is that I'm still getting the comments emailled to me. So if/when I get this DB file recovered, or if I wipe it and start over (not happy about that option), I might try re-posting the comments.
Got some good pointers on some hosting options and may be checking out one or another of them soon. Also looks like there are still issues with my AmphetaOutlines, even after a re-release.
More soon.
[ ... 136 words ... ]
A few words of warning, which should be pretty obvious, with regard to MTXmlRpcFilterPlugin use: Every appearance of the tag makes a separate web service call. This could be painful if you stick it in your individual archive item template, and then rebuild your site. (ie. at least one hit on the filter service for each item in your weblog) :)
[ ... 62 words ... ]
Ack! I just realized, even though it took two emails make the light go on, that my tarball of AmphetaOutlines for download in the wiki has still had the broken click-count page bundled for the last month or so. For some reason I thought that I'd fixed that and re-uploaded the tarball, but no!
So: It's there now, hopefully this is a fix for any of you who tried it and saw the insane refresh loop happen with you clicked on a news item. Hop on over to AmphetaOutlines and grab yourself a new copy.
Next... I screw around with Bayesian filters as applied to incoming news items, categories of interest, and alert levels. Maybe.
[ ... 288 words ... ]
Grr, shame on me for getting cheap hosting again. For the most part, PHPWebHosting has been just fine - they give me SSH access to a shell, about 120MB of space, a few MySQL databases, and generally leave me alone for US$10 per month. But at this point, the leaving me alone bit isn't working out so well, since the server I'm on over there has had its main disk fill up regularly, thus bringing down all the sites hosted on it (including mine).
I'd joked a little while ago about getting myself an XServe and finding some affordable colocation. Now, though, I'm not laughing so much. I should probably just find another webhost, but it's tempting to have my own server.
In the past, I had a few friends at an ISP, so they let me stash a little linux server on their network for occasional favors. I miss that. Didn't cost me anything, and my impact on their network was negligible. Meanwhile, I had a stable, semi-reliable box on the net at which I could point a domain. Services could catch fire and other things could tank, and no one got hurt.
The problem now, though, is that shelling out for a server and colocation costs just to play around is a just a smidgen outside my budget. As I've pondered before, maybe I could actually host a money-making service on it with some of these hacks I'm percolating through.
On the other hand, a co-worker put the idea in my head that it might not be unreasonable to think that I could invite some tenants onto my server to share some of the cost. I figure I'd take the burden of buying & owning the server, but I'd like to spread the service cost out. I wouldn't want to make a profit, I'd just like to make a kind of nerd commune. It'd be nice if I could get the cost for everyone under US$10-15, though I imagine my cost would be higher given a server payment. If I could get mine below $40-50 a month, I think I'd be happy, though this seems like a pipe dream.
The devil being in the details, however, I don't really know how one would go about such a thing, considering service agreements and contracts and taxes and blah blah blah. I'm a financial moron, and I'm also certainly not into being a 24/7 available customer service rep, or to perform tech help. Basically, I'd like to run a server to host mad scientist experiments performed by a relatively small cadre of mad scientists who can mostly clean up after themselves. I'd like to run an IRC server, maybe a Jabber server, maybe a few random half-baked server ideas.
On the other other hand, is anyone out there doing this already and want a new tenant? :)
[ ... 821 words ... ]
Yikes. I think that was the longest entry I've posted here - I usually reserve my rants, opinion posts, and various longer prose for my LiveJournal. Maybe I'll actually start showing a little more personality around these parts too. :)
[ ... 41 words ... ]
Scanning news today, I see in my referrers a link from the new aggregators discussion group to my outliner AmphetaDesk skin. Curious, I go check it out and see what looks like a bit of grumbling between Dave Winer and Morbus Iff. I make my way back to near the head of the thread to see what's what, where I find a link to Morbus' post of opinioned and somewhat ranty disagreement toward Dave's definition of the modern News Aggregator. What disturbs me is that the grumbling quickly ends with:Bill -- I'm going to unsubscribe from this list now. The neener boys are in charge. Take care. Dave
Now first of all, I too disagree with Dave's definition, and have posted as much. Although I did so in a less rant-mode manner, both Morbus and I pointed to the fact that the news aggregator definition served the goals of Radio 8.0 marketing, being that the definition very specifically identified the features of his own product. Rant or not, the point is made.
What disappoints me about Dave's response on-list, though, is that instead of addressing the content of the disagreement, he goes after the ranting and hits back with a smidgen of ad-hominem of his own while calling for the "high road". Then, once he's tagged on the ad-hominem he unsubscribes and dismisses the list altogether, never actually acknowledging the original point made.
Now, though I don't have a link, I've read several times where Dave has disparaged discussion groups and offered linked weblogs as the superior alternative. I've read his essay on Stop Energy. I'm aware of his position toward the grousings and grumblings and flamings that go on within a discussion group. And I've nodded my head almost every time he's written about these things - freeform discussions on the net can sometimes - but not always - be a clusterfuck of morons and Stop Energy.
Maybe it's just because Dave is so intolerably fed up with any hint of a clusterfuck that he dropped off the list. I wouldn't put up with much shit either, especially after heart surgery. But to me it looked like pretty defensive behavior right from the get-go. Morbus even gave somewhat of an apology (for him :) ) and moved on to politely hit the issues.
I guess this bugs me a bit, along with other UserLand-related thoughts I've had lately, for this reason: Here's a discussion group devoted to the very nature and future of one of the headline features of RadioUserLand. And the people there are some of the most prevalent names I've seen appear time and time again in relation ot the subject. I would think that this would be a dream group for him, in terms of driving and benefiting from innovation. Instead, it takes only a small amount of rant to drive him away.
See, I've never met him, but I think I'd like Dave personally. Yes, I know his writings often have one foot or both feet in marketing for his products. But, I can't recall his denying this, and I see it as the natural behavior of someone who really thinks he's got something hot. He gives favor to his customers in his posts, and he has his own opinions. But I know these things, and I still like his software, and I still buy it.
On the other hand, it's clear that sometimes he doesn't give equal time to points which may be contradictory or unfavorable to his side of things, and sometimes he gets things wrong. But he's not a journallist - he's a blogger who writes from the hip and sees what flies. Whether he lies outright is another story I haven't the first inclination to follow up on, but the very nature of his product stands to check and balance to him there. He can't get away with too much with his own customers calling him on things.
Anyway, I'm starting to ramble. What really bothers me about the quick dismissal of the list seems like a "See?! This is what I mean!" demonstration on-list, and I almost expect a post later again promoting weblogs over DG's altogether. But I didn't even see him give the list a chance, and I think that's sad given the brain power in that roster. Granted, it's his perogative to have slim thresholds for annoyance, but I'd think this would be value for his company and product. As I said, I like his software, but he's refusing free help and consultation on the future of his product. I see those involved in groups like this taking their products beyond his, even those that were originally direct clones of his. Maybe this ends up tying into his grousing on Open Source versus commercial software eventually.
On the other hand, maybe he just thinks he doesn't need any help of this sort and has the sheer magnitude of innovational mojo to leave us all in the dust. If so, rock on. :) As for me, I just joined the list.
[ ... 988 words ... ]
Quick mental notes:
Ditch the blogroll or make better efforts at updating it.
Publish my news aggregator subscription list in addition to, or instead of the blogroll.
Examine referrer records for readers of my RSS feed to find readers of whom I'm unaware.
Visit all the sites listed under my stats at the blogging ecosystem site.
Write more, both here, and over at LiveJournal. Possibly revive The Spirit of Radio and my RadioUserLand hacking efforts. (ie. Make Radio run blog entries through my Wiki filter)
Reskin this place, simplify and make accessible and less ugly. Reduce number of toys, or at least give them all off switches.
Get back to work.
[ ... 112 words ... ]
Well, it looks like Josh Cooper has gotten the MTXmlRpcFilterPlugin and XmlRpcToWiki working on his blog. Yay hooray!
Now, I just have to see about improving this thing if I can, and to make this place look better. This sudden easy abundance of links makes me think that they draw too much attention from the surrounding text. This is desirable, but not to the degree that they do now.
[ ... 70 words ... ]
This ISP has the right idea: treat the RIAA hacking threat like any other hacking threat. Let's see how long before this is made illegal. In the meantime, I'm trying to come up with a way to convince myself that it's worth buying an XServe and colocating with them. But first, I've got to come up with a business model to make some money to afford the toys. :) This will likely never happen.
[ ... 75 words ... ]
Last week, after reading what Mark Pilgrim had to say about macros in MovableType, I made a mental note to finally circle back around to hacking together my WeblogWithWiki now that MovableType has plugin features.
Turns out it was so much easier than I thought it would be. MovableType's plugin scheme is dead simple, which hopefully means that plugins will flourish like mad.
First, I hacked together MTWikiFormatPlugin. This plugin simply implements a new container tag, MTWikiFormat, which runs the contents of the tag through CPAN:Text::WikiFormat. This doesn't actually integrate with any existing wiki, but it is very simple to install and does bring some wiki-ness to blog entries, including some limited formatting and Wiki:WikiWords. This doesn't provide everything Mark had posted in a lil wishlist comment to me, but it's a start. Maybe I'll look into tearing the formatting guts out of some wiki to make a Text::WikiFormat replacement, or maybe I'll submit patches to the original module.
The second plugin though, MTXmlRpcFilterPlugin, is what I'm really happy about.
Whereas MTWikiFormatPlugin filters content through one perl module, MTXmlRpcFilterPlugin can filter content through one or more XmlRpcFilteringPipe interfaces. I have a handful of these filters available on my site right now, and in a little while I will catalog them in the wiki. For now, I'm just filtering this entry through DecafbadWiki. In the future, I may get more adventurous with my content filtering pipeline.
One drawback to using MTXmlRpcFilterPlugin for the purposes of a WeblogWithWiki is that I've only got support for TWiki so far in my XmlRpcToWiki project. Other wikis still need some hacking before they can provide filters. Some assembly required, fellow AlphaGeeks.
So, ShareAndEnjoy. Time for bed.
[ ... 1317 words ... ]
Please excuse the noise and dust - I'm working on a few new MT plugins to support Wiki formatting and XmlRpcFilteringPipe. Are these wiki words working? PipeFilters, MovableType, ShareAndEnjoy, etc.
How about unordered lists?
* One
* Two
* Three
How about ordered lists?
1. One
2. Two
3. Three
And ''how'' '''about''' '''''this'''''?
This is another test. PipeFilters, ShareAndEnjoy.
One
One a
two
three
four
two a
How about a table?
this is a
test table format
[ ... 166 words ... ]
Just read this on Scripting News:Heads-up, some time in the next few hours (Murphy-willing) we're going to release tcp.im, which allows Radio and Frontier to be an instant messaging client or server (either can be either).
Okay, this is insanely great, or at least has gigantic potential to be great. I just hope ActiveBuddy doesn't swoop in and claim to have invented the whole kit and kaboodle. Barring that, I can see a whole suite of new P2P apps with desktop servers, kicked off by the UserLand crowd.
This makes me want to find a decent machine for Radio to run on and give it a fair amount of attention again. I wish it weren't so demanding of my poor iBook. But I do need excuses to convince myself to invest in a new ?TiBook...
[ ... 135 words ... ]
Do not stand in our way - we will walk around you.
Spam is in our way.
We will use the inhuman aspects inherent to your sales pitch to walk around you.
Cluetrain on statistic-driven autopilot. :)
[ ... 186 words ... ]
Further self-directed dot connection via Sam Ruby:I talked Sanjiva Weerawarana into creating a Radio weblog. He's one of the driving forces behind many important Web services standards including WSDL and BPEL4WS.
Welcome to the Blogosphere, Sanjiva! :)
[ ... 37 words ... ]
I just read about ChoiceMail, a whitelist-based email service that "turns your inbox into the equivalent of your front door" where people have to knock and identify themselves as human via a quick web form (hello, Cluetrain) before their message is allowed in. This is exactly the idea I've been tossing around in my head and reading about for some time now.
I would pay for this service in an instant, but unfortunately it apparently requires Windows. So, I just got SpamAssassin and Razor working on home IMAP server, so I think I might just poke at finally implementing a service like ?ChoiceMail on my own. Hell, maybe I'll even have it send me Jabber messages for permission confirmation and accept messages for whitelist additions, but keeping everything in the context of email seems better.
[ ... 344 words ... ]
Another reason why I need to poke around at Java Web Start development, found via the rebelutionary: jlGui, a 100% Java music player that looks great, seems to work nicely, and launched right from my Mac's JWS panel.
[ ... 67 words ... ]
Sam Ruby helped in connecting the dots between me and someone responsible for my recent Bean Markup Language obsession. Thanks Sam! :)
[ ... 23 words ... ]
Better living through regular expressions from Mark Pilgrim. This has got me thinking of two things:I need to hack together some MT macros or a plugin that finds & links wiki-words in blog entries to my wiki, and I need to start writing in the wiki again.I really dig his blog's skin, and I need to finally read though all of his accessibility tips and re-skin this site. This place is butt-ugly.
[ ... 288 words ... ]
Wow, that was fast. I got a direct response from one of the two original creators of BML, Sanjiva Weerawarana:...I still believe BML has a useful role in life. We still have some of our original trusty users who periodically email us asking for status / updates etc..
What's the right thing to do? I am quite certain that we can get it open-sourced (I mean from an IBM process point of view), but I haven't yet been convinced that there'd be a willing community for it yet.
This tells me that there's still some life left in the project, so I certainly won't be running off to release my unauthorized decompilation. Besides respect of ownership and authorship, it'd be nice to see a sanctioned release of the real code, comments and all.
Sanjiva asks what to do and who wants it. I say: Gimme, and I want it! But of course there's more, in terms of effort and consideration, to an Open Source project than that. So, where's the interest (besides me) to make it worth doing?
I'm not sure. Seems very nifty to me, but again, I see barely a mention on Google. But, I look at Thinlet buzz that recently bubbled through my news scan, with raves about the XML wiring for GUI and quickness in assembling apps. It's very cool. And then I wonder how cool might it be to combine the two, or use BML instead of Thinlet.
Is the lack of interest a product of a lack of word getting out? Or, again, have I missed something in my return to the world of Java?
[ ... 418 words ... ]
Hmm... The plot thickens a bit for me with regard to the Bean Markup Language project. On a whim, I Google'd for a Java decompiler, having remembered that I'd gotten some use and enlightenment back in the day from Mocha. So I found, downloaded, and tried Mocha on the BML class files. It choked a bit, produced some source files, but the collection as a whole was not trivially easy to recompile. Pretty much what I expected, given that Mocha is a relic these days.
But then, I noticed JODE, a few search results down the page. Google's description said, "Java decompiler with full source code. Supports inner/anonymous classes..." Well, inner/anonymous classes are new to me since I was last very active with Java. (Yes, I know, that's been awhile.) So I figured I'd check JODE out. Besides, the last release of JODE looked newer than the last release of BML.
Much to my surprise, JODE consumed the BML jar file directly and gave me a directory full of source without a complaint. For the hell of it, I compiled everything there, and made a new jar file from the results. I cleaned my project out, replaced the original BML jar with my new decompiled-recompiled archive and... everything worked just fine.
Skimming through the various source files JODE gave me, things look surprisingly less ugly than I'd expected. Of course comments are nowhere to be seen, and variable names are nothing like the original would have been, but the source was is still readable and I can follow it. So this means I have the source code to BML now, after a fashion.
So my question now is... I read the IBM ALPHAWORKS COMMERCIAL LICENSE AGREEMENT which came with the original download, and I see these paragraphs:Permission to reproduce and create derivative works from the Software ("Software Derivative Works") is hereby granted to you under the copyrights of International Business Machines Corporation ("IBM"). IBM also grants you the right to distribute the Software and Software Derivative Works.
You grant IBM a world-wide, royalty-free right to use, copy, distribute, sublicense and prepare derivative works based upon any feedback, including materials, error corrections, Software Derivatives, enhancements, suggestions and the like that you provide to IBM relating to the Software.
Does this mean, basically, that it's okay for me to distribute this source as a derivative work, with various potential enhancements, &etc, as long as IBM is still able to grab a copy of it back from me with no strings attached? If so, that's great.
My only other question remaining, though, is whether or not my naivete toward Java has me yet to find what the community at large considers the Right Way to work with ?JavaBeans. Because, this BML thing seems great to me, but it seems to have gotten next to zero attention. This usually tells me that I'm missing something, but the thing itself works nicely.
Any thoughts out there in the blogosphere?
[ ... 494 words ... ]
Ack. Okay, so I started tinkering with Bean Markup Language as the configuration glue for my Java app. So far it seems to be working very nicely and doing everything I want it to do. The problem, though, is that as I look around for examples and things I notice that it seems as if this project is dead. I look further, and I realize... I can't find any source code to this thing. And here I am working it into the core of my app.
Well, I'd hate to start over and reinvent this wheel, since it seems to be such a nice wheel. Between the clean definition of beans and their properties, and the ability to toss little bits of script (using the BSF) in there to further tweak things, it seems perfect. But the apparent abandonment of the project and my lack of source gives me the willies.
So... Does anyone out there know anything about what's happened with the Bean Markup Language project? Could anyone get me the source? Or, could someone point me to an equivalent alternative? Because, if I can't find source or an equally powerful alternative, I'm tossing around the notion of re-implementing BML with a clone project if the license doesn't prohibit it.
Or am I completely crazy and barking up the wrong tree to begin with? Is there a better, more elegant way to create and connect Java components together than this? And is it free?
[ ... 945 words ... ]
So I've been in the underworld these past weeks, head down in battle with this project in my return to Java, as I'd written last month. It's been great fun, and I've not missed perl at all along the way. (Although, I did miss CPAN.) I've raided the stocks of Jakarta and other shores, and I've flagged a few new people to watch on my daily scan.
These past 4 weeks or so, it's amazing to me during how many new or long-neglected (to me) technologies at which I've thrown myself, and managed to use productively. Among them are XML, Xerces, XSLT, XPath, Xalan, SVG, Batik, Xindice, JUnit, Log4J, Ant, BML, BSF, BeanShell, NetBeans, and a slew of others my poor sore brain won't produce at the moment. I've plucked each of these from the ether and carefully tied them all together into a loosely confederated beast that, surprisingly, works as I'd intended thus far.
My biggest regret during this voyage is that this beast will likely never roam beyond the fences of my employer's realm. But, I still have the new experience with building the beast. And besides, you'd probably all laugh at the poor thing anyway since its the product of wobbling new steps. Though, actually, that would be a good thing for my company and myself since some of you might tell me why you're laughing.
But, no matter - that's a political fight I'm not yet prepared to enter here at work, so maybe I can think of other things with which to tinker, out here in the open.
The Java support in OS X makes me very happy, as does having Java Web Start come installed out of the box. And so, today I was also happy when I saw ThinRSS and managed to launch it with a click. I'd been musing about maybe doing a news aggregator in Java, but AmphetaDesk works fine and I've got some hack time invested in the fun outliner skin. But this really makes me want to do something with Thinlet. Possibilities abound.
I've also started toying with an XPath-to-RSS scraper to replace my ?RssDistiller usage. I know that there's a Python-based one out there, xpath2rss, but I've yet to quite figure it out and I feel like tinkering on my own anyway. So far I've pulled in JTidy, Xalan, Xerces, and JUnit to help. Amazingly, to me, everything seems to be working pretty well.
Anyway, back to the day's work, but I figured I'd ramble a bit and share my recent fun since I've been largely quiet around here. Hopefully I'll be back soon with updates to the AmphetaDesk outline skin, and with a new toy scraper project.
[ ... 451 words ... ]
When I see links in my referrers like this from Niutopia, it makes me wish I had translator microbes instead of the Babelfish. But, at least I have the Fish, and for free! (Thanks ?AltaVista!) The translation is sketchy and random at best, but it's decent enough for me to get the gist of things. Now if only I could respond to things in a foriegn language and not accidentally start a war or insult someone's relations, or at best sound like a moron. It is nice, though, to be reminded that English is not the only language of the web.
[ ... 269 words ... ]
So are any of you guys getting itchy? I've had a great Summer all around, but without much hacking or progress on little projects. And I've noticed that there's been relative quiet and little hacking amongst my reading list's authors. Could be that I'm just not looking in the right places - I did lose a few subscriptions in my bounce from Radio to Ampheta for daily use. But I just don't see as many daily innovations as I did toward the end of Winter and beginning of Spring.
As for me, as the nights get longer and things get colder, I'm starting to feel an itch to start tinkering again. Maybe it has to do with not-yet-dead back-to-school reflexes - summer vacation's over, and its time to get back to learning and experimenting. Starting to look again at my neglected wiki, and of course I've started tinkering with my AmphetaDesk outliner skin again. I've also been thinking about my other little projects, referrer links, whitelist-based spam filtering, XML-RPC pipelines, and other things I've not touched in months.
The fact that I'd not felt like playing with these toys for so long worried me a bit, so the return of the itch is reassuring. So, I should get back to playing soon. And, now that my financial situation has greatly improved, I also need to figure out where to start and to whom I should talk on really heading back to school.
So Summer has been just a nice, long nap in a hammock. Time to start making the coffee. (Not decaf, of course.)
[ ... 316 words ... ]
At last: I had a good solid hacking session with the beast under WinXP, and I think I've flushed out the showstopper bugs. So, here's yet another release (hopefully zaro boogs) of the thing for you to grab and try:AmphetaOutlines-20020806-2.tar.gz
Thanks for bearing with me out there and not beating me about the head and shoulders. :) I mean, yes, it's free and its experimental... but it's still damn frustrating.
Basically, the trouble started when I tried to use "use lib". Seems like a reasonable enough request, lib.pm being very much a core part of perl. But, Morbus hadn't used it anywhere in AmphetaDesk, so Perl2EXE cheerfully left it out. Well, I had to hack by other means, since I wanted this thing to be as drop-in compatible with the current release of AmphetaDesk as possible.
And then, there were other bits I'd left out. And also there were the bits that I'd written at 3:30 am the other night and wasn't precisely sure what made it possible for them to actually work anywhere, let alone on my iBook. But, I think now I've got things under control.
It makes me appreciate the OS X environment so much more. OS X is like driving a nice big, fully packed RV that handles like a station wagon down the hacking highway. On the other hand, Windows is a Ford Festiva with a hole in the floorboards and a nagging suspicion that I forgot something back at the house. Okay, so that was a bit contrived. I just wanted to say something smarmy after all this grumbling. :)
Is this thing working for anyone yet?!
Update: In case you were wondering, this release should be usable via the original instructions back here. Which are, basically:Replace templates/default with this archive's contents.Create a directory named channels_meta in your data directory.Share and Enjoy
[ ... 1231 words ... ]
That'll teach me not to test on other platforms before I release :) It appears that Windows users are missing 'lib.pm' in their bundle of AmphetaDesk joy, which really perplexed me at first. So, if you've already downloaded my tarball from yesterday, download the following template and replace templates/default/index.html:ampheta-index-20020806.html
If you've yet to grab my initial release, grab this instead:AmphetaOutlines-20020806.tar.gz
This all seems to have worked on my machine at home, but that Windows machine also has a full Perl installation. I'm going to try everything out on my Virtual PC WinXP install here at work, but I seem to be having trouble downloading a copy of AmphetaDesk from ?SourceForge.
Let me know if you feel the love yet. :)
[ ... 262 words ... ]
Okay, after several comments, emails, IMs, and other encouragement, I stopped adding features and cleaned up a few things in my new AmphetaDesk template and have uploaded a tarball of it:AmphetaOutlines-20020806-2.tar.gz
Again, some highlights:Leaner template code on the server side, leaner HTML on the browser side.Ampheta remembers things about items now, such as # of clicks, age, and # of times seen.Ampheta can act on this memory, sorting and hiding items.Old, stale things tend to go away.Often used & visited things tend to come first.
To install this thing:Rename/backup the directory default in the templates directory of your AmphetaDesk installation.Replace that directory with the contents of the above-linked tarball.Create a directory named channels_meta in the data directory of your AmphetaDesk installation.Start AmphetaDesk, and let simmer for a few days to see things start workingThe thing's still a bit rough around the corners. To change thresholds and other settings, you'll need to edit default/index.html directly for now. I plan to add some fields to the settings page to manage these settings, eventually. Also, you really want to have the Digest::MD5 perl module installed, but I have included Digest::Perl::MD5 in the template. This means that things will work, but could be much faster. As for the outlines, give thanks to Marc Barrot for his activeRenderer package from which I borrowed nearly all of my outline code. (The only ?JavaScript that's mine is the expand/collapse all logic.)
Okay, I'm off to lunch. Let me know how you like it!
Update: It appears that some people are having problems with their AmphetaDesk failing to find the custom modules I include with the template. If you have trouble running the template, try copying the contents of templates/default/lib into the lib/ directory of your AmphetaDesk install.
Update 2: I think I've fixed the showstoppers, as I will write here in the future. So, I've taken the liberty of going back in time and replacing the tarball here with the fixed one in case anyone has linked to this story. Enjoy!
[ ... 490 words ... ]
So, I was happy to discover I'd gotten a link from Doc. But then, I was not not so happy to discover it was because I'm contributing to the downfall of his website due to popularity. Gah! The link, she is a double edged sword, and of course I only meant to point, not to prick or stab.
This makes me recall blog posts to the Open Content Network I'd seen awhile back. Sounds like a little bit of the HTTP Extensions for a Content-Addressable Web and Content Mirror Advertisement Specification voodoo magic would hit the spot here.
[ ... 176 words ... ]
Everyone else is linking to it, but this is beautiful:
Infrastructure: Why geeks build it, why Hollywood doesn't understand it, how business can take advantage of it. by Doc Searls, Co-author of The Cluetrain Manifesto
[ ... 36 words ... ]
So this past weekend, I wrote (thanks for the link, Jenny!) about continuing down the road of my experiments with news aggregation and the tweaks I've been doing to AmphetaDesk's interface. Well, I'm at it again. I'm debating whether to post what I have so far for download yet, since I'm still refining some things, but I will very soon. I've noticed that my first attempt gathered some fans, so you all might like what I'm adding now:Template code seems easier on memory usageMuch, much more sparing with tables, items are displayed using only DIV's and margin widths for indentation. (Seems to have saved a lot of memory.)Outliner javascript now uses the browser DOM exclusively. (Seems to be slimmer and faster.)Per-channel metadata annotation & storage - a feature already planned for Ampheta, but I was impatient and hacked a quick scheme together. (The future AmphetaDesk implementaiton will replace this.)A new interstitial redirect page via which links are visited, to count clicksIn the per-channel metadata, I track:Unique MD5 signatures for itemsDate-first-seen for itemsNumber of times an item has been shownNumber of times an item's link has been clickedItems clicked for the channel as a whole
Using the newly recorded metrics on channels and items, I do a few nifty things now:Item hiding thresholds can be set on # of appearences, # of clicks, and item age. Hidden items disappear behind an expandable outline handle.Channels and items can be sorted on # of clicks, age/last update, number of items shown.Channels with no shown items can be automatically collapsed.
The gist of all this:Channels and items I like and visit regularly tend to bubble toward the topStale channels and items tend to disappear and get demand less attention during my skim-and-scan.Hidden things are out of the way, but are still available within a click or two
After letting this run for a few days (since all items are new at the first run), I've noticed that my news scanning has gotten much faster, even with occasional checks to be sure I'm not really missing anything with my thresholds.
The reasons I haven't immediately uploaded it for all of you: No preferences for thresholds - I'm editing constants at the header of my template for now; dependancy on Perl modules that don't come with Ampheta - only a few, but I'd like to wean away from them. Oh, and it's also nasty code that I want to refactor into a bunch of subroutines, some of which will be factored out of the template and eventually replaced with calls to core AmphetaDesk code. (Too much logic in my template.)
I also want to add some "karma" features so that, beyond metrics of age, visits, and appearances, you can add your own manual rating and opinion to the process of sorting and show/hide. And then there's the idea of categories/playlists I want to steal from iTunes as well. But, I might just clean up what I have by this weekend and do the early release thing so you can all cheer or jeer it at will. I also need to drop back into the AmphetaDesk dev crowd. I miss those guys...
[ ... 614 words ... ]
So just a couple of weeks ago, I was laughing at Monday: (Their colon, not mine. They wouldn't like my colon.) The rebranding struck me as the last spastic hyper-hypo twitch of the 90s' super-high-energy-please-God-make-them-like-me theme. The Register, bless their souls, don't like Monday:'s either.
It reminds me of when one of my old employers tried rebranding themselves from a very lawyerly name (Wunderman Cato Johnson) to a suffix: ".ology" It would have been great, I heard. We would have been studies of everything: marketing.ology, analytics.ology, urinal-cake.ology.
Instead, at the last minute demand of an assumedly more rational high level muckety-muck, they dropped that and picked "Impiric (with a funny all-encompassing bracket)" at the last minute. They also tossed out months of work and research into positioning, presentations, and common corp speak. This new name, however, was to imply empirical knowledge of all our subjects - i.e. experience. A fun, hip way to spin the fact that we were all working for a practically ancient company in the computer age. I felt really bad for the team who had to jackknife their whole process, throw out their baby, and throw together a shitty last minute collection of branding consisting of a Fatboy Slim song ("Right Here, Right Now"), and a vaguely topical epileptic flashing stream of clip art images.
But then, after about two years of this crap, they decide they (kinda) liked their original name better, and wandered back to "Wunderman". Of course, it's worth noting that the "they" are probably the old guard who never wanted it changed in the first place and who are happy all the morons who thought "Impiric (funny all-encompassing bracket)" was a good name are out on the street now.
And, today, The Register tells me that IBM has put Monday: out of our misery by purchasing them. Monday: has now returned to the more respectable "PricewaterhouseCoopers Consulting", soon to become just "IBM". Thankfully, Monday:'s demise took about a month. Any longer, and I'd've been cringing at the day when we would have started pitching to them as a client.
Thing is, I loved the 90's. There were a lot of good things, even if many of them were all a "Who Shot J.R.?" dream. I'd like to see the genuine ingenuity and innovation survive. I'd also like to see all the fake raver-boy-wannabe marketing execs lined up and shot. And, it'd be neat to see us all try again at a "new economy", only this time let's start with real things that do real stuff for real people and make real money.
Hmm, which reminds me: I wish my company would rebrand, and drop the 'e'. It really doesn't do us justice since we survived the dot-com days with a real business model and solid products.
[ ... 465 words ... ]
From The Shifted Librarian:I am a media company's dream. I get the whole digital cable package, I love music and own hundreds of CDs, I frequently go to movie theaters, my study is lined with books, I like DVDs because of the extras and the quality of the picture, I attend plays, I like going to concerts, I take my media with me, and I've always wanted my MTV.
Ditto, on everything but the plays. (I really need to start getting out to the great performances in my area.) Here I am looking at ways to more effectively consume just the media I like, even to the point of building my own somewhat pricey entertainment-center PC to take care of DVR and radio recording functions. I really would pay someone to help me with this, and not screw with me after. And I really would rather pay for TV and radio, in return for zero-advertising (including product placement).
/me jumps and waves at the satellites. Hi up there. I'm one of your best customers. I have money. /me waves money. But you're not getting it unless you do what I want. Hmm.
Between Hollywood and my lovely government... were this back in the days of eyepatches and parrots, they'd've had the Seven Seas drained to catch the scurvy bastards and then wondered where all the spices went at dinner time.
[ ... 293 words ... ]
Oh, and one more thing: I assume you've seen the new iTunes. I want to steal the new features for my news aggregator. I'd been thinking of these things long before the new version came out, but of course these are not unique ideas. And how well they seem to work in iTunes now (for me at least) seems to be a good thing to point at and say "that's what I mean".
So... I want a count of how many times I "play" a channel (ie. visit a link or story from the RSS feed.) I want to rate my channels. I want to make "playlists" (ie. categories), and "smart playlists" (ie. active, persistent searches). I'd also like to synch my subscriptions and things with my website and.. hmm, well, no one's made an iPod analogue for news aggregation/reading yet. ...or have they?
So far, I've been sticking with AmphetaDesk and still using my crappy old bloated hog of an Ampheta outline template. (And I see that someone else has just mentioned it today. I really need to revisit it and make a bunch of sorely-needed improvements, space savings, and updates.)
I started playing with NetNewsWire a bit, and I think it's pretty keen. But, I don't have the source to tinker with, so I'm less interested. (No slight on the app, or the developer. You might love it. I'm just more D.I.Y.) So I was starting to think of coding up my own work-a-like in Java, but then I start thinking further: I don't think I can really learn to love a native-GUI web news aggregator, period. I think it's got to be web-based in some way. It's about context switching, in a way I think. If RSS channels had all of the content from the sites they describe, then maybe I could just twiddle around in the UI of the app... but I always end up in the browser. So... Why ever leave it?
So, back to Ampheta I go, I think. I just need to start hanging out on IRC more again. I keep doing vanishing acts.
[ ... 352 words ... ]
Yes, I'm still out here. Busy and occupied and A.W.O.L. from most of the communities in which I was squatting this Spring, but I want to wander back in. Maybe I can consider this a Summer break of sorts, assuming that I rejoin with feeling when the weather gets colder. Is this the experience for anyone else around here? That your play tech projects suffer in nicer seasons and weather, and your blogging frequency drops way down? I think this may be my cycle.
[ ... 85 words ... ]
Okay, I do this in what seems like an annual cycle: Juggle hardware and operating systems around on my home PCs. The tool I always seem to lose and need again is something to safely allow me to resize and move hard drive partitions, whether they be Linux or Windows. Has anyone finally made a reliable Open Source tool for this yet?
Generally, I reach for Partition Magic for the job. It's never failed for me. But, generally, I need to buy a new copy of it every time I get around to using it again. I mean, who really needs to repartition a drive more than a few times in a year? (Okay, you can put your hand down. You need to get out more.)
Well, this time it looks like I need it again. I have v6.0, which apparently makes WinXP choke and drown in its own vomit. I don't really want to buy Partition Magic again. Could I just rent your copy for about $10-20 or so? I've considered wiping WinXP and re-installing Win98 just because things seemed easier then. It just seems like this is such a common task when you're screwing with Linux that this would be Done.
Hmm, maybe I'll just pay for the fine product again. :) It does work flawlessly for me, even if I only do use it once.
[ ... 433 words ... ]
Okay, so I've seen my first spam via my referrers. Checked my referrers RSS feed this morning to see the following pages in the list:
http://www.voodoomachine.com/sexenhancer.html
http://www.voodoomachine.com/linkoftheweek.html
http://www.voodoomachine.com/druglinks.html
http://www.voodoomachine.com/awards.html
Not linking directly to these pages, out of some vague sense of "Don't encourage 'em." The pages don't really link to me either, of course, they're all just pointers to an ad-ware site for this AMAZING DEVICE that does everything from making sex feel better, helping you study, aiding in sleep... it even makes DRUGS better! Wow, this site is so amazingly derivative of the classic snake oil pitch, with a touch of the modern and dot-com-days (ie. Works with DRUGS! Click our FAQ link!). But I can still hear the wheels on the wagon squeaking as it trundles through town.
I'm just trying to imagine by what criteria they picked my site to spam - oh, that's right: there is no criteria. They don't even know who I am.
On one hand, I'm annoyed that whenever I get back around to working on referrers, I'll need to add a blacklist feature (shared / collaborative blacklists?). On the other hand, I'm annoyed at the owners of that site, and even more annoyed at the 0.01% or so of their targets who'll BUY NOW. And then, on another hand still (I have many hands in the blogosphere), I'm amused by the whole thing: it's almost self-parodying in these post-Cluetrain days.
Oh well, back to work...
[ ... 445 words ... ]
So we've managed to get the go ahead at work on what seems like it should be a nightmare project: We're going to re-examine, re-design, and re-implement our in-house web app platform, the Toybox. Not only that, but we're going to switch languages, from Perl to Java. It's got me immensely excited, though this may be naive of me.
It's been years since I was last knee deep in Java, and years that I've spent up to my ears in Perl. I'd almost forgotten how much of Java I'd reinvented to make my ideas work in Perl. (This may not be so much an indictment of Perl as of the way I think.) And the last time I worked seriously in Java, there were no IDEs yet, so starting to work with NetBeans or even Project Builder under OS X for Java work is a dream. I love using NetBeans in particular, occasional hiccups aside. Besides all the obvious integration of build, test, run, debug, etc, I love being able to highlight a keyword or class name and pop up the docs in an internal HTML browser. I love that it makes suggested changes to classes when I change an interface they implement.
Yeah, none of this is news to most of the world, but I've been steadfastly sticking to shells and bare emacs or pico for my editing. Maybe a web browser handy for docs. I haven't worked very much with IDEs these past years, since a lot of them just got in my way. Or at least, with hubris, I thought that they did. Then again, I don't see very many equivalent tools for a language as free-form and multiple choice as Perl.
And, though I miss CPAN, I'm loving resources like the Jakarta project over at Apache. Again, not news, but new to me. I feel like a Rip Van Winkel-Java over here, since my last real work in Java was when the API was in 1.0 days, Servlets were this neat thing for the Java Web Server (now at the end of its life), and the dot-com boom was just starting to stretch its wings.
Now, I haven't been completely oblivious to Java over this time. I've poked at it, and played with a few things from time to time to at least stay somewhat current, and I've tried to vaguely keep up with things a bit. I have an overall sense of what does what and where to find what, but really getting it under my fingernails again now is a different experience.
[ ... 921 words ... ]
Whew, so where have I been this month? I didn't realize it, but here I am in the third week of July having only made 3 posts to this site. Well, I've been busy at work and busy at life, and without much time for the free time hacking I've wanted this site to be about. Maybe it's Summer - I'm sure once Fall and Winter hit, I'll be back here jabbering your virtual ears off.
Anyway, I've got a few things I can jabber on about today, so I think I'll try to compose a few posts.
[ ... 99 words ... ]
Ack! So I was trying to switch my PairNIC-hosted domain over to DynDNS's Custom DNS service last week. I thought all was well, since I followed the directions exactly. As it was, it really only consisted of "Set your domain's nameservers to ns[1-5].mydyndns.org". So I did that, then left for a few days. Come back and I see that it failed miserably, and took 36 hours or so to switch back to ZoneEdit. Grr. The only thing I noticed was that ?PairNIC's control panel appeared to randomize the order of the nameserver addresses I entered, and ?DynDNS had a note in the docs stating that I needed to have only ?DynDNS nameservers listed in my record and no mixing with other DNS hosts. Could it be that ?DynDNS is picky about the order in which my record lists nameservers?
Grr. Well, I'm back on the air. I just hope not too many of you out there with news aggregators and auto-unsub-on-error have had me slide off your lists.
[ ... 269 words ... ]
So last month, the crew at LiveJournal finally fixed RSS feeds on all journals. This month, LiveJournal becomes a centrallized news aggregator. Plenty of paths in and out of the LJ "gated community" now to wire everyone up into blogspace at large. This kind of tweak-by-tweak improvement is one reason why I stick around LiveJournal. (I just hope that they're polite about it and periodically poll RSS feeds sparsely for the entire userbase. :) I assume they're smart enough to figure that out.)
Need to get back to that LJ for K-Logs project...
[ ... 207 words ... ]
A friend of mine on LiveJournal draws some interesting parallels between the intertextual relationships connecting pieces of Heian literature and the links connecting web pages:Large amounts of Heian poetry have survived, and scholars generally know what's what when it comes to references from one poem to another. These days, given that the average person (probably even in Japan) is no longer familiar with whole of the poetic tradition Heian poets were writing in, the poems can still be read. It just requires lots of footnotes that cite the poems that the original author was referring to, and the patience to actually read the footnotes.
Some of what we've put on the internet will almost certainly survive us. But will it still be readable when all the links are long dead?
[ ... 131 words ... ]
Okay, I've only met the people in this movie once, maybe twice, but it made me wet myself. Run, do not walk, to see:
YAPC 2002: THE MOVIE
Damn. One of these years, I have to make it to a YAPC... (like I've been saying on IRC for the past 4 years)
[ ... 53 words ... ]
Okay, so NetSol's interface for me to change the DNS server responsible for decafbad.com has been coming up with an error page for me, for 3 days now. I just donated to DynDns.org so I could get some dynamic DNS love going on with some decafbad.com subdomains, but no dice on switching the domain to point at their servers when my registrar's site is broken.
So, I'm going to VerisignOff. I hopped over to PairNIC and initiated a transfer. Let's see how much hassle this brings me. :)
[ ... 146 words ... ]
Though I'm far, far from being an "artiste" of a photographer, I want to do neat things with my camera. I want to capture some moments, some feelings, try some odd things. It's like hacking with light. I see the kinds of things done with the Lomo cameras, warm and in-the-moment images. Sometimes they're blurry, but that just lends them a rough handmade voice. I read the 10 Golden Rules of Lomography and think, yeah, that's what I want to do with this new gadget. But I hope that the lens and the digital doesn't kill too much of the warmth. There's a certain style that the Lomo gives to things that I doubt my gadget will get, but I want to capture the moments now that I have something small enough to be omnipresent with me.
Hopefully this doesn't just degrade into 101 pictures of my cats. :) We'll see.
[ ... 152 words ... ]
Cool, looks like TrackBack is working and starting to catch on this morning. I caught a nice compliment about my mutant outline skin for AmphetaDesk. Must get back around to the next iteration of that thing, add some polish and some new features.
As for the MT upgrade from last night... looks like it nuked my post categories. Grr. That kind of blows chunks. Might have to see what that's all about, since I sagely backed everything up first. Another thing is that I'd like to look more into this TrackBack feature and the concept of TrackBack URLs and pings. Namely: It's a pain in the ass to cut & paste the TB URL, and the bookmarklet hasn't worked for me yet.
I notice that there's some RDF embedded in my posts now, describing the TrackBack link. Unfortunately, I don't see where the RDF explains that it is, in fact, about a TrackBack link. Though I haven't dug into the workings yet, I assume that this is how TrackBack-enabled pages discover info about pages from which they've been pinged.
What would be nice is if the RDF also identifies itself as TrackBack info. This way, I could hack my Movable Type to pluck URLs out of a post I'm publishing, go take a visit to each URL and try to harvest the RDF, and then automatically discover the ping URL and ping it. All I'd need to do to activate the process is include a link to a page elsewhere that contains RDF hints on how/where to ping.
Always looking to get more for less effort. :)
[ ... 420 words ... ]
Checking my RSS feeds, I see MovableType 2.2 has been released, and it comes with support for a feature called TrackBack. Too sleepy to fully investigate and play right now, but it looks like another very cool push toward interconnectivity between blogs.
[ ... 43 words ... ]
So I broke down finally, and bought a digital camera. The excuse ends up being that I'll be needing it on my trip to Toronto this weekend. I got a Canon ?PowerShot S200, a 128MB CF card, the belt case, and two extra batteries. That should be enough to cover a rampant nerd photography spree.
I love this little thing, and I've been going insane with it. After some twiddling and organizing in iPhoto, I uploaded a metric ton of photos and grabbed Gallery from ?SourceForge to show them off in the new 0xDECAFBAD Gallery.
Then, I stuck a lil PHP block that rotates random thumbnail images from the gallery into my busy and crowded right-side bar. I can hear the woefully overburdened design of this site creaking and about to fall over. So, next project in a week or two is to tear this place apart and make it a bit easier on the eyes.
That is, after I take a few hundred more pictures. Been thinking of joining one of those online DP clubs to play around in a photo scavenger hunt.
More soon.
[ ... 187 words ... ]
Not much out of me yet, busy with many things. But, you can look for the warchalk glyphs out in front of my apartment later today.
[ ... 27 words ... ]
From the recently-returned Dave:I am now an ex-smoker. I want to say that in public. Of course I still really want to smoke.
Me too, since January 2002. As Dave explains, I too had a very deep, integral place in my problem solving process for a cigarette. I also had a spot for a cigarette in my avoiding-violence-against-coworkers process. But, many panic attacks and insanity-verge moments later, I think I'm doing quite well. I have started strangulating more co-workers, but my problem solving skills have become mroe productive.
[ ... 122 words ... ]
Here's a crazy idea I'm considering: Deploy the LiveJournal source as our company-wide k-logging service. Definitely make some cosmetic tweaks, possibly make some backend tweaks, but it might just be crazy enough to work. This just struck me today, remembering back when I'd last thought about this.
LiveJournal can support a for each employee. It has communities, which I can use for projects or special topics, or other forms of narrative pooling. It has the concept of friends and friends pages, or in other words: subscriptions and aggregators. There are friends groups, which we could use as aggregator feed groups. And the laziness threshold is demonstratedly low, seeing the ease and frequency with which 14-year-old spew trash around their journals. :)
And I'm thinking that any things missing from the LJ source I might want will be easier to add in than to build the whole thing up from scratch. And it's completely Open Source and free, though I might be able to convince some donated funds out of this place if the experiment is successful. Hell, if not, I'd consider grabbing a permanent account the next time they offer them.
Hmm. I still, someday, would like to see a decentrallized, server-less desktop answer to LJ, but this might work for now. Radio + Frontier might get there someday, but the idea of K-Logs has such tenuous support in my organization that any cost whatsoever would kill it.
Must play with this idea. Must insinuate it like I did with the wiki. It was accepted and made policy almost before anyone knew what hit them. That was fun. :)
[ ... 270 words ... ]
In case anyone's been wondering where I've been, here's the story: Clawing my way back to the land of the living
Briefly: Been bedridden with something nasty. Too wiped out to do much besides read & stare. Working on getting healthy and productive again.
Be back soon.
[ ... 48 words ... ]
Now that I have this recent RSS readers list in RSS (src), I can start to see who's just pulled me into their neighborhood. (It even catches the userWeblog parameter from Radio subscribers!)
And I think I see that I've just had Punkey, Sean Porter, and Nick Nichols join the audience. Oh, and I see you've moved a bit, Mr. Ruby.
[ ... 81 words ... ]
Guess what? AmphetaDesk v0.93 is unleashed upon the world - so sing and rejoice, fortune is smiling upon you. I'm proud to say that I built the OS X faceplate for it, and hopefully the toxic chemicals I used in its production don't cause any lasting effects on you, your children, or your pets. So, go get it you infovore freaks!
[ ... 62 words ... ]
More on aggregators and extending the concept further into the desktop, Ziv writes about aggregation as a tool for the exterprise. This is starting to cross over into the digital dashboard buzzword area, but I'm thinking that what we're all converging on will be the real deal.
I had to giggle though, because the Sideshow project from Microsoft Research looks like my OS X dock on steroids. Even down to the vertical arrangement, mail indicator, weather reports, IM buddy display (no faces, though), and a few other information readouts. Of course, my dock doesn't have the neato pop-out in-context mini-browser windows that connect to the icons, but that could be a keen OS X project. Have to think about that.
[ ... 121 words ... ]
Joe Gregorio: "...I didn't really see a need for CSS when I first learned HTML, but as I maintained some web sites over time and bumped my head enough times on having mark-up embedded in my content which made it difficult, if not impossible, to deploy a new look and feel to site without having to edit every page, I suddenly had a real need for CSS. I still have a lot to learn, still more head bumping to do, and I want to have RDF, SVG, SMIL, and all the rest in my pocket when those days come."
This, along with his reference to Joel's piece, "Can't Understand It? Don't Worry", strikes a familiar chord with me. So does what Dave wrote on XML and practicians vs theoreticians.
The attitude I try to lead with when playing with all these new toys is that of a beginner mind. Or, at least, that's my attempted tact lately. On the one hand, some things might look hopelessly convoluted and needlessly complicated to me. On the other hand, there are people who are both more expert than me and who have worked longer than me on those things. More than once I've decided I could do something better than someone else, only to discover that I was just following in that someone's footsteps down the line and rediscovering all the pitfalls. But sometimes, I do demonstrate that I'm smart too, and figure out something new.
So, I try to reserve judgement until I've grokked the thing. Until I've soaked in it, played with it, scanned through the squabbles surrounding it, caught up with the Story So Far. Sometimes I learn what's what. Sometimes I don't. And sometimes, I come to the conclusion that the thing I'm looking at really is a mess, and I stay away from it.
My particular angle at the moment involves XSLT and SVG. We want to put together a reporting and metrics package in-house at work, and I'm thinking that XML/XSLT/SVG may be a good combination for charting. I understand SVG - or, rather, I get it to the extent that learning it appears obviously useful. On the other hand, XSLT still has me scratching my head a bit.
An evangelist for XSLT at work here was trying to convince me that we could have all the HTML guys switch over from our current template technology, which is basically text or HTML with a small procedural scripting language for presentation work. At present, the HTML guys are used to their process. They've been doing it for years. And as far as I know, they hardly ever touch the functional elements of the templates like the table foreach loops and such. I have a sense that learning both XSLT and LISP will feel wholesome to me, but I can't see the HTML guys doing it. I mean... recursion?! What? I just want to make a table and have the rows fill in with data!
So maybe the problem with this is that this is not precisely the perfect application of XSLT, though it seems to be. With our current template toolkit, the logic of the app passes a perl data structure (a hash) to the engine, which then processes a template which refers to the keys of that structure. I could easily represent that data structure in XML, with structure and lists and branches and all. And I could see conceptually where an XSLT stylesheet could replace our templates.
But forget about our HTML guys for the minute. What about me? Like I said, I think it will be good for me to learn XSLT. But I keep catching myself thinking: Why not just use a full scripting language? Why not just use the template kit I know? I'm thinking I don't grok XSL well enough yet, though a part of me is grumbling skeptically at it.
I vaguely see some magic in it, though. Like, XSLT contains instructions for transforming XML, yet it itself is XML. XSLT uses XPath, which is vaguely starting to take shape in my head as something very powerful to replace many loops and frustrations in my scripting language XML processing. And I keep seeing suggestions that XSLT can be seen as the SQL of XML, and I can imagine those uses. But then, I see an article on Two-stage recursive algorithms in XSLT, and I think, "All this, just to write a loop to calculate a sum?!"
But I'm thinking part of this, too, is me sorting out "Daily Intended Use" versus "Freakish Abuse of All that is Good and Holy". Maybe when it comes down to sums, I'll just do that in Perl.
Hmm. Back to drawing barcharts...
[ ... 1006 words ... ]
Oh, and after downloading Mozilla 1.1a last night, I was pleased to see that the navigation toolbar was back. And then, just now, I was even more pleased to see that it picked up the LINK to my RSS feed on my front page:
[ ... 45 words ... ]
Ziv Caspi of Y. B. Normal thinks that "Aggregators should bring more, not less, information", and I'm inclined to agree. Also, Adam wants to take the aggregator even further: "...I think the entire computer interface should be overhauled to be more aggregator like, events streaming by."
Along these lines, has anyone played with Scopeware, built from the research of David Gelernter? I think it used to be called "Lifestreams" before it was made into a product. I first heard of this work back when I read Machine Beauty : Elegance and the Heart of Technology, and was very interested but haven't seen anything other than screenshots and mock-ups. From what I can tell, this interface is literally "events [and documents] streaming by".
The little I've picked up from Gelernter's work, along with a few other influences (ie. David Brin's Earth), has really stuck the picture in my head of how I want my future info-sieve to work.
Along with all of this, something else I was vaguely considering adding to my AmphetaDesk outliner skin was an IFRAME attached to RSS items under a collapsed node. When the node gets expanded, the IFRAME is loaded up with the item's link. The notion is that you do all your browsing from your RSS feeds in a single window and within the same context. Neat idea, I think, giving a hook to pull more information into the aggregator upon request. But of course if I do it, it'll likely be messy as hell for a zillion obvious reasons and catch my iBook on fire.
Probably have more to ramble on about this later, but it's time for the first meeting of the day...
[ ... 281 words ... ]
Taking a stab at learning XSLT. TestXSLT from Marc Liyanage is making me happy and helping, for many of the same reasons I enjoy learning Python, and have been somewhat enjoying learning Common LISP again.
[ ... 36 words ... ]
Okay, I've lost count of how many times I've seen a referer like this: http://google.yahoo.com/bin/query?p=Tiffany+Playboy+Pictures&hc=0&hs=0 How the hell did I become a destination for the web's nekkid Tiffany needs? They're not here. Seriously. Otherwise I'd be charging, at least $14.95/month.
From what I can see by chasing the Google referers, it's my old stats page that got indexed, and that's gone now! I can't remember ever having mentioned the name "Tiffany" on this site (until now), and doing a complete text grep through every file on my server yields no hits.
So, somehow the rumors of Tiffany pics over here got started, and then Google must've initially gotten the notion to index my stats pages when I mentioned them back in April. Indexing my stats page further fed Google from Google's own keyword referers already present in the stats page. Gah. But where's the initial Tiffany-link event?
This is all highly confusing, yet amusing as hell. I wonder if I can work this somehow to further and gaslight Google, making me a definitive source for other things? Say, "wil wheaton monkey sex" :) Naw, I have better things to do.
Okay, back to work.
[ ... 195 words ... ]
Just wasted a good 20-30 minutes having been sucked into the IRC Quotes Database that Adam mentioned. It made me spray coffee out my nose. So, rather than visit it everyday, I made RSS feeds from it, scraped by RssDistiller's enclosePat (need to implement that in Perl sometime). You can find a feed for the top 25, 25 latest, or just get a random grab bag of fun.
update: Ack. Looks like my scraping isn't pulling in the actual quotes. Back to the drawing board. :(
update 2: I think they should all be fixed now :) I missed a para tag in the source.
[ ... 222 words ... ]
Another thing to think about again: Whitelist-based spam filtering. The spam is just getting heavier, raunchier, and less coherent these days. I'd mused about it awhile ago, along with looking at an application of RDF to share whitelists between trusted people.
Then I see this article up at osOpinion.com on the subject (calling it "reverse filtering"). I hadn't thought of it before, but I could probably set up a quick auto-responder for unknown addresses, asking politely for a response requiring human thought, or a click by a person at a URL somewhere, to get them auto-added to my whitelist. If the laziness/rudeness factor toward friends and acquaintences, current and potential, doesn't outweight the benefits, this might be a very good solution. I wouldn't throw mail away outright, but it would be put in a rotating bin that I might look at every day or so, and wipe every week or so.
That osOpinion.com article wraps up with a little bit of a carrot / challenge to for a business plan around a whitelist / reverse-filtering scheme for mail. I wonder how much people would pay for it, and whether people would be put off by an auto-response asking for proof of humanity? If it would go over well, I'd love to see pobox.com implement something like this. (Oh have I ever mentioned that I love pobox.com, and think you should all sign up there?)
In the end, this seems pretty amusing to me. Humans sending robots to mail humans. Humans setting up robots to intercept robots. Humans sending mail to humans again. Oh I'm sure the spammers will try harder with their robots, but eventually the bastards just have to give up. Maybe not. But at least I can ignore them.
[ ... 356 words ... ]
Reading Dave's in-progress What is a News Aggregator?: A news aggregator is a piece of software that periodically reads a set of news sources, in one of several XML-based formats, finds the new bits, and displays them in reverse-chronological order on a single page.
..and the rest leads from there. First thing: I think this is an unfortunately limited definition. It specifies the particular interface by which Radio presents information. And, as a comment on one of my first experments in tweaking AmphetaDesk's interface attests (no author link):I've been wanting to use an aggregator since I first heard of them (RU7) but have always felt that because poor information architecture/presentation they tended to make tracking a large number of sites harder rather than easier.
I didn't expect my first attempt to be called "Brilliant! Lovely! Perfect!", but I did think that I was on to something. Simply displaying the new bits in reverse-chronological order is too limiting - it's only one attempted solution at the problem of aggregation. My solution isn't an ultimate one either.
Aggregators desperately need to grow toward more flexibility and scan-ability. A few things I'd really like to see addressed:De-emphasis of seen & older items from sites, but not complete hiding. Context between entries on weblogs is important.Optional grouping of items from the same or similar weblogs. Context between entries, and between blogs is important.Emphasis of newer items, tracking the time line and signalling attention to changes. Radio does this, but mostly to the exclusion of other concerns.Preventing sites with few updates from getting lost in a wash of frequently updating sites. Some of the best sites may update once every few days with something worth reading, but simple reverse-chronological order pushes the quiet sites out in the maelstrom.
There's more I've been musing about, but I can't remember more at the moment. I've tried to do a few of these things with my tweak to Ampheta: varied (hopefully not obtrusive) font size & weight, dependant on item age; maintaining grouping and order of items within RSS feeds; showing enough information for a visual scan, hiding further details, but making details available within a click or two (I love outlines). I wanted to hit the page-down button less, but it's more than that. I want my eyes to move slow on the first few items of a channel, and then slide down off the rest, unless I intentionally want to be caught.
So, while Dave's working on defining the News Aggregator, I think it's a good time to redefine it a bit while he's at it.
[ ... 783 words ... ]
Okay, starting to poke at my referrer scripts again and produced two new things: Recent Referrers in RSS (src) and RSS Feed Readers (src). I simplified my database a bit, collapsing multiple rows into single rows with a hit count column. Also squashed a few stupid bugs that had cropped up in the Great Site Move a month or so ago. Realized that the counts were insanely wrong, sometimes showing a count as high as 15 for a post that might have only 3 back links.
Likely the referers in RSS will be of interest only to me as I obsessively watch my site (though I do subscribe to Disenchanted's Recent Inbound, since it gives me a stream of new sites to visit). But, the RSS feed readers list is a few steps closer to the friends-of list I want to move from LiveJournal out into the blogosphere proper.
One of the next things I want to do is start cobbling a fairly modular & general URL investigator - that is, give it a url, and have it try to track down title, author, contents page, RSS feed, location, and any other metadata that comes up. I could then use this to flesh out all the links everywhere, from backlinks to the friends-of list. Basically what many other people have been doing for different semantic aspects, but all rolled into one agent.
Along with that, I want to implement some manual annotation of sites known by my site. Thinking that, between per-post backlinks and RSS reader links, I could eventually build a decent database of metadata here. With that, all kinds of nifty things could happen...
Okay, time for bed. Starting to ramble, or at least be tempted to do so.
[ ... 367 words ... ]
Awhile back, I was musing about linksback, robots, and the web semantic - and to my dumb idea about scraping metadata from HTML comments, Bill Seitz recommended I put my metadata into meta tags in the HTML header. Duh. So today, I pick up this post by Bill Kearney on "Real Neighborhoods" via Jenny Levine. (Man do I enjoy being fed by her site! She gives me a whole new respect for librarians.)
So it's likely not news to you, and there's probably been talk about it already, but I just caught on to Syndic8.com's metadata support. Brilliant. I need to dig into the Dublin Core elements more, as well as other attributes to put in meta tags, but I think this would be another great addition to weblog software out-of-the-box.
Lower the laziness threshold for managing this meta data, increase the ubiquity and coverage, and spread another layer of tasty goodness on the blogosphere.
What's next?
[ ... 158 words ... ]
Now, after quickly hacking outlines into AmphetaDesk, I see Adam Wendt playing with RSS and XSLT. Seems like a much cleaner way to do it, and really makes me want to play more with XSLT. The AmphetaDesk template hack I did is still horribly inelegant, doesn't leverage the DOM, and could use some tidying. Would be interesting neat to see XSLT in Ampheta, but that might be a bit much right now.
[ ... 73 words ... ]
This past week, I've been playing with the new AmphetaDesk checked out from CVS. Morbus Iff gets closer to a release, and I threw together a Cocoa wrapper and outline skin for Ampheta.
I've been bouncing between Radio, blagg, and AmphetaDesk for my reading this week, and I'm leaning more and more toward Ampheta. Radio's a powerhouse giant, blagg is a tiny gem, but AmphetaDesk is starting to look just right.
Especially after I hacked together an outline-style template for it today. You can grab a copy of it over here: amphy-outline-skin.tar.gz
Back up your AmphetaDesk/templates/default directory and replace it with the one in my tarball. It's still nasty, probably horribly buggy and inelegant, and seems to vaguely work under Mozilla 1.0 and IE 6.0. But amongst the skin's features are these things:All channels, items of channels, and descriptions of items are arranged in a tree of expandable/collapsible branches.Links are provided to expand/collapse all channels, and all items in a given channel.If more than 10 items appear in a channel, the rest are hidden below a collapsed branch, but still available.From newest item to oldest, the font changes from large and bold to small and normal.
Check it out, let me know what you think. It's based on Marc Barrot's activeRenderer code, and inspired by DJ Adams' application to blagg of the outline presentation.
[ ... 403 words ... ]
Science Toys You Can Make With Your Kids: Whenever the end of the world comes, and we're all reduced to extras in a real-life Mad Max movie, I want to make sure I have the entire contents of site printed out and stuffed into the front of the high school chemistry textbook I kept. I'll offer my services as "wizard" to the warlord of the local city block. (Found via Backup Brain)
[ ... 73 words ... ]
Okay, so now we've got a bit further toward our News Aggregators leaving vapor trails. Thanks, Morbus. Thanks, Dave. There's still some more work that needs to be done, though. In specific, how do I get to you via your trail? Or, to be even more specific- how to my agents get to you?
Sure, I can look in my referers now, and filter on my RSS feed to see a footprints. And for Radio users, I can pluck out the userWeblog=... param added to Radio aggregator referers. For others, like the page I set up, or Adam set up, or Jeff set up, I can try to assume that the URL leads... somewhere.
But, in thinking about this further, none of this actually fulfills my wish. I originally wanted to see these referers lead directly to a reader's blog. They don't. But, that's fine: I kind of like the idea of the thank you / hello / I'm reading your page. However, I still want to find you.
Or, rather, as I alluded to in the first paragraph, I want my agents to find you. And my agents are only semi-intelligent. So how about we set a standard by which bots can autodiscover your weblog, home page, whatever:If you don't care to put up a special page to point to as your referer when aggregating news, then point a URL somewhere, anywhere, but include a URL to your weblog in a query parameter named "userWeblog". This covers an already de facto standard set by Radio.If you do care to set up an acknowledgement page for your readers, include a LINK tag in the page's HEAD pointing to the home page of your site as the table of contents: In this way, rock bangers cobbling together their own blog spiders can tell them where to go and for what to look. Get this meme spread, and we'll be seeing more community crawling bots very soon now.
In fact, I like this LINK tag now. I think it should be put on all of your weblog pages. Especially as I start thinking more about revisiting referers: A LINK back to your weblog home as the table of contents would allow me to maybe enrich my backlinks, especially knowing where your site root is. (If my eyes do not deceive, it looks like backlinks on Mark Pilgrim's blog do some RSS autodiscovery right now.)
Anyway, let me know what you think.
[ ... 575 words ... ]
With regard to some new things in Aggie, Chris Heschong writes: "If only Microsoft (or Mono would get a .NET runtime out for MacOSX." I say, "Ditto." I'd like to play with Aggie, and .NET for that matter (evil empire notwithstanding), but I don't really use Windows on a daily basis anymore (evil empire withstanding). I have a box at home running WinXP, but I only really use it for games (less often these days), and for recording my shows. The rest of my daily use machines are either Linux or OS X. Hmph.
[ ... 214 words ... ]
Noticed Nicholas Riley's entry about switching IRC clients, and the screenshot reminded me that I needed to download Duality for Mac OS X again. I love that stripe-less ?SilverFox theme. Feels like a cool cloth on my eyes and makes me even think that my iBook is faster.
[ ... 112 words ... ]
Whoa. Rock on, Dave. My wish for blog URLs as referrers in Radio while gathering RSS channels is now the default setting:A tiny change in Radio's aggregator makes referer logs more interesting. Please read this if you provide an RSS source for Radio users, and you watch your referer logs.
So what's next? :)
[ ... 130 words ... ]
Holy shit, it's done: Mozilla 1.0 Release Notes. No asymptotic versions (ie. 0.9, 0.99, 0.9998, 0.99999314), the fork has been stuck and the fat lady will dance, along with the skinny ones and others of all sizes.
[ ... 38 words ... ]
I've (not so) secretly replaced my aggregatorData.prefs.appSignatureUrl in Radio UserLand with this URL. Let's see if anyone notices. Watch your referrer logs for visits from my invisible (s)elves.
/me pops in his Vapor Trails CD, whistling...
[ ... 109 words ... ]
From Adam Wendt, in my referrers today: " Hey there! I'm reading your RSS feed!" This is precisely what I was wishing for, back when I said "I wish Radio sent me blog URLs as referers on news aggregator hits" Now, I just have to tweak the 3 news aggregators I hop between to supply something similar. Anyone want to jump on this bandwagon and help push it as fast as the recent RSS autodetection meme? :)
Catching up, I see that Adam wrote about what Jeff Cheney wrote about changing aggregatorData.prefs.appSignatureUrl in Radio UserLand to point to a custom page. Hey, Radio crew, how about making this a default, eh? Point that signature at my blog, or a canned custom page? Yay!
[ ... 124 words ... ]
I love it when LiveJournal gets some props, and via Dave no less: LiveJournal to support RSS and discovery. RSS was gone for awhile from journals, but now it's back and with autodiscovery link tags.
Aggregate me:
Autodiscover me: http://deus-x.livejournal.com
Radio subscribe me:
[ ... 44 words ... ]
So I see this referrer on one of my postings today:http://referers/are/easy/to/fake/First reaction: giggle Second reaction: "Well, duh." No one's ever claimed that they weren't easy to fake, break, subvert, or otherwise derail. It's just that the default, unmolested behavior of many browsers is, happily, to report from where they came to find your page. This is fun data to play with.
Taking this "statement" seriously for a second: One thing I intend on doing with my next iteration of referrer tracking, is to chase referrers and attempt to verify their existence while trying to harvest some metadata from the page and surrounding site. That would filter out some fakes and provide some context. This is still frustratable, though, because you could provide me with metadata stating "Metadata is easy to fake."
But, in my mind, the goal isn't precise, panopticonical monitoring of visitors' activity. The goal is to provide easy cow paths for cooperation in building a semantic web, planning later to bring in the paving crews.
So, sure, you can fake the data I'm trying to lift from your activities. That's your right. You can even choose not to give it to me. No skin off my back. The nature of the endeavor is cooperation, so it's as up to you as it is up to me. It's the wiki way, it's the way of civilization.
You can kick my house over, walk by, or help me lay bricks. In any case, the house will still get built as long as I still like building it.
[ ... 269 words ... ]
Ack. Must remember to close my blogchat window when I leave for the day, so that I don't come back to find people having been looking for me, seeing me in the room, and wondering why I'm so rude. :)
[ ... 41 words ... ]
I've talked briefly about the attempt I've made at segmenting my writing between here and my LiveJournal account, assuming that there would be overlapping yet different audiences for both. To be exact, I assume any readers who find me here are looking for my techie nerdery, while my LiveJournal readers are looking for something a bit more "human".
But, it's all me, and it's all of human endeavor. Should I segment, or try to blur the bounds more? For example, here's a bit of what I wrote in my LiveJournal today:First thing is on memories: they do lose their meaning. Sometimes the lesson you should have learned from them changes or is forgotten. Sometimes you remember them differently, maybe more glowingly. Everyone has his or her own Myth of the Golden Age, particularly with respect to the past.
At dinner this weekend with missadroit, I was slipping into some bemoanment toward my "lost college years" and my seeming inability to "recover" some of the wonderous things and times I had then. The friends, the illumination, the learning, the hope, the excitement. Problem is though, all that's a myth I've created. While there were good things back in college, there were also shitty things. My college days were not a Golden Age. Just as she reminded me how pathetic it is to say, "High school was the best time of my life," treating my college days as my Golden Age is just as pathetic.
The thing I've not been facing is exactly what grlathena writes: "The future is very do-it-yourself."
The world didn't run out of wonder or friends or opportunities for fulfillment after I graduated, it just got a bit more miserly in just tossing them at me. See, life in school is still very scripted. There are many choices made in advance for you, based on only a handful from you. Out here in the "real world", things are much less scripted, and many fewer things are just given. It's very do-it-yourself.
I know all my fellow rock bangers are human beings, too. I just hesitate to waste their time with too much off the topic of rock banging and more on the topic of human beings. Should I overlap more? You tell me.
[ ... 375 words ... ]
I'm thinking of getting a digital camera. Price is a concern, but mostly my concern is small size and pocket-ability. I want this to sit in my jeans pocket, maybe my coat pocket, and take somewhat decent images. I'm not quite as concerned about super high-res and printable images, as I am about capturing 50-100 decently bloggable images (~640x480 and smaller?). I want a device inobtrusive enough to keep with me at all times, so I can pull it out in the moment, and capture what I usually miss. And preferrably without needing a Batman-like utility belt. I don't really like that style anymore.
Basically I want to start a bit of a personal photo journal blog. That's photo album enough for me.
So how about this camera to start?
Kodak ?EasyShare LS420
I've held this one in my hands, and it feels good and small, yet seems to more than satisfy the performance I want out of it. I've also looked at the Spyz, Cubik, Eyeplate, and one or two other tiny cameras, but they seem to be too under powered for what I want, in terms of memory. And they also seem cheap. Then again, I haven't held any of those in my hands. And then again, again, cheap might be good if it's banging around in my pocket.
I'm sure I'm not the only person thinking of doing this, or already doing this. Any one have some pointers for me?
[ ... 337 words ... ]
Sam Ruby wants to go Beyond Backlinks, and I'm right there with him. He writes about the various means we've tried so far to discover connections (ie. referrers and linksback and Jon's analysis of blogroll connections), and muses further. I love the idea of further automation in surprisingly discovering connections and automatically exploring other feeds, based on discovered connections.
A plug for LiveJournal: I love their user info pages. I've been idly musing for a while now on how one might decentralize this and extend it web-wide throughout blogspace. I love seeing the friends and friends-of lists, analogous to blogrolls and inverse-blogrolls. And, I really love the interests lists, since just by entering a catalog of phrases, you can see unexpected links to other people interested in the same things. Not quite correlations or deep analysis, but it helps.
But it's the decentralization that rubs. I could probably start a service that provides user info page workalikes to bloggers. I could offer it for free, but then I might get popular and have to pay more for my altruism than I can afford. (Sometimes I worry about BlogRolling.com.) I could offer it for a small fee, but then the service would probably never see widespread use. Were it decentrallized, I could write some software, and others could pay their own way in server resources. More to think about this.
Also, if I can get time this weekend, there are a lot of parts of David Brin's novel, Earth, that I'd like to babble about. Reading it right now, and seeing that he wrote it just around 1990, I'm amazed at how fresh it still is. Sci-fi and speculative fiction rarely stand the test of years and unexpected advances, but a lot of the stuff in this book - particularly about the way in which people deal with information, how they discuss and create and manage it - seems to be happening right now.
Anyway, more soon.
[ ... 736 words ... ]
Found these hot little things via Phil Ringnalda and via Matt Griffith: Mark Pilgrim's Amphetadesk Auto-subscribe bookmarklet and Radio auto-subscribe bookmarklet. So, now when you visit the site of someone who's joined the RSS autodiscovery via HTML LINK element bandwagon, you can snag their RSS feed into your aggregator.
This makes me really want to get back to studying some in-browser scripting and DOM manipulation. It's been awhile since I played with that, and I see more cool things done with it all the time.
Tasty. Now I just have to wrap a few more things up, and I'll hopefully be contributing an updated Cocoa-based OS X faceplate/installer for AmphetaDesk to Morbus before the weekend's out.
[ ... 117 words ... ]
Matt Griffith suggests using an HTML link element as a way to provide robots and news aggregators with means to find a site's RSS feed. Mark Pilgrim chimes in with a few thoughts and an improvement. And then, I see the buzz coming from Jenny Levine too.
So, well, it's easy enough. I just joined the bandwagon too.
[ ... 152 words ... ]
Ouch. Remember that no matter how expert you may be on some things, if you start from false premises, you're doomed from the start. Just caught this article over on Linux Journal entitled "Obsolete Microkernel Dooms Mac OS X to Lag Linux in Performance".
In the article, the author expounds at length on the nature of microkernels and their performance hits, and makes a very clear and unabashed claim that "the microkernel project has failed". Well, I don't know a great deal about microkernels, other than vague skimmings here and there. But what I do know, is that you don't say "Obsolete Microkernel Dooms Mac OS X to Lag Linux in Performance" and then let slip something like "I'm not sure how Darwin's drivers work...", as well as never providing any metrics, analysis, code, or proof to back up the headline's claim other than to beat up a theoretical microkernel strawman.
The interesting thing to me though, is that rather than read the article first, I read the comments. And the thing I saw was an enormous number of comments all pointing to Apple's Mach Overview, so almost instantly I was informed about the credibility of the article itself. When you have a hundred geeks telling you to RTFM after a lenghty article, it says something.
In particular, the Apple document says:Mach 3.0 was originally conceived as a simple, extensible, communications microkernel. It is capable of running as a standalone kernel, with other traditional operating-system services such as I/O, file systems, and networking stacks running as user-mode servers.
However, in Mac OS X, Mach is linked with other kernel components into a single kernel address space. This is primarily for performance; it is much faster to make a direct call between linked components than it is to send messages or do RPCs between separate tasks. This modular structure results in a more robust and extensible system than a monolithic kernel would allow, without the performance penalty of a pure microkernel.
So, from what I gathered, this little blurb counters much of what the author actually claimed would slow OS X down. I may be mistaken on this, but it seems to be what everyone else was saying as well.
So, whereas in another circumstance, this article might've been taken as Linuxite Anti-Mac-OS-X FUD (what's the world coming to? :) ), in this circumstance the article is just taken as an obvious demonstration of a lack of research. Other than a bit of a sensation when I saw the headline in my aggregator, the steam got let out of it almost instantly.
Lather, rinse, repeat, and apply to all other utterances and publications.
[ ... 442 words ... ]
Does anyone out there know of a workable, preferably free app for WinXP with which I can launch and quit a program on a scheduled basis? Starting to work my mad Google skillz to find this, but having a hard time coming up with search terms that give me good results. See, Radio UserLand demands too much CPU from any of the machines I currently own. The desktop where I want to park it also serves as my PVR, and when it starts up to record a show, Radio keeps stealing CPU from the video encoding, and I end up with choppy and sometimes dead video. I even tried screwing with priorities, and that only seems to help moderately.
So, I want to start up Radio, let it churn free. Then just before a show comes on, I want to quit Radio. I was doing this manually via a VNC connection from work, but that's just stupid. The other alternatives I've tried are running it under Wine on my Debian Linux box, which doesn't quite seem to work happily, or to run Radio again on my OS X iBook, which seems to crush the poor thing.
I suppose my desktop PC is due for an upgrade, containing only a 600MHz Athlon (though 512MB of RAM), but I've been waiting on that. Funny, the last time I upgraded, it was to run a few more games. This time, its to make Radio happier. :)
(Addendum: Hey, wait, Radio's an intelligent, reasonable platform... I wonder if I couldn't just get it to shut itself down at a given time, and then have Windows launch it again. I think the shutdown is the main issue, since Windows seems to come with a scheduler already for launching programs.)
[ ... 590 words ... ]
Rock on. Kuro5hin now has a companion wiki named Ko4ting. I'll be very interested to see where it goes. (Thanks to nf0 for the link!)
[ ... 26 words ... ]
Still busy busy, but had to drop in for a minute to try out the Metalinker code here. Two wishlist items: 1) Maybe use a micro-icon for the metalink, and 2) some indication of the number of links to the link on Blogdex would be hot, maybe even a green-through-red series of micro-icons for the link. Could maybe count the links on the blogdex page via some sort of scraping, but that would require some server-side stuff since I doubt the client-side can do it. (Or I just don't know enough modern browser scripting lately.)
Because of the obvious connections, this makes me want to get back to my new-and-improved linkback implementation very soon. That'll be next after I tie up this Cocoa AmphetaDesk wrapper. (Actually got it 2/3 done last night, yay!)
Back to work.
[ ... 214 words ... ]
Oh yeah, and I am still alive. Just heading toward the light at the end of the tunnel of a long project at work over many late nights. Also have been living life a bit lately. But I've also been re-reading David Brin's Earth, VernorVinge's A Deepness in the Sky, and have a few musings about them. Also have been doing some intermittent Lisp and Python hacking. Oh, and I also will be trying a bit of Perl/Cocoa hacking for AmphetaDesk in the very, very near future. Hope to get back to at the news aggregator and web log controls soon. Anyone miss me? :)
[ ... 138 words ... ]
Hmm. I think I need to snatch up some of Marc Barrot's outline rendering code and apply it to my Movable Type weblog. Wrapping many of my front-page elements in outline wedges would be very nice. I suppose I could swing back toward the Radio side of things and use it more, but I really need to find a machine to be its permanent home. Eats too much CPU on the iBook, disrupts PVR functions on my Win2K box, and seems to work half-heartedly via WINE on my Linux box.
[ ... 91 words ... ]
Just saw Gordon Weakliem mention, via Roland Tanglao's Weblog, this article over at New Architect: Orbitz Reaches New Heights. This snags my eye for two reasons: 1) Orbitz is a client of my employer - we do a ton of web promotions for them; and 2) LISP is one of those things I keep meaning to get back into, kinda like I keep meaning to read things from that gigantic Shakespeare collection I asked for and recieved for Christmas from me mum.
The quote that Ronald pulls out from the article is:The high-level algorithms are almost entirely in Lisp, one of the oldest programming languages. You're excused for chuckling, or saying "Why Lisp?" Although the language can be inefficient if used without extreme caution, it has a reputation for compactness. One line of Lisp can replace 20 lines of C. ITA's programmers, who learned the language inside and out while at MIT, note that LISP is highly effective if you ditch the prefabricated data structures. "We're something of a poster child for LISP these days," says Wertheimer. "Lisp vendors love us."
Funny, if you did an s/Lisp/Perl/g and an s/LISP/Perl/g on that text, you'd almost have a quote from me. I've also heard Perl often compared to LISP, amongst the upper ranks of Perl wizards. Oldest language-- hmm, no, but it's been around the block. Inefficient without caution-- check, hand-holding is at a minimum. Compactness-- check, many bash it for obfucation facilitation. Effective after ditching prefab structs-- check, if you enjoy slinging hashes all over, like I have until recently. And so far, we're a poster child for Perl here.
What is it that I have in Perl? Well, I've named it the Toybox. It's a web application platform. We do everything with it. Reusable software components composed into applications with a web-based construction tool. The components contain machine and human readable descriptions on properties and methods, to enable inspection by tool and documentation generation. Also, the components and the framework are designed to provide predefined collaboration patterns so that one component can supplement or modify the behavior of another without that other component needing to be modified or altered. I've also just recently added a persistent object layer for all those pesky little parameterizing trinkets we started needed to throw around. (I really wish I could Open Source this thing. :) )
So there's a continual grumble here to switch to Java, sometimes from me, and sometimes from another developer or two. In some ways, a switch and reimplmentation is a no-brainer, considering tool support and labor pool. But, is this overhyped? Wherever I've gone, I've just picked up whatever was used there. My basic computer science background lets me switch technologies pretty easily. Is this rare?
But as for the languages themselves... From the trenches, doing object-oriented stuff in perl is painful and dirty. In a lot of other ways, it feels nice because you can jump out of the OO mindset and do some naughty things when you think you need to. And if you're careful. But when you do, you don't get any help from the language, which I think is one of the major selling points of Java.
And then occasionally, a client demands to know the specifics of our platform. Such as, what vendor's app server are we using? What database server? And when we say Perl and a platform almost completely developed in-house, noses crinkle and doubts arise. But they rarely have a complaint about the end result and the speed at which we execute it.
I guess what I'm getting at is this: Having a hard time untangling politics, job market, and the right tool choice. LISP seems to have done alright by Orbitz, and Perl's done alright by us. So far, that is. I always vaguely worry about the "non-standard technology" I use here, though. Is that such a valid worry, or am I just swallowing vendors' marketing pills like our clients? Because the "standard" just happens to be the buzzwordy things that a number of companies sunk money into and work hard to justify.
But, hell, someone had to have started creating something alien and new to come up with what's "standard" today. I seem to see stories from time to time about companies whose "secret weapon" is just such a "non-standard technology". They avoid many of the pitfalls that the herd faces by taking their own path, but trade them for new ones. There's risk in that, but then again there's risk in everything with a potential for gain.
Then again, there's the argument against wheel reinvention. I seem to like reinventing wheels sometimes for the hell of it, simply because I want to know how wheels work. Sometimes I even feel arrogant enough to assert that I can make a better wheel. But there is a point where just buying the thing and moving on is the smart option.
Oh well... I've come to no conclusion. But I'm still writing Perl code in my xemacs window today, and about to get back to it when I hit the "Post" button. And things seem pretty good here-- I mean this company managed to claw through the wreckage of the dot-com collapse and still edge toward a profit. We lost more clients due to their bankruptcy than through customer dissatisfaction.
I suppose I can at least say my choice of Perl, if not a secret weapon, didn't break the bank. :)
[ ... 1003 words ... ]
Jotting down some wishlist ideas for a next iteration of a linkback implementation and/or service.
This reminds me: I want to borrow Marc Barrot's activeRenderer code, combine it with maybe a nice ?JavaScript UI or at least Wiki markup to produce a simple web-based outliner. I'm sure this has been done before.
[ ... 53 words ... ]
From Chris Heschong:...While I don't believe it's 100% done, I've put up the code to my new pet RSS aggregator here for the moment. More to come shortly.
A nice, simple RSS aggregator in PHP that seems to run nicely on my iBook. Planning on poking at it some more, so I hope the alligator is of the non-bitey variety.
As Rael's little blosxom has hinted at, OS X has the potential to be the perfect end-user desktop website platform. I even had Movable Type running on it without much fuss. If only Apple had shipped with mod_perl and PHP modules active in Apache, it would be that much more amazing. I suppose that's easy enough to rectify.
Makes me feel strange running Radio UserLand on my OS X iBook, besides the CPU consumption. So much duplication of what's already there. Of course, there are the plusses of cross-platform goodness, integrated environment goodness, and things that just feel generally slick about it. Eh, but I don't have to feel strange about that anymore, since I moved Radio to my Windows box. Now Radio fights with my PVR program for CPU. Grr.
I've been thinking about this lately, too: Cocoa GUI talking via XML-RPC or SOAP to a web app locally hosted. It's been mused about before, though I forget where. I seem to remember that Dave had mentioned a company working on something like this. Could be interesting.
Seems to me that the potential and power of OS X for these sorts of apps (ie. desktop websites, networked info filters, etc...) has barely been tapped yet.
Unix on the desktop. Really. Who woulda thunk it?
[ ... 310 words ... ]
We discover all kinds of harm done to ourselves by environmental pollutants, decades or centuries after the fact. What if someday we discover that mass media and consumer culture, as we know it, is literally detrimental to one's health?
From Pravda.RU: NEUROLINGUISTIC DEPROGRAMMING(NLDP). NOUS-VIRUSES - A NEW THREAT FOR HUMANITY:... There is ... danger [of the deliberate using NLDP for harm]. ... NLDP-effect arises ... when a person is plunged into the intensive field of influence received by the optic, acoustic, kinesthetic perception ducts. ... often called TV programs, listening to the music, moving in the space of different texture, contacting with technical devices, etc. ... In some industrial countries such aphasia disorders as dyslexia and agraphia ... are unaccountably widespread. This "aphasia epidemic" can be easily explained by NLDP-effects. ... in the communication informational field certain informational-semantic blocks circulate. I call these blocks NOUS-VIRUSES. They get into the brain of a child or an adult, and, if his "anti-virus" defense does not work, the result of the destruction is a psychological disorder, which is not accompanied by the organic affection of the brain. ...
In case the awkward translation threw you for a loop, what this author is basically saying is that there are certain "idea viruses" circulating in our surroundings which make it past certain mental barriers ("anti-virus" defense) to cause mental disorders such as dyslexia, aphasia, and agraphia.
Sounds very Snow-Crash-like. Later on in the article, the author suggests establishing a new branch of science ("NOUSEOLOGY") to deal with these things. Maybe the translation missed it, but I don't suppose this author has heard of memetics...
Anyway, no research is mentioned to prove the claims, and there's nothing else to convince me that this is anything other than a wild rant... but the idea is interesting. Another Cluetrain tie in for me, at least in my head: What if some day, communicating to humans with a human voice (whether literally speaking, or in other channels) is determined to be the only medically safe way to communicate? :)
I'd like to think our minds aren't so fragile, though.
[ ... 351 words ... ]
Still working on getting all the bits of this site working again on the new host. One thing in particular that's broken are my beloved referer scripts.
But, I'm working on replacements in PHP. Noticed that my linkback scripts are linked to and described on IAwiki. Also notice some decent wishlist ideas for linkback improvements-- such as first/last referral date and link karma. And of course there are the improvements I've been meaning to make-- such as metadata harvesting from referrer pages and some improvements on filtering out some bogus/unwanted links (ie. Radio UserLand aggregator links). Might also be nice to allow someone to submit URL patterns they'd like excluded-- that is, if you link to me and don't want me to publish the linkback, you can submit a URL pattern for your site.
Have also been thinking of throwing it together as an open service, like yaywastaken.com's Link Feedback and Stephen Downes' referral ?JavaScript-includes. I can offer the service, and the code. The only drawback is, well, what might it cost me to offer others a free lunch if the service actually happens to be good. :)
Need to keep thinking about colocation.
[ ... 225 words ... ]
From Aaron Swartz:Here's an annotated version of the schedule from the Emerging Technologies 2002 conference. Under each session are links to the blog entries about that session. If I didn't include yours, send me an email...
You know what would rock for something like this? Provide a conference schedule, with each event in the schedule as a URL-addressable page or anchor within a page. Tell bloggers to link to those URLs when blogging about a particular event. Grab referrers and display links back to blog entries on those pages and on a summary page like Aaron provides.
Automatic conference annotation, and you don't even have to worry whether Aaron included your blog entry or not.
[ ... 115 words ... ]
Oh... I'm looking around for some sample code & docs for this, but maybe someone out there could drop me a few quick pointers:
I'm using Mac OS X. I have a Griffin iMic and a D-Link USB Radio. I can control the radio with DSBRTuner (with source code!) I thought that that would be the hard part. Now, what I want is a simple way to record sound to disk in AIFF format, preferably from the command line or at least with source code. I've tried a few other sound recording apps, but they're all mostly inadequate and overkill at the same time. Most of them won't record to disk, so capturing 4 hours of audio into memory hurts a lot.
I want to, in part, record radio shows with cron jobs. This shouldn't be rocket science. So, anyone know how to write a simple audio-to-disk app for OS X?
[ ... 152 words ... ]
So, I feel really out of touch. Seems like the majority of the authors on my news aggregator scan were all blogging from the O'Reilly Emerging Technology Conference this week. For some reason, I hadn't even heard of it until last week. This mystifies me. I can't believe I hadn't checked this conference out long ago and found a way, by hook or by crook, to get my butt over there. Seems like they covered an alarming number of the topics about which I'm fascinated. But, beyond the content of the conference itself, I would have loved to witness firsthand the phenomena of an audience full of bloggers tick-tacking away in realtime. And I so would have been running EtherPEG on my iBook like Rob Flickenger was.
It's been forever since I managed to get out to a technical conference. Not that I managed to globe-trot with any great frequency before the Internet bubble burst, when money was flush and expense reports were easy, but I was starting to feel like I was making inroads into a community. Now I feel cloistered in over here at my company and I don't know if my employer necessarily sees a value in me attending things like this. Marketing and sales make heroic efforts to streak around from coast to coast-- man, I don't envy them-- but I always stay here. Sometimes I wonder if it's because they're afraid I might let some of the mojo slip. But that's being pretty presumptious of the quality of the mojo I make here. :) (For what it's worth, there are nervous chuckles when I talk about Open Sourcing bits of my work.)
This is starting to sound like spoiled geek whining. It isn't that I want the company sugar-daddy to fly me to Milan every month-- I just start feeling a bit isolated and claustrophobic working with the same few dozen people, only a tiny handful of whom are actually technically-minded, week in and week out. So it's nice to feel a part of a wider community of like- or at least relatedly-minded people who are passionate about this stuff.
I'm an obsessive nerd. This is what I tell people who ask me, "Don't you get tired doing this all the time," or, "Why do you have more than one computer?" When talking to myself (as I often do) or to other geeks, I call it passion. I appreciate passion for its own sake, and I love talking to other impassioned people.
I always try to be tenative about my pretensions, but here goes another one: All the way back to when people were dingy, loin-cloth-clothed stereotypical and mythical cavemen sitting around comfy fires, there was always some oddball or scrawny thing who insisted on playing around at the edge of the firelight and further. Or banging around with an odd pair of rocks, making sharp things.
I want to hang out more with my fellow rock bangers.
[ ... 494 words ... ]
Whew. Been swamped this week, with work and with life in general. So, sadly, 0xDECAFBAD got a bit neglected.
When last I was working on things, I was in the middle of some decent-sized reworks of various parts to go easier on the servers and do things in a smarter way. Amongst all that, I notice that since my suspension the admin of my web host has been poking in from time to time and still tinkering with my site. This week they've been doing things like turning off execution permissions site-wide (and therefore disabling all scripts here) and shutting off various cron jobs and calling it abuse-- eg. a nightly tarball of my site, to be scp'ed down by a home machine's cron job later in the night. Supposedly they have backups, but I don't.
On the one hand, I understand an admin wanting to maintain the performance of a server he owns. On the other hand, I'm a tenant. Does your landlord continually come into your apartment when you're not home, without notification? Does he or she wander around, unplugging your clocks and appliances, shutting off your heat while you're gone? I could understand if the apartment was on fire, then some immediate action is required. But you know, I'd just like to have a little notification.
Moving on...
[ ... 222 words ... ]
Starting to think about this, too: What's better to use? an IFRAME, or a ?JavaScript-powered include? I can see elegance and hackishness in both.
[ ... 503 words ... ]
Hmm, looks like I was completely wrong when I wrote that the post-hash bit of referring URLs weren't showing up in my referral logs. Duh. I see them right in my "Today's Referrers" block on my site's front page, and a quick SQL query shows me tons of them. It'll be easier to linkback-enable Radio UserLand blogs than I thought.
[ ... 68 words ... ]
Just noticed that Stephen Downes emailed me about his implementation of a Javascript-based referrer linkback system. I'd been planning to get around to making one inspired from our blogchat, but he's got it first. Cool. :) Looks like Jon's picked up on it, too.
Jon muses:I haven't yet looked into what it will take to make the reporting item- rather than page-specific. It's doable, I'm sure. Thanks, Stephen! A ?JavaScript-oriented solution like this will appeal to a lot of Radio users.
The biggest issue I see for Radio, obviously, is that the style there is to have many blog entries on one page for the day. Permalinks are anchors within those pages. However, I haven't seen browsers reporting the post-anchor-hash info for referrals. At first though, one would need to have Radio spew blog entries into individual files to make this JS linkback scheme work at per-entry granularity. Otherwise, I'd love to see this work for Radio. I'd also love to see it woven with community server services.
A few brief musings on the referrers script itself:
Hmm, haven't seen cgi-lib.pl used since my Perl 4 and pre-CGI.pm days. I'd forgotten how serviceable the thing still is.
I like get_page_title(). It's a start on what I was musing about over here.
I want to steal this, maybe transliterate it into PHP (since my webhost frowns on my CGIs now), and hook it up to a MySQL database. Stephen doesn't want to host the world's referers, but I wonder how mad my host will get if I open mine up. :) Would make for some neat data to draw maps with, but probably shouldn't do things to make myself an even more annoying band practicing neighbor.
[ ... 286 words ... ]
Had a busy weekend living life, entertaining the girl, and cleaning my cave. A few quick things, if only to remind myself to remember to think about them:
Inspired by a suggestion from Eric Scheid to move from my server-included blocks to client-included blocks via ?JavaScript, I did a little exploration into the idea and whipped up a quick, generalized script to mangle the contents of any given URL into a document.writeln(). Not sure how robust this thing is.
Also, not sure how widely supported the JS-include hack is. On the other hand, Stephen Downes had made a good point in my blogchat the other day concerning JS-based hacks: my visitors can turn them off by disabling Javascript. Having been employed in the field of internet promotions these past 6 years, this seems like a nightmare. But, having been reading the Cluetrain Manifesto and following smart blogs, I start to think this is a Good Thing.
I see that JanneJalkanen and crew are musing out an update to the XML-RPC wiki interface. Having worked on my own implementations of this interface, I need to keep an eye on this, even if I can't quite be as active as I like.
HTTP Extensions for a Content-Addressable Web seems hot as hell, especially for the future decentrallized publishing world I'm dreaming of.
I'm updating my home linux box, Memoria, with Debian, defecting from Mandrake Linux. Wish me luck. Oh, and the HD in the machine has a few cranky parts from having been dropped. Wish it luck.
Running a telnet BBS at telnet://deus-x.dyndns.org:2323. The domain may change to bbs.decafbad.com soon. I miss the BBS days. I may bemoan the loss of local community gateways onto the 'net someday soon. I'm using Synchronet on a poor overworked Pentium 70Mhz PC running Win98, on which I also inflicted Radio UserLand for the time being. No one really calls on my BBS. I've been thinking of hosting the UNIX version on Memoria.
Thinking of trying out Radio UserLand on Memoria under Wine. I've seen mutterings which claim that this is possible. Anyone?
I want to wax pretentious with a few musings on the Singularity, birth control, anti-biotics, glasses, and self-modifying code. I might not get around to it, though.
Wasabi-coated peas are at once wonderful and terrifying.
[ ... 383 words ... ]
Speaking of software I want to get deployed at work (ie. time tracking), another thing I want to take the plunge with is k-logging. Basically, I want some software to give every person here an internal blog or journal. Immediately, I want this to capture internal narrative. A future subversive idea I have for it is to eventually pipe some of these internal entries out to our public company website. (Yes, I'm reading The Cluetrain Manifesto again.)
I've gotten almost everyone here on the wiki bandwagon, and we're using it regularly as a knowledge capture and collaboration tool. So, they're used to me throwing odd new tech at them. Unfortunately, the wiki isn't precisely suitable to what I want for the k-logs. These are my requirements so far:
Must be dead simple to use in all aspects, so that it sits far below the laziness threshold it takes to record an idea or narrative as it occurs.
Rich set of categories and metadata by which an entry can be tagged. (ie. On what project were you working? On what project task? With what products? How much time did you spend?)
Arbitrary views on weblog entries, querying on category and metadata, maybe even on full-text search. I want to be able to weave together, on the fly, the narrative of any person, project, product, or any other topic.
I'm looking, hopefully, for something free. At the moment, I'd have a hard time campaigning for the purchase of a fleet of Radio UserLand subscriptions for all of us, unfortunately. Someday, perhaps. (I could just imagine the insane possibilities of a Radio on every employee's desktop.) But, is there anything out there like this now? It's simple enough that I could probably roll my own in a weekend or less, but it'd be nice to jump on the bandwagon of an established k-log tool.
Also really looking at more ways to lower the laziness threshold. We just converted the entire company over to using Jabber as our official instant messaging platform, so I thought it'd be pretty keen to have the k-log system establish a presence to receive IM'ed journal entries. Along the lines of the wiki adoption, I'd probably have to get everyone to embed a certain style of keywords or some other convention to get the k-log system to pick up categories.
Or, to make it even lazier, could I get the k-log system to automatically discover categories by the mention of keywords? Hmm, this could be fun.
Anyone out there working at a k-logged company?
[ ... 1018 words ... ]
Oh, and I've swung away from keeping track of it, but I need to get back to looking at masukomi's about-time time tracking software.
[ ... 25 words ... ]
Noticed two things from Mike James this morning:
An interesting melding of weblog and wiki over at www.tesugen.com. The combination of Blosxom, which elegantly composes the weblog from a simple pile of files, and UseModWiki, which can cache its pages in a simple pile of files, makes me think about the combination myself... (Oh, and TWiki does this, too, not in caching but in the storage of page content in the raw.) I could make Blosxom search for files by regex (ie. Blog*) and post to the weblog in ?UseModWiki with a naming convention of pages. Seems neatly elegant.
And the second thing are the MovableWorksOfArt that Mike cites. Again, simple and neat elegance. I'm with Mike: I've got a lot to learn, and a lot to strip down from the design of this site. I also really need to dig into some proper CSS. Mark Pilgrim's CSS magic shames me.
[ ... 218 words ... ]
Yay! It appears that the new Multi-Author Weblog Tool does almost exactly what I'd mused about doing as a GroupsWeblogWithRadioUserLand, were I to ever get around to it. Been drifting away from Radio lately, but I need to get it working on a decent machine. It ate my iBook CPU time like dingoes eat babies, and on my home desktop Windows machine it would eat enough CPU to cripple my PVR functions. I'd like to see about either moving that PVR function to a Linux box, or trying to run Radio under Wine.
[ ... 94 words ... ]
0xDECAFBAD was out cold today for some hours, due to the suspension of my webhosting account.
Seems the SSI-and-CGI combination I was using around here had turned into a monster, and the sysadmins decided things had gone rogue on my site. So, I get suspended, to be later restored with a lecture on the nature of CGI. My scripts were called "fucking insane" by the admin who finally gave me back my keys. And, on top of it, I got a lesson in UNIX file permissions while he was at it.
Well, the thing is... of course I understand CGI, and the expense of launching external processes. And I gathered that the SSI-and-CGI combination was braindead at the end of the day. And I understand the necessity for restrictive file permissions. But still, even with all that, I let things get sloppy.
This is vaguely embarassing.
So, today I hastily reimplemented everything using that SSI-and-CGI scheme in PHP. I'd started leisurely on the PHP replacements this weekend, but this was a kick in the ass to finish it. Almost every *.shtml page is a *.phtml page now. I rewrote my referral link listing code, as well as my RSS feed display code, in PHP functions. There are still some places where things are broken (most notably the referrals in the wiki), but I'll get around to fixing them. Not too bad for starting from zero PHP exposure (somehow) until this weekend.
I'd like to think that this won't happen again, but I suspect it might.
The problem is that this site is my mad science laboratory. I mix things together, set things on fire, and occasionally have something explode. I get enthusiastic about seeing what I can do, without a whole lot of regard toward safety or keeping the wires out of sight. I figure that I'll tighten up the bolts and polish up the shells of the interesting experiments, and just archive the ones that turn out boring.
Occasionally, this leads to me playing loose with security and resource conservation. I really need to watch this more, since the sysadmin reminded me, "Remember, your account is on a multi-user, time-sharing UNIX operating system." My first reaction to this was, "Well, duh," but then my second reaction was... "Oops." It's not that I don't know these things. It's just that I get quite a bit ahead of them in tinkering.
I have to try to find a balance between boiling beakers and safety goggles.
And, I wonder if this webhost is the right place for this site. They certainly don't have the world's best customer service. It's low touch, high grumble BOFH service. It appears that the people running the show are experts (I see the name of one of the admins all over various Open Source projects' patch submissions), but don't have a whole lot of time or patience for bullshit. But, I pretty much knew that going in. It makes things cheap, but it's also a bozo filter.
And with some of the things I'll be doing, I'm likely to be a continual bozo.
The best thing would be, as DJ suggested earlier today in blogchat, to find a cheap-cheap colocation somewhere. It's not as if I don't have machines to spare-- I just need a safe, constant full peer and static IP net connection. I'd love to have something I could run persistent servers on, play with a few different app servers, a couple generations of Apache, etc. The things I want to do can be done safely, given that I pay attention, but I doubt that they will make for a quiet neighborhood. On any server I play, I'll be the noisy bastard down the street blaring the metal and practicing with his band every night.
Hmm.. have to think about that co-lo thing.
[ ... 726 words ... ]
Oh, and Ken ?MacLeod was another visitor to my blogchat today. Along with humoring some of my RESTian musings (which I think I understand much better now, thanks), he'd observed the multiple links back to the same blog entries awhile back. We chatted a bit about the linkback thing and the scalability of BlogVersations. Talked a little about the robot link detective I just babbled about.
Also, he pointed me to Purple, which appears to be an decent system to use for arbitrary mid-document linking in a blogspace lacking universal XHTML and XLink adoption. This means something, too.
Time to go home.
[ ... 103 words ... ]
I just noticed Ghosts of Xanadu published on Disenchanted, where they make an analysis of the linkback meme and it's historic roots. They cover pretty much all the big ideas I've been poking at in my head, and give props to Xanadu. Heck, they even mention Godel, Escher, & Bach (which my girlfriend & I have started reading again) and ant scent trails.
So along with the ?JavaScript-powered linkback thing, something else I've been thinking about is a little semantic sugar to add to the mix. I keep forgetting to mention it, but what makes Disenchanted's linkback system very good is that Disenchanted "personally visits all pages that point to us and may write a short note that will accompany the returning link." They manually visit and annotate their links back, whereas my site just trundles along publishing blind links.
I'd like to change that with my site. The first thing I'll probably do is set up some triggers to track new referring links to my pages, and maybe give me an interface to queue them up, browse them, visit them, and annotate them.
But the second thing is something that would require a little group participation from out there in blogspace. It might not work. Then again, it might catch on like crazy. I want to investigate links back automatically, and generate annotations. I'm lazy and don't want to visit everyone linking to me, which sounds rude, but I think that the best improvements to blogspace come with automation. (In reality, I do tend to obsessively explore the links that show up in my referral log, but bear with me.)
I can respect the manual effort Disenchanted goes through, but I don't wanna. So, I want a robot to travel back up referring links. What will it find there? Well, at present, probably just an HTML page. Likely a weblog entry, maybe a wiki page. What can I reasonably expect to derive from that page? Maybe a title, possibly an author if I inform the robot a bit about what to look for. (ie. some simple scraping rules for blogs I know regularly link to me.)
What else can I scrape?
Well, if bloggers (or blog software authors) out there help me a bit, I might be able to scrape a whole lot. I just stuck a Wander-Lust button on my weblog, and I read about their blog syndication service. You can throw in specially constructed HTML comments that their robot can scrape to automatically slurp and syndicate some of your content. Not a new idea, but it reminds me.
So bloggers could have their software leave some semantic milk & cookies out for my robot when it wanders back up their referring links. Maybe it could be in a crude HTML comment format.
Or maybe it could be in a bit of embedded RDF. Hmm. Anyone?
What would be useful to go in there? I might like to know a unique URL for the page I'm looking at, versus having many links back to the same blog entry (on the front page, in archives, as an individual page with comments, etc.) I might also like to know who you are, where you're coming from, and maybe (just maybe) a little blurb about why you just linked to me. I'd like to publish all these things along with my link back to you, in order to describe the nature of the link and record the structure we're forming.
This seems like another idea blogs could push along, semantic web tech as applied to two-way links.
Of course, the important thing here is laziness. I'm lazy and want to investigate your link to me with a robot. But you're lazy too. There's no way that you'll want to do more work that I do to provide me with the data for my robot to harvest. So... how to make this as easy as making a link to me is now-- or better yet, can we make it easier to make a richly described link? That would really set some fires.
[ ... 796 words ... ]
I meant to post a quick thank you to Jon Udell for the link in his recent O'Reilly Network article, Blogspace Under the Microscope. But beyond the fact that he mentions me, I really like the biological metaphor for blogspace he explores there.
In the short time I've had this blog out here, I've tossed in a few handfuls of small hacks that have incrementally connected it to others and made discovery of some connections automatic. What I'm doing is mostly inspired by what I see other bloggers doing. Something about all this feels very different from what's happened on the web thus far. I don't have, nor likely will ever have, one of the more popular blogs on the block-- but for the short time I've had it, this thing has gotten more connected than anything else I've ever done on the web. It's certainly by no genius of my own that this has happened. There's something big to this.
Pardon the pretention, but it seems that there's this "Reverse-Entropy" going on here through these incremental tweaks and the construction of these small, elegant connecting channels between walls are what will very shortly raise the level of blogspace to.. what, a singularity? Not sure, but it's seeming more and more like David Brin's Earth. (I've got to read that again and pull some quotes.)
So (back to practical matters), Stephen Downes dropped into my blogchat for a visit and we chatted briefly about the linkback meme. One thing we'd touched on was a fully ?JavaScript exploiting referrer service one could use on a site where one could not host dynamic content like SSI, PHP, etc. Jon also touches on pretty much the same thing in musing about a backlink display in Radio.
More centralized services bug me-- I really want to see a completely decentrallized blogspace. But, it's baby steps that need to be taken. Since there's no P2P killer app plumbing for blogspace yet, we need full peers to get hosted.
Some, like mine, are hosted where dynamic content is available and I am capable (and willing) to hack at the dynamic bits. Others are hosted where content must be static, and others have owners who either can't or don't want to bother with hacking on the plumbing. So some central services are still needed to prop up blogs. Baby steps. Get the tech working, observe the flying sparks, and get bored tinkering with what doesn't work.
But it would be brilliant if someday soon, something like Radio can become 100% decentrallized, with installations collaborating to form the space via firewall-piercing instant messaging conduits, pub/sub connections, content store-and-forward, distributed indexing, and the whole utopian bunch of Napster dreamy stuff.
Okay, back to work.
[ ... 518 words ... ]
I have 3 blogs right now, including this one. The other two are 1) on LiveJournal and 2) managed by Radio UserLand.
My Radio blog has been pretty dormant of late, since I never quite got completely pulled into it or migrated my LJ or MT blog to it. Instead, LJ seems not itchy enough to abandon (and I have friends there), and MT seems comfy enough for now. So, Radio remains a place of bunsen burners and exploding beakers for me for now. (This is not a complaint, this is a cause for gleeful and evil rubbing of hands together.)
My LiveJournal, however, was my first successful blog. And by successful, I mean that I managed to keep writing there, usually trying to babble more at length than just copying a few headlines. My writing there is pretty random, by intention. I'd originally started it to supplement my daily writing in my paper journal, as some other outlet for words to keep me writing and maintain my ability to string more than two words together coherently.
On LiveJournal, I'm more likely to rant about things like religion and touchy issues. I'm also more likely to talk about my girlfriend and other events in life more interesting to my closer circle of friends.
I consider 0xDECAFBAD to be my nerd-blog, or my "professional" blog. It's where I'm more likely to ramble about things in my life as a geekish craftsperson. I could draw a Venn diagram, but suffice it to say that I think there are different, but overlapping, audiences for my high-nerdity versus my more personal ramblings.
Does anyone else do this? I'm sure I'm not alone in cordoning my blog faces off from each other. But should I feel the need to separate things like this? Although I can't find a link to it, I seem to remember Shelley Powers writing about tearing down her cordons between her nerd-core and normal-person blog sides. Of course, I try to thin the barriers at least by displaying my LiveJournal RSS feed over on the side as a "sibling" blog.
On the one hand, its a strange form of self-classification. On the other, though, it seems to work for me. Visit 0xDECAFBAD to see my vaguely professional high-nerdity. But if you want to get closer to me as a human being, come visit my LiveJournal and see me and my place in the community there. If you really want to know me... well, email me or maybe IM me. And maybe, just maybe, if you happen to be in town, let's head down to the pub.
[ ... 592 words ... ]
Okay, so it's a given that I'm not giving up my PVR soon. So, which ones work best? And why?
So far, all of mine have been homebrew, thanks mostly to ATI video cap / tuner cards. I've never owned a ?TiVO, although I've lusted over them. But my current setup seems serviceable. I managed to record the entire run of the third season of Buffy in rerun onto VCDs with the ATI Multimedia Center software. (No cracks on the Buffster. If you don't like it, try s/Buffy/Babylon 5/ or maybe s/Buffy/Nova/ in your head.)
Now, I'm looking to replace the Windows this runs on with a Linux install. I already record radio shows under Linux with a PCI radio tuner, and under OS X sometimes with a USB FM tuner. So now I see this VCR HOWTO which claims: This is a guide to setting up your GNU/Linux workstation as a digital VCR using the video4linux driver and a supported tuner card. A section has been added for creating VCD's that can be played in any DVD/VCD player as well.
Sounds precisely like what I'm doing right now. And I think that my ATI All-in-Wonder Radeon card can be supported under Linux. If not, I have a backup BT848-based Zoltrix TV tuner that works for sure, but that one only seems to have mono audio, unfortunately.
Has anyone put together a working Linux setup as described in the HOWTO? If so, how do you like it?
On the other hand... Should I still think of getting a ?TiVo? What's so special about it, other than dead simple ease of use? I'd want to immediately crack it open and start hacking more HD space into it, as well as TiVo ?AirNET Ethernet Adapter Board. But I think my Linux box will do this, and more. Though, I'm not sure if Linux supports the TV-out for my ATI card. I've also heard that ?TiVo captures closed captioning. Eh, neat, but I don't need it. Not at the moment, anyway. Then I hear about things like SonicBlue being ordered to spy on PVR users, and I feel much safer having a home-cobbled PVR.
What d'you think?
[ ... 711 words ... ]
Earlier last week, I'd ranted in my LiveJournal about the head of Turner calling me a thief. Now, I'm reading what Mike James has to say about what Brad Templeton has to say about the ?TiVO, PVR's, and what they are gonna do.
Brad offers up a few very good suggestions-- ways to offer more options with regards to TV funding, ways to mix up and better target ads and ways to buy out the ad time. Some of the "enter the keyword from the ad" suggestions strike me as eerily similar to the ways warez and porn trading servers on the Hotline network. Go visit 3 sites, usually casino sites and other banners, spend about 30 seconds exposed to each site searching for a certain keyboard, come back to the warez/pr0n server with your keywords in hand.
Again, the porn leads the way. :) Well, sort of. The Hotline servers are pirating the porn industry, but porn tends to always be one of the drivers of tech. I wonder if purveyors of porn might not also be the first to hit on the new business model that rakes in the cash from what's coming?
I can't help but think of this in terms of golden geese. TV studios have had a golden goose in advertisers, and she's laid wonderful eggs for decades. But now the old gal's tired and the eggs are getting smaller and less shiny. Must be something in the water or the goose feed that's changed. Seems that there just might be another goose out there that'll lay even bigger eggs. Not only that, but I hear that this new goose might even deliver the eggs right to them, and maybe even thank them for it. But, rather than questing and finding this new kind of goose, they're trying to sow the goose feed fields with salt and poisons. And they're looking for thicker chains for the current goose's ankles, and reinforcing the bars of the cage.
I really must be missing something. I can't help but think that consumers wouldn't mind being treated like customers, finally, and not as assumed thieves. I have to think that some very smart people work in the entertainment industry. At least a few of them must have read the Cluetrain Manfesto and come away with something. Is this just naive to think? Seems vaguely incomprehensible to me that fear has them working this hard to maintain an aging business model, where the rewards would be staggering if they put that much effort into exploiting a new one. And they'd be praised instead of pissing everyone off.
Wish I could remember the quote (was it Heinlein?) about companies and their making money, which basically gets summed up in Mike's quoting of Spidey, "I think I missed the part where this became my problem." It's already been heavily quoted, but it's worth repeating.
[ ... 483 words ... ]
I just grabbed Micropoll to play with from technoerotica.net
Let's see if this works:
Kinda fits with the other little SSI widgets I've been cramming in here. Now if only I could figure out which one is delaying the load of my main page. Aw hell, I was going to throw it all into PHP anyway.
[ ... 57 words ... ]
Tinkering around with CSS again for this site. Getting a bit busy and crowded around here, and Liorean had mentioned to me in a visit to my blogchat that things were a bit hard to read and for want of white space. I think I agree on this. Though, I don't want to explode everything out with huge fonts and spacing... Hmm.
Anyone have some hints, suggestions, or complaints about how things look now?
[ ... 75 words ... ]
I've been trying out WinXP on my token Wintel box at home, and it really doesn't impress me. I was running Win2K, and Win98 before that, and I can't really see the big deal.
To be fair, I can say that I don't make fun of Windows for crashing as much anymore, although XP did just crash this week with a big fat bluescreen which took out the entire body of preferences in my user account including all my digital VCR schedules. So that was annoying. But rare now, anyway. And most times it can be blamed on drivers or non-Windows software... but gah.
But as for the rest of XP... I can't stand Luna. I turn off all the bells and whistles until it starts looking like Win98. I reduce my Windows Explorer down to about what it looked like in '96, just a folder tree on the left and detail-view on the right. Most of the other "helpful" features of WinXP just annoy the crap out of me. Am I missing the benefits of XP? It just really seems like hairs are being split and sugar's being poured in since about 1998 with Windows. Maybe the thing is that no one's come up with any new dramatic, paradigm-shattering new things, so incremental perfection is all that's left for Windows.
So here's what I'm getting to: I'm thinking of downgrading my home PC to either ?WinME or Win98, and I might just stop the upgrade cycle there. And I'll stop it for good unless I see some dire need to upgrade my Microsoft OS. I don't seem to have any software which requires WinXP. Rarely, something requires Win2K or NT, but most of that stuff I replace with a Unix app. At work I've been running Win98 in a Virtual PC instance on my OS X machine, and all my daily-use software runs fine on it. And it really doesn't crash all that much.
And this isn't just an anti-Microsoft thing. Well, to be honest, in part it is. And in part, I don't want my Windows habit to suck me into recurring Microsoft payments, should they perfect the licensing enforcement and stop letting me buy the thing once and make me sign up for a monthly fee. Unless they can start showing me something like the Radio UserLand radio.root changes RSS feed, I don't see a benefit to me to pay on a subscription basis. I suppose their list of patches and things fits that bill, but it's not the same to me. With Radio, I see a stream of improvements and new features. With Microsoft, I see largely a stream of fixes and replacements for things they've already sold me. But, I suppose it's apples and oranges. Radio can afford to bootstrap and occasionally break, whereas Windows must strive to be solid as a rock.
This makes me feel vaguely luddite.
[ ... 698 words ... ]
My webhost had a bit of an outtage, and the machine on which this site is hosted suffered a nasty hard drive crash. Things were down for about a day or so, and when they came back up most everything was broken. Seems that the sysadmin of this server added a few security improvements, such as disallowing execution of CGI scripts with dangerous permissions, which revealed my sloppy and "atrocious" (the sysadmin's word) use of them.
*gulp* Bad me. Shows that it's been a long while since I had a website on a multi-user machine-- not that that's a very valid excuse, but it seems less urgent to tighten up permissions when you own the machine, have a small and trusted team working on it, and it sits behind two firewalls.
Hmm. I need to get schooled in some security mojo with the quickness. Loving the Wiki Way is one thing, but bending over like the goatse.cx guy (no, I'm not linking to it) is another thing altogether.
[ ... 169 words ... ]
I &heart; the Internet and weblogs.
What happens when one of my favorite bands' main man, Mike Doughty, and one of my favorite ex-Star-Trek-survived-the-80's actors, Wil Wheaton, collide in blogspace and discussion groups?
Well, first no one believe's it's really Wil Wheaton posting to the DG. But then, when everyone realizes that yes, in fact, it's him, Mike himself posts the moral of the story:so the flip side of the don't believe what people
tell you on the internet lesson is--you know,
people on the internet might actually be who they
say they are. how bout them apples?
Not to have a Jerry Springer moment here, but: Yes, how about them apples? It's the new internet, where some people really are who they say they are, even if possessed of some vague degree of celebrity. And not only that, but your ears turn red and ring when someone's talking about you.
Now, maybe if I say Wil Wheaton's name three times in a Beetlejuician manner, he'll show up over here too. :)
[ ... 172 words ... ]
Okay, I'm done thinking and writing about REST for the time being. I think I understand it, but it doesn't seem to light any fires for me yet. I'll just stuff it away into my utility belt and keep it in mind in case the need for a REST-headed screwdriver comes up, or until I discover that my RPC usage causes cancer.
What's much more exciting to me at the moment is whitelist-based spam filtering, and even more so is using RDF to share whitelists. I really need to look more into this FOAF thing over at rdfweb.org.
One project I've been mulling over is how to replace something like my user info page at LiveJournal with something web-wide and decentrallized. RDF seems like a lead on that for a shared data format for personal metadata. I want the friends and friends-of, and especially the interest links that let you pivot on interest phrases to view a list of others who list the same interest phrase.
[ ... 228 words ... ]
Here I am, a Busy Developer trying to work his way up to being a real Computer Scientist. In doing this, I subject myself to things like RPC vs REST. I see apparently intelligent people vehemently disagreeing about something, I figure there's something to it. This may be naive. I hope that by hurting my brain with this noise, I might take some of the hunch out of my back that gets me just one more caveman level up the evolutionary chart. I hope you all don't mind hearing my grunts and unks.
Dave linked to me with an Oy. Was that from my quoting of a quoter quoting? Or is that an Oy on this REST thing getting all outta hand? :)
Well, here it goes again: I found Gordon Weakleim linking to me from my referrers (yay for referrers!), where quotes someone on a discussion forum as having said "REST, I'm afraid, is unlikely to get anywhere until it is presented in a more utilitarian fashion. It feels much too much like a philosophy or religion or something." And I agree with this, too. I got introduced to XML-RPC via simple toolkits and real problems solved with satisfaction, and I'm learning SOAP slowly the same way. Gordon also captures some of my other sentiments.
I think I get REST now. Maybe. Between my last post on REST and finally finding and reading Paul Prescod's "REST and the Real World", I feel somewhat illuminated.
I also feel very, very behind. This has all probably been covered ad nauseum on mailing lists I haven't read yet, but this is what I thought on Paul's article:Using someone else's [RESTful] web service requires you to understand their data structures (XML vocabulary and links between documents). . . . RPC APIs merely hide the problem behind an extra layer of non-standardization. First you must figure out the method names available. Then you must still figure out the data structures that may be used as parameters. And then behind those data structures is the implicit data model of the web service.
Hmm. Yes, in an RPC API I have to supply my customer with my method definitions-- including their names, parameters, and return values. This seems directly comparable to supplying my customer with all the URIs exposed by my app's resources, as well as the data structures used by them.
How are these cases so very different?There is no free lunch. The biggest problem most will have with REST is that it requires you to rethink your problem in terms of manipulations of addressable resources instead of method calls to a component.
I don't want to rethink my problem, at least not without a clear payback. When I first learned to rethink my problems in object oriented programming, I got immense payback. I haven't seen the clear payback case for REST yet. So far, it looks like an interesting abstraction with a lot of vagueries, name calling, and intimations of harm and danger.
Of course you may actually implement it on the server side however you want. But the API you communicate to your clients should be in terms of HTTP manipulations on XML documents addressed by URIs, not in terms of method calls with parameters.
My customer doesn't want to mess with this, and doesn't want to learn about it.
Your customers may well prefer a component-based interface to a REST interface.
Yup, they do. My chances of altering their behavior is slim to none-- at least not without a clear case of payback to present.
Programmers are more used to APIs and APIs are better integrated into existing programming languages. For client-side programmers, REST is somewhat of a departure although for server-side programmers it is not much different than what they have been doing for the last several years, building web sites.
The server-side programmers I work with have been building CGIs and various server-side things which treat URI's as mere gateways onto their applications. REST is pretty different than what they've been doing for the last several years.
REST is about imposing a programming discipline of many URIs and few methods. RPC allows you to structure your application however it feels best to you. Let it all hang out! If a particular problem can be solved with RPC, and future extensibility and security are not going to be issues for you, you should certainly use the looser approach.
I still don't see the payoff of few methods with many resources versus many methods with few resources. Either way, should I change my application in the future I'll need to supply my customer with new data descriptions, or with new method descriptions. How does REST make me magically extensible? Am I not seeing something?
The security angle I can sort of see, given the already built-in ability of web servers and firewalls to control HTTP methods and URI accesses. But, most times I want my application to manage its security and access control, not the web server or firewall. Maybe this is a flaw in my application.
Anyway, the simplicity of REST feels like a possible elegance to me, which I like. Elegance feels warm and fuzzy, not itchy. XML-RPC is obviously a bit of a workable hack. Being able to RESTfully reduce my app down to database-like access via a web of URI resources seems neat. But, the whole REST thing feels like an inside-out turn of many things. This is not useful to me unless I can find some abstraction or toolkit to help me wire my apps up to things in the REST way. XML-RPC was quick for me to get hooked on, since it was a mostly drop-in solution with me writing only a few wrapper methods.
Now that I understand REST better, I see that I could possibly do most of what I do with SOAP and XML-RPC in a RESTful manner with a bit of brain bending. It reminds me of threaded versus async / event driven programming. But I don't know why I should bother: I'm still looking for the payback of REST and I'm still looking for the danger inherent in the RPC model.
[ ... 1046 words ... ]
Chris Heschong writes: Ken ?MacLeod notes that, in regards to REST, "the only thing holding us back is a marshalling standard." I'd be a lot happier with REST implementations if this were the case.
(Whew, I think I need a convention for quoting quoters. Maybe a new language. I seem to remember hearing on the Todd Mundt Show that the Turkish language has a facility for specifying whether something you're saying originates with you, or whether you heard it from someone else...)
Anyway, since Ken ?MacLeod had taken the time to respond in some detail to a post I made asking about REST not too long ago, I thought I should come back around to it.
So I think my first confusion was with marshalling. This is why I like XML-RPC: I don't worry about much. As a client, I give it a URL and a method name, and then throw a pile of parameters for the method at it. As a server-side method, the server gives me parameters when it calls me, and I throw back a return value. The server takes care of turning the XML into my arguments, and my return value to XML.
In all the languages I've worked with it in (ie. Perl, Python, ?UserTalk, and AppleScript), this works conveniently well. I never actually pay much attention to the XML in XML-RPC. So, I was very confused in reading a few things about REST and not seeing much mention of this, other than along the lines of "Oh, well, you could go ahead and use XML-RPC libraries to build messages if you wanted to." Which begged the question for me: Why not just go the whole hog and use XML-RPC? (Or SOAP, for that matter, but that's another holy war I'm avoiding for the present context.)
Okay, so REST isn't about marshalling parameters. Then what is it about? Well, I think a bit more reading and Ken's response to me have helped illuminate me a bit.
The REST point seems to me to be that all operations being attempted by Web Services can be distilled into a few actions: retrieve, create, update, and delete. REST says that these fundamentals are already defined as GET, POST, PUT, and DELETE, respectively. I think. Is this right?
So, I apply these verbs to URI nouns. To concretize the concept: I recently wrote & exposed an XML-RPC API to a scorekeeping component on one of our promotions. Some of the methods of this API were along the lines of int points.get_points(string email), points.award_points(string email, int points), and points.create_points_account(string email). To make myself a new account I'd call points.create_points_account("deus_x@pobox.com") and then points.award_points("deus_x@pobox.com", 100) to drop myself some points in the scoreboard. Then, I would do points.get_points("deus_x@pobox.com") to check my score.
I'm afraid this example is too simple. Jon Udell wrote that he wanted to see the "stock quote example" retired for being too simplistic to stress the technology in mental experiments. Hmm. Oh well, let's see where it goes.
So, if I were to RESTify the above example, would the sequence of things be like a POST, PUT, and GET, all to a URL that looks something like:
http://myhost/promotion/players/deus_x@pobox.com/points
Whereas POST does the account creation, PUT updates the points, and GET of course grabs the points total?
Okay, maybe POST needs to post to .../players/deus_x@pobox.com with a request body specifying "points", to create the new URI? The request body of the PUT should contain a points value -- positive for award, negative for debit? And if the thing needed more complex data, I could use something like XML-RPC to encode a data structure as arguments, or as Chris Heschong wrote, use WDDX?
Do I get it? Hmm... okay, have to run to a meeting, but I wanted to post this and see if anyone could give me feedback on my understanding. I think I see how, if all resources are manipulatable in this manner, one could envision a more abstracted and uniform interface on web resources than a pile of published web services APIs. But... can it really be that abstracted?
Hmm.
[ ... 935 words ... ]
When I talk about Radio and my love/hate with it, this is one of the things I absolutely positively adore, fawn over, and plan to mimic in as many of my projects as I can where I can. Back when the Mozilla source code was first released, and I happened to be at a Q&A with some Netscape guys, this was the [#1](/tag/1) feature I pestered them to spend time looking into.
John Robb of UserLand points it out, in relation to .NET:[Alchin said, "]The hot patching technology will not find its way into the upcoming .Net Server family, but we have made progress on reducing reboots.["]
Radio already does this.
Yes, yes it does, and this is dead sexy. I love that the system is put together in such a way that this is possible. My monitoring of the Radio.root Updates RSS feed reminds me daily of where my $40/year is going.
Now, can we have Instant Outlines do this? :) Heehee.
[ ... 295 words ... ]
I just had to link to this: A coder's guide to coffee @ kuro5hin
I think I'm going to buy myself a french press tonight.
Oh, and just for fun, visit The Caffeine Archive.
[ ... 73 words ... ]
One more thing, directed at the Radio UserLand crew: With my recent discovery of and mania for referers, I've seen that Radio sends me people claiming to have come from http://radio.outliners.com/instantOutliner and http://frontier.userland.com/xmlAggregator, for I/O and news aggregation respectively.
Here's a wishlist idea: Make Radio send the URL to the user's blog instead of URLs to UserLand documents. While the current referer URLs tell me why I'm getting the hit, I'd like to have a better handle on from whom the hit is coming.
[ ... 85 words ... ]
Playing more with PHP, writing a replacement for ShowReferers. You can view the source of my first attempt ever at a PHP page, or view the results. I just replaced the front page sidebar referers box with an include to this page. Soon, I'll replace the entire front page template with one written in PHP, and I might add the sidebar stuff to all my blog entries. This is fun. :)
[ ... 72 words ... ]
Hmm. Okay, so Zoe looks promising, but.. umm.. I can't figure it out.
I added an IMAP account. Stuff seems to happen, which ends up in a lot of ?FolderNotFoundException and ?OutOfMemoryError exceptions to my terminal. No mail appears on the front page. I tried changing my SMTP server to use Zoe, and then was going to foward email to import it as the FAQ suggests, but umm.. to what address do I forward it?
Urk. This makes me feel dumb.
[ ... 82 words ... ]
Oh, and I bit the bullet and turned off the authentication requirement on the wiki. I've decided that ultimately I agree that LoginsAreEvil. I didn't really want to put up fences, or raise the laziness threshold. I mostly wanted to identify people, but I was mistaken. Now, I'd rather AvoidIllusion.
There still are a few fences, however. My reasoning is that my use of this wiki slides into the realm of cheap content management, and I don't prefer public input on certain things. A few pages are access controlled, such as the wiki's front page and my home page. For this purpose, there's an alternate password-protected set of wiki commands. The non-authenticated are under /twiki/bin whereas the authenticated set are at /twiki/sbin. Just as easy as putting an 's' in the URL.
Access to the authenticated commands doesn't necessarily mean you get to edit everything though. :) That's access control for you.
Eventually, maybe I'll drop the access controls too. I was also thinking of moving out of TWiki for another wiki implementation like MoinMoin, too. Still tinkering.
[ ... 1396 words ... ]
Via Prof Avery, I just found ZOE.The goal here is to do for email (starting with your personal mailbox) what Google did for the web... The Google principle: It doesn't matter where information is because I can get to it with a keystroke.
So what is Zoe? Think about it as a sort of librarian, tirelessly, continuously, processing, slicing, indexing, organizing, your messages. The end result is this intertwingled web of information. Messages put in context. Your very own knowledge base accessible at your fingertip. No more "attending to" your messages. The messages organization is done automatically for you so as to not have the need to "manage" your email. Because once information is available at a keystroke, it doesn't matter in which folder you happened to file it two years ago. There is no folder. The information is always there. Accessible when you need it. In context.
Rock on! I'm either terribly unoriginal or my mind is being read or there's just a common Alpha Geek wavelength I'm tuning into. By the description, this is precisely what I wanted to do with a PersonalMailServer. Getting tired of making folders, filtering rules, and MailToRSS needs a bit more work and tweaking to be really useful.
From the FAQ:Q: On which platform does ZO? run?
A: ZO? has been known to run on the following "platforms":
...
MacOSX 10.1.4, jre 1.3.1, Mozilla 0.9.9
...
Rock on.Q: How much does ZO? cost?
A: ZO? is free of charge for personal usage. Keep in mind, that you are getting what you are paying for... ;-)
Rock on.Q: Is ZO? open source?
A: No.
Awwww. That's no fun! I want to play! I don't see it within 5 minutes of installation, but I think this thing really really needs IMAP. IMAP would rock for both message import and external mail client access.
But, from the author's terse response to this question, I'm imagining there are many who've asked it and he's tired of answering why he's not being trendy :) I guess I'll play and see what happens.
[ ... 649 words ... ]
Playing with a range of news aggregators once more, since Radio UserLand is making me itchy again. Pretty much the only ones I really like are Radio, AmphetaDesk, and sometimes Peerkat.
For the last week or so I've been mostly alternating between Radio and AmphetaDesk. The difference in aggregation styles is interesting: While Radio slices and dices and aggregates feeds by items and serves them up to me in an interwoven chronological order, AmphetaDesk serves my feeds up to me whole and in order of feed modification. I'm not sure which I like more now.
I like Radio's style, because I see what's new and only what's new. Usually. But, I like AmphetaDesk's style because I see everything, and have realized that I miss things with the rush of new items from all my feeds. For instance, if someone posts something once per day, I'll likely miss it with Radio unless I check every hour. But, with AmphetaDesk, I get to see what's new with every person or source whenever I check, and I only miss items if that feed has scrolled them off.
Shelley Powers of burningbird.net wrote a bit about the context destroying nature that RSS and aggregators have on weblogs. I agree with her somewhat, in that pulling the words out of the surrounding context of the blog and its presentation and community has an altering effect, I wouldn't say that it destroys the weblog.
For me, when I see something on my news aggregator, it's as if I'm overhearing it from another room. I don't get the whole context or see who else is listening or responding, but I hear the gist of something. And, when subscribed to 100+ RSS feeds, it's like I'm floating in this Nth dimensional space where I can overhear voices from hundreds of rooms without being overwhelmed. When something triggers some of my mental filters and watchwords, I click the link and delve deeper.
There's no way, without an aggregator, that I'd be able to track 100+ people and news sources in a day. But, because I can, I've been able to learn and discover things and hear voices I never would have before.
But, I think the way AmphetaDesk merges these sources might be a nicer alternative. By not chopping up the feeds, some intra-item context is maintained at least, so I can see developing trains of thought.
Okay, must go back to work now.
[ ... 1182 words ... ]
Is it just me, or did my last entry make me sound like an obsessive, compulsive nerd? :) Funny, I don't think I am. If I am, it's fun anyway. And not all that expensive. And I actually do get out and do things and have a bit of a social life. Really, I do. Sometimes.
Oh, and I just noticed my wiki was broken for editing. Gah, that was unfun. Fixed now.
[ ... 74 words ... ]
John Robb writes about the next generation of PCs and such:Here is how I think the battle will evolve in the next five to ten years:...
1) A home server. This PC is always on and lives in a closet. It serves multiple users that connect to it using mobile wireless screens and keyboards. ...
2) An extremely mobile PC ala OQO. This PC will be attached to a single individual. ...
This sums up much of what I've been anticipating and have found myself building.
In the case of the home server, I have two of them actually.
One is a headless Linux box behind a cable modem that has accumulated all sorts of autonomous functions: it gathers my mail from various accounts into an IMAP server that I access from everywhere; before I was using Radio UserLand, it used to host all of my news aggregation hacks; it controls and monitors all the X10 devices in my apartment (though these are dwindling away); and until my radio reception got bad when I moved, it used to record radio shows for me using a D-Link USB FM radio. I actually have a Mac at work that does that does that for me, and dumps the sound files to my server at home periodically.
The other "home server" is a PC running Win2K with an ATI Radeon All-in-Wonder card. This machine is my PVR, recording to VCD the few TV shows I actually want to keep up with. That ends up being about 12 VCDs a week, counting all the episodes of Buffy that I capture. (Guilty pleasures.) I keep dumping more and more hard drive space into this machine, and use it as a general apartment-wide file server, as well as a dumping ground for stuff from remote when I'm out yet have net access. Occasionally I play Windows-based cames on the PC, but it mostly just sits there and does things.
I would like to combine these boxes into one big Linux box connected wirelessly to my cable modem, sitting in my closet in my apartment, or if I had a house, across the basement from the water heater. I want this home server to be in the same class of appliances as the furnace, washing machine, and water heater. The only thing keeping me from dumping the Win2K PC is the PVR functionality I haven't bothered to try under Linux yet.
In the case of my extremely mobile PC...
Well, I'm still in search of this, and the OQO looks very very attractive. Lately, my mobile PC has been my iBook. In most of my usual haunts (home, work, coffee shop), my iBook is present and tends to have net access. I have scripts which auto launch some SSH tunnels back to my Linux server and mount shares on my Win2K box when I switch networks. It usually works. I have all my current developing projects on the thing, and I do news aggregation with Radio UserLand. Occasionally at home, the iBook is what I have with me in the living room, so with the A/V cable I use the iBook to play internet radio on my living room stereo, or I stream movies over my LAN from Win2K PC in the other room.
But, what I really want is the Global from Earth: Final Conflict. I can't find a link or direct info on the thing as used in the series, but it's an amazing fictional device. Palm-sized with a pull-out screen, clips onto the belt. Has world-wide satellite video phone, global positioning, and seemingly endless PDA capabilities. I think I've even seen someone drop it into a cradle and pull up their work on a desktop PC. I've at least seen some general scenes like: "Hey, can you drop me a couple gig of that data onto my global so I can look at it later." Seems to have ubiquitous net access, even in low earth orbit. :)
But until someone makes that, I'm going to eye that OQO up for awhile and see what people think. $1000 seems like a sweet price if I can run *BSD or Linux on it. Funny thing is, so far, I haven't spent very much money at all on all these things I have. They've all been acquired used or on sale or for free. Most all of it was cobbled together from scraps.
Living in the future is fun. :)
[ ... 743 words ... ]
So I'm starting to play with PHP and working on rewriting my Movable Type templates as *.phtml.
Having never really payed much attention to PHP, I'm amazed at how close it is to Perl (obviously on purpose) yet how much effort has been made to sand off the rough bits. Not sure how much I like it yet, but at least it's a familiar tune they're playing. The mildly annoying thing is that it's familiar, but there are just a few things I would habitually reach for in Perl that I haven't sussed out yet in PHP. Like autovivifying data structures. I abuse those constantly. I really need to wean myself away from that, methinks.
One thing that I was pleasantly surprised to find is PEAR, "a framework and distribution system for reusable PHP components". Hello, CPAN, my old friend. :) Finding all kinds of things that are immediately useful, like a Cache I can use to more intelligently and easily do the output caching voodoo I do in the perl CGI widgets right now.
You know, a lack of a centrallized CPAN-like system is what has kept me from leaving Perl for many other technologies. I really wish Java (CJAN?) and Python (CPyAN?) had one supported by their respective communities. It's just so nice to do a perl -MCPAN -e"install Date::Parse" and get what I need. Maintaining CPAN bundles for my perl software is tasty, too. Single-command installation of all my app's requirements, and sometimes I can roll it right into the app's installation itself. Mmm.
Anyway, it's nice (to say it again) to have a running personal site to tinker with, now that I've gotten off my butt and done it. This laboratory is letting me manufacture reasons to play with tech I hadn't bothered with before.
I mean, I've used ASP and JSP, and for most of the things I've done, I've grown a severe dislike for them both. I left the "Hey, you've got HTML in my code!" paradigm behind, wandered through that "Hey, you've got code in my HTML" model, and eventually settled on my standard pattern now:A central app logic controller takes in GET/POST data, dispatches to a method which processes the form data. That method then constructs data structures, which are in turn passed through a template engine to be rendered by a pile of templates independent from the controller.
This, along with some very special self-assembling component-based automation sauce, is the core of what my employer's offerings run on. But, this has crystallized as a habit for me, and I've not even considered other possibilities for a long time. This of course has made everything look like a nail for this hammer I have.
For example, while PHP is not quite the right tool for the things we're doing at my day job, it seems like a perfect option to quickly and easily replace SSI pages on my site with something meatier yet still simple to maintain and doesn't stink like ASP or JSP. I've also been looking at Cocoon, which if I can ever quite get in a groove with it, looks like a highly refined instance of my standard hammer.
And then there's Radio UserLand. I love it and hate it. The hate mostly comes from the slower iBook on which I run it, I think. The bootstrappiness of it makes me itch sometimes, but other times that just makes it endearing. The whole self-contained development biodome it represents is pretty sexy, too. Speaking of autovivifying data structures... I just have to love a system which has a live, manually tinkerable giant outline/hashtree for a persistence mechanism.
Next, I really want to swing back around to playing with Flash. Last time I did something major with it, I was making a game for my employer which really wanted to use web services but I hadn't known it yet. The game worked pretty well, but I want to see what it can do since last we met. First thing in mind that seems mildly nifty might be a slick, live updating lil "Recent Visitors" app for my front page.
I'm really feeling what Jon Udell means when he writes about thinking by analogy. It's also something one of my favorite Comp Sci professors harped on, with regards to what makes a Computer Programmer versus what makes a Computer Scientist. A small part of his speech always pointed to the notion that a a programmer is almost always pragmatic, memorizing the patterns and greasy innards of whatever tool he or she uses daily. On the other hand, the scientist is an explorer and finds joy in confusing him or herself by finding the universals and generalities across a range of tools. In the end, the programmer becomes specialized in a limited domain, while the scientist knows can pick up just about anything that comes along. And sometimes, many times, the scientist makes new tools for programmers to specialize on. I want to be and am working toward being a scientist.
More soon.
[ ... 991 words ... ]
Prof Avery writes:Bad enough that the IM blog idea isn't new, the 0xDECAFBAD guy beat me to "404 Correction" in a Personal HTTP Proxy via Google's Cache.
Oh well, guess there's only one thing for me to do: quit whining and write the code...
So I'm the 0xDECAFBAD guy now, eh? Hee-hee.
Well, I haven't gotten around to writing the proxy yet, so you can beat me to that still. :) I've had a metric ton of good and sometimes new ideas throughout my relatively short life, but I have a habit of not getting very many of them done. That's where it counts, not necessarily in the novelty of the idea.
I mean... just look at Microsoft.
[ ... 248 words ... ]
This having a website to tinker with thing is kinda neat. Right now, I'm growing a nasty beasty using SSI and perl CGIs, just because it was quick and seemed like a good idea at the time. Obviously, now that I'm starting to get more than 2 visitors per hour, the SSI/CGI mix starts to slow things down. I do try a few smart-ish things, like making the CGIs do heavy lifting only once or twice per hour (at most) while spitting out cached results the rest of the time. But, there's still the overhead of external perl process launch.
So, I'm toying around with the idea of using Mason, whose design and purpose I seem to finally get, or learning PHP, whose design and purpose I dislike as much as ASP and JSP but whose simple utility I get now. Nice thing is, my web host has both PHP and mod_perl installed for me, and I can toy with either or both. There are other things I might play with learning as well. These are all things that pretty much everyone has already gone through, but it's fun to grow a site by tinkering and see things pop up.
I've been making and optimizing the same sorts of sites and applications for so long that I've started falling out of the loop on technologies not quite applicable to what I've been devoted to. This site of mine is proving to be a fun laboratory, complete with bunsen burners, Jacob's ladders, and those little curly tubes running between beakers.
[ ... 260 words ... ]
Mark Pilgrim writes: IO is more controlled [than linkbacks] -- you have to subscribe to other people's feeds to read their responses -- and is therefore better suited for intentional collaboration. Auto-linkbacks are more about exploration and manufacturing serendipity. Must explore this further.
This is why I went bananas with the referral links everywhere. Manufactured serendipity. The referrals do something that a weblog's comment feature just doesn't do.
Dave & the Userland crew often assert that weblogs are better than discussion groups, for various good reasons. Radio UserLand shipped without a comment feature (although it has one now), which I assumed was because the UserLand opinion was that the convention to comment & respond to someone's weblog was to do it in your own weblog.
The big problem I see, though, is that you're in your own bubble. If you have something to say about something I wrote, and you're not already in my RSS subscriptions, I'll never read you. If I don't know you already, chances are that I may not come to be introduced to you. The same goes for Instant Outlining. While I appreciate the intentional nature of this tech, and its strengths in avoiding spam, I want to meet you half way. I want to be surprised and have my ears get warm and turn red when you say something about me.
Referral-driven linkbacks on all pages on my site do this. If you post to your weblog and include a link to me, then I hear about it the first time someone traverses that link. This, to me, is even better than the comment feature. And, as Mark Pilgrim observes, this is better that a single referers page because these linkbacks appear in context. The conversation is built up from links in place and on topic and where the action is. To me, this is the two-way web really in action
[ ... 458 words ... ]
Bill Seitz says I've gone bananas with this referers thing. And, well... yup I guess sticking it everywhere on my site qualifies. :) But, it was quick to write, and even quicker to rework since I just broke it away from using DBM files and switched to a MySQL table. (Wow, DBM files. One of those ideas that seemed cool at the time. A full-on Berkeley DB would have been better.)
I'm pretty much going bananas all over the place lately with all these fun things going on around the net. I'm like a kid in a candy shop, or is that a bull in a china shop? Well, I'm far too skinny to be a bull. Sooner or later I'll settle down, but it's fun having a working website and mad scientist laboratory to play with after the past few years of being too much of a perfectionist.
[ ... 212 words ... ]
Oh, and I have to say: This Mach-O build of Mozilla for Mac OS X rocks. It actually makes my little iBook feel zippy. Makes me wonder why they even bother with the other builds. Turn on the Quartz font rendering, and this will be the world's best, prettiest browser.
Thanks to Mike James for the pointer! Someone else I wouldn't've found without referrals.
[ ... 65 words ... ]
Well, I bit the bullet and pitched in the extra bucks to upgrade my hosting which, among other things, finally gave me an access_log. The first thing I did was install Webalizer over here. Should my access log reports not be public? Hmm. Well they are for now, if that becomes a problem, I'll put a password on it.
The second thing I did was attempt to copy the Disenfranchised linkback act and make a wiki and SSI includable referers widget, which I'm calling ShowReferers. Mine's not quite so slick as their implementation, since with theirs you can construct your links to refer to paragraph numbers in a page so that a link back to you is injected right there on their refered-to page.
The neat thing here, though, is that I stuck it into the view template for DecafbadWiki so that every wiki page will show referral links, if there are any. I also dropped it into the pages for each story on the weblog. (Which reminds me that I need to make the story pages nicer, since I hardly ever look at them but the referrals tell me that other people see them more.)
I didn't quite get the value of referral links before, but I do now. :)
[ ... 212 words ... ]
One brief thing: When I switched over to Mac OS X on my laptop and on my desktop at work, and I bought the WindowShade X haxie, and then installed PWM as my window manager on every X11-running machine I use (including the OS X boxen).
I've come to this conclusion today: Windowshading is the outliner of window management.
TY HTH HAND PDT
[ ... 64 words ... ]
OTLML makes me think that I need to play more deeply with XML. I need to learn XSL, how to use Xpointers, I really have to spend more time with RDF, and I need to work with SOAP more.
I think I see the difference between things like RSS 0.92 and RSS 1.0, and between OPML and OTLML, now. Not quite sure if I can explain it precisely enough yet, but I have a slight groking of it. The upshot of it is that I really need to throw myself toward the side of latter in both cases.
Back to work.
[ ... 102 words ... ]
I've noticed that Dave's been getting some submissions of further HexOddities since he linked to me a few days ago. So, I've started collecting them. Feel free to come and contribute to the catalog. :)
[ ... 36 words ... ]
Now this is pretty cool (via Bill Seitz): Disenchanted has referral-based automatic backlinks. Funny thing is, since I started using the little SiteMeter web bug, I've been refreshing the referrals fun. But, constructing the referral report right in the entry is another sort of WeblogWithWiki-esque feature I hadn't even thought about. Now if only I had access to my access_log here. Maybe I'll be checking out another host soon. There's got to be a way to make this work with Movable Type and / or Radio UserLand.
[ ... 88 words ... ]
Jon Udell wrote a few columns and weblog entries about pipelining the web, and the power of the URL-line as akin to a UNIX command line with pipes. His examples did nifty things with a publicly available XSLT processor to use an XSL stylesheet at one URL and an XML document at another to produce a new document.
So, this is what I've been playing with a bit this week, expecially with GoogleToRSS and RssDisplay. But, this is what the URL looks like when I string the two together (line wrapping forced):
http://www.decafbad.com/web-services/url-based/rss_display.cgi?xml_img=htt
p://www.decafbad.com/images/tinyXML.jpg&src=http%3A%2F%2Fwww.decafbad.com%
2Fweb-services%2Furl-based%2Fgoogle_rss.cgi%3Fquery%3Dlink%3AXGnxCbayl9UC%
3Awww.decafbad.com%2F%26title%3DLinks+to+0xDECAFBAD%26description%3DTop%25
2010%2520Links%2520to%25200xDECAFBAD%26
What a pain this was to build. I had to make a little form in a throwaway page to trick my browser into doing the hard work. I suppose I could make a lil utility script to do the meta character escaping more easily. But, man, if people are already making fun of the punctuation and obfuscation possible in Perl, imagine what they'll say about scripts on the URL-line. (Assuming I'm not missing reams of existing ridicule already. :) )
Jon does make a note of this little problem, but I'm thinking it's going to be what makes me wrap up my URL-as-command-line experiments. What would this URL look like if it had 1 or 2 more levels of pipeline?
I suppose I could, as he'd also mentioned, employ a few tricks like reducing script names and parameter names down to single characters, but then I'm sacrificing one of the virtues he'd mentioned: the human readable, self-documenting nature of URL-based services. Well, that gets scrapped at the first layer of pipelined URL indirection with the escaping of URL meta characters. Hmm...
Still poking away at things, anyway.
[ ... 285 words ... ]
In doing some poking around about REST, I'm trying out a topic-specific Google search in the wiki via GoogleToRSS and RSSDisplay. (Thanks for the pointers, by the way, Sam!)
I called it a "permasearch", just because it's kind of a permanent search-in-residence. Basically a Google Box, only I didn't use RadioUserLand to make it. (That wouldn't've been as much fun, since Radio's already got verbs to handle it! :) Sometimes reinvention is fun.) I think I need to do some more homework on it to make it worth of a new name, like do searches when visitors aren't visiting it. (Currently, it updates at most once per hour, at least once per visitor.) Maybe do some time-series search differences... hmm, but what can one do with just the top 10 results?
[ ... 132 words ... ]
I don't get REST, specifically in the context of it being the RightThing to do web services. I see many vagueries about how it's "more scalable" and more "right" and better in theory and there's a big dissertation on it and everything. Eventually I will get down to reading it. On the surface, it seems like a big dud to me. But, it looks like a lot of smart people are into it, so I assume there's something to it since I don't know much yet.
This is why I love Busy Developer Guides, by the way. They're for busy developers. Like me.
I don't suppose anyone could point me to something that lays it out for me? Like... why is XmlRpc considered harmful by REST fans? And what's an example app I could use REST for that will just so obviously convince me that I need to drop my XML-RPC ways?
[ ... 518 words ... ]
Ack. Just when I was having fun playing with it, it looks like my GoogleToRSS toy is broken. Did I run out of plays for the month? Damn. I promise that it actually works, though :)
[ ... 37 words ... ]
Personally, I think this is the funniest thing Google has reminded me of today: Readers shun browser-OS integration - Tech News - CNET.com. How I came up with a comparison between flushing toilets and Microsoft Internet Explorer, I'll never know.
*whistle*
[ ... 42 words ... ]
Peter made a command-line tool called Google2RSS. Then, he mentioned that someone was thinking of making a Perl or PHP version of his tool.
Well, I saw that Aaron made Net::Google, and I already had XML::RSS, so I figured I could make a Google to RSS widget in about a half hour. That was about right.
The code is here: google_rss_cgi.txt, but I'm planning on making a semi-proper writeup for it in the wiki in a lil bit.
Let's see if this vain Google to RSS feed works:
[ ... 89 words ... ]
This looks like the kind of bestsellers list I would like to pay attention to: Weblog ?BookWatch. I should also start noting what's in the stream of dead paper flashing before my eyes. Let's see if any of these pop up on the bookwatch...
Currently reading:Fool on the HillThe Cluetrain Manifesto
Waiting on the shelf:The Selfish GeneSmall Pieces Loosely JoinedThe Tipping Point
On the shopping list:Flatterland: Like Flatland, Only More SoGodel, Escher, Bach
Some of these, like The Selfish Gene and Godel, Escher, Bach, I've read before but have not yet actually owned. Time to read them again and actually have them on my shelf :)
[ ... 107 words ... ]
Heh, nothing like a link from Dave Winer along with some very nice compliments to make my traffic spike up ten-fold. :)
Thanks, Dave, for the kind words and the link. Oh, and I'm very glad you got the joke!
[ ... 41 words ... ]
How's that for realtime? Just popped in over at blogchat.com, signed up for the beta, and now it's working here. Take a look over in the "Gadgets" section and click the Blogchat to spawn a chat window. Or, click here:
Now I have to think about how to make it more prominent and inviting.
[ ... 55 words ... ]
It's a small bloggy world: I just noticed a few referral hits from Peter Drayton, whose book I just bought this weekend. Hi there! :)
Now if I just had some .NET and C# love on my iBook. This seems like a vaguely heretical thought to me.
[ ... 48 words ... ]
Bill Seitz' thoughtspace/wiki says about me: Probably the only person using RadioUserland, TWiki, and LiveJournal? all at the same time.
Hmm... really? Weird. I've just been kinda sprawling out across as many technologies as I can, because it's fun to play. Hell, I have 7 species of wiki installed on my laptop (though not all in regular use of course).
Wheee!
[ ... 112 words ... ]
In a column on Zope Lessons Learned, Jon Udell writes:It seems silly to recreate, in a scripting platform, services that already exist in the environment. On the other hand, since those services aren't guaranteed to exist in the same way in every environment, you can argue that the scripting platform should be self sufficient even if that means reinventing wheels...
This is something else I've been thinking about with regards to the PersonalServer / DesktopWebAppServer I want to put together. Thing is, between the slice of a full peer I have at decafbad.com, and the full UNIX environments I have on my 2 linux boxen and one iBook, I have 90% of the environment I want already.
I have databases, I have web and mail servers, I have WebDAV, and I have schedulers. Should I just say to hell with it and get on with writing the top layer? That is, the actual apps I want to run on this nifty personal server framework? I have been so far, and calling it "prototype". Telling myself that these little apps are just "playing around" for until I build a "real" desktop environment in which to host the apps.
So why reinvent all the wheels to which Jon refers? Because they "aren't guaranteed to exist in the same way in every environment", and I would like to distribute and share my work to people who don't have a full peer, 2 linux boxen, and an iBook. So, I'd like this stuff to be a simple little wrapped up package that's easy to drop in on a Win32 box. Or a Linux box, or a Mac OS X box. So, in order to make a cross-platform PersonalServer, I have to reinvent the wheels and create a run-time environment that itself runs on all platforms so that I don't have to modify the upper layers of the app.
Hmm... Or, I could just get to work within the excellent environments I already have, screw reinventing wheels, and actually create some apps that would be worth making cross-platform on some later date. :) Because the longer I work on reinventing wheels, the fewer things I have that are really any fun to play with in the end.
Besides, who would I be kidding if I didn't admit that the stuff I'm playing with right now is for early adopters and AlphaGeeks? So why waste a lot of time making a pretty box with a bow now?
MacOsX exists, and RadioUserLand exists, so I might as well stand on their shoulders. I wish I could find the permalink, but Dave Winer was talking about Open Source developers banding together on a mailing lists to "crush" a commercial product. He works toward the conclusion that this is stupid and useless, and that cooperation is more in everyone's interest. Not to be a dittohead in the Cult of UserLand, but they seem to be bearing this out. RadioUserLand is so open and inviting for tinkering that I think most of what I'd want from an Open Source clone is already there.
Hell, I even prefer MacOsX over Linux now. Am I selling my hacker soul? I don't think so. :)
Okay, okay, enough babbling. I'll forget about writing my OS-within-an-OS for now and write the apps on top of it.
[ ... 552 words ... ]
Looking at the LiveJournal XML-RPC Protocol Reference again today. I need to make a metaWeblog API gateway to LiveJournal, now that I can supply arbitrary metadata and now include mood and music. Next stop would be to make a client that can exploit metaWeblog that feels like the LJ client.
[ ... 69 words ... ]
Okay after the vote of confidence from Sam Ruby about my thinking out loud about a "404 correction" proxy server, I've been thinking more about writing a Radio-like desktop app server. I want to do more than make a DesktopWebsite, though. I want to make a full-blown PersonalServer app, capable of hosting things like a PersonalMailServer and a slew of other little local web services & etc. I may end up giving up and working more within Radio, but as I noted before I have some issues with Radio's performance and stability, which though balanced by my appreciation of the elegance of the system, is being gradually outweighed by my fears of lock-in and pre-existing experience with other technologies.
Then again, this thing probably won't replace RadioUserLand for me. I use it daily, I bought it, and it's not as exciting to reimplement what I already have. Unless it is exciting. Make any sense?
So, speaking of technologies... which ones should I use to start working on a personal server? My main goals are mumbled over here.
I've got a large amount of experience with Perl, and have written desktop apps with it for Mac OS X and Win32. I'm having more fun with Python, however, and though I haven't written the same apps I imagine that it's on par with Perl.
The main thing I'm trying to decide right now is: multi-threaded vs async/event-driven.
See, I need some sort of concurrency to handle multiple network server hits, multiple agents running, a scheduler, and whatever else wants to take up residence inside the PersonalServer. RadioUserLand, of course, has all of this.
I've worked a lot with POE in Perl to make some event-driven multitasking apps, a few servers (HTTP, FTP, NNTP, etc) and a few things to replace a fleet of forked scripts. I've also started looking at Twisted in Python which I gather to be the analogous thing in their camp. Not the same, but they both are using the same basic idea of event-driven programs.
The problem is that, to take code that you would have written for a forking or multi-threaded program, and make it play nice within the event-driven environment, there's a bit of re-think you need to do. Loops need to be broken up into procedures, turned into self-running events, etc.
Hmm... trying to think of more re-think examples, but the main one I can think of is that long-running loops and processes need to be sliced and diced. I seem to remember more pain than that.
Anyway, I'd rather use threads. In threads, there needs to be a bit of re-think too, in terms of protecting resources from concurrency, but at least the main logic of my code can remain straightforward. Perl doesn't have threads that I want to touch yet. Python has threads, but I'm not sure how kosher they are. Of course, there's always Java, but I want to avoid Java I think.
Anyone tuned in out there with any thoughts? Mostly thinking out loud right now.
[ ... 641 words ... ]
I'm running decafbad.com on some pretty cheap hosting that gives me most of what I need, but it's missing one annoying thing: access_log. I'm playing around with Site Meter, but I do have my own CGI hosting (obviously), so I'd like to find something that can closely emulate an Apache-style access_log with web bug images. The Apache format would be nice because then I could use any of a number of standard log analysis packages. Referrers would be a problem, of course, but I think some Javascript could hack around that. Maybe I'll just end up writing it meself.
Hmm.. Looking...
(Or I suppose, if I wanted the access_log badly enough, I could upgrade my hosting.)
[ ... 141 words ... ]
I need to turn my subscriptions list into a blogroll. Oh, and make sure that the subscriptions OPML doesn't contain any of my password-protected MailToRSS feeds. Also pondering doing some cute things, like maybe display a random subset of my reading list (since my blog+news RSS list is > 100 items), and maybe use RSSDisplay to pull in the headlines from a random RSS channel I subscribe to, and call it "Featured".
Hmm. blogrolling.com would be hot if it accepted a URL to an OPML file.
Maybe that's what I should do with my subscriptions-to-blogroll thing, kinda like I did with RSSDisplay. Yeah, I know RadioUserLand does or can do all of this, but I'm kind of in a mood to make a pile of small pieces to loosely join out here on decafbad.com.
[ ... 289 words ... ]
Hmm... now that I finally stopped babbling and read the docs, I just noticed that the Google APIs has methods to access their cache.
Sounds like I need to write a personal HTTP proxy that includes "404 Correction" by consulting Google's cache whenever one encounters a 404. Could be a new project, too, since someone I was talking to wanted searchable personal web browsing history and I think a personal HTTP proxy could help with that.
[ ... 157 words ... ]
I'm glad to see that I'm not the only one who doesn't quite yet get an immediate eureka about the new Google APIs-- searching in particular. Of course there are the non-web crossovers, like searching in AIM via googlematic, but this mostly makes me yawn. Yes, its fun and geeky, but yawn. This is not to say that the Google search API itself makes me yawn.
What makes me yawn is anything that's just an alternative direct user interface on the service. Search from my IDE while I program? Eh, that's okay, but I could do that by just spawning a browser with a cooked URL and not have to re-engineer a UI do display the results. Display some results of a canned search in my weblog? Eh, that's cute, but I could do that with some simple HTML scraping and SSI, if I really really wanted to. Yeah, I know the web service makes that somuch easier, but the thing it makes easier isn't something I was really interested in the first place. Maybe I'm not interested because I don't get it yet, or maybe it really is just a novel triviality.
No, what will make my overhead lightbulb spark up are applications which involve indirection. That is, some application which makes searches to answer some other question of mine. Search results used to spawn further churning. Or, search results as the result of churning. Google's suggestions are intriguing: Auto-monitor the web for new information on a subject; Glean market research insights and trends over time; Invent a catchy online game. But, these sound disappointingly close to a corp-speak shrug.
Not that this is unexpected or a bad thing or a statement of derision. Their Alpha Geeks made the service available, and now its up to the world Alpha Geeks to turn it into magic. I'm just waiting and thinking though... the AG's are churning out all permutations of language bindings, alternative interfaces, and weavings of the service into other apps. This is the first stage of play. I don't know that I'll feel like playing much yet. So I'll watch, and maybe tinker a bit, but mostly be thinking about what the next stage of play will become.
[ ... 518 words ... ]
Dave says: Novell now has a white-on-orange XML button on its Cool Solutions home page.
They've got more than that. In case you haven't seen it, they've got an entire fleet of Novell newsfeeds in RSS:
http://www.novell.com/newsfeeds/
[ ... 37 words ... ]
The new Google Web API is a mind bomb, but I feel a bit slow because my head hasn't raced out to find a bunch of nifty uses yet... it'll come to me though. And I'm sure I'll be seeing the other smart people on my aggregator start doing some amazing things. I haven't quite caught on fire with Dave's Google Boxes yet, but I feel a slow burn going. Long running searches. Changing results. Makes me itch.
I guess a mind bomb wouldn't be a mind bomb if it didn't take a few to build up power.
[ ... 99 words ... ]
From Mark Pilgrim, again:Not that you'll notice any difference, but I'm now using server-side includes to serve up several semi-static pieces of each page of this site, including the logo, the copyright notice, the footer, the CSS declaration, and most importantly, the blogroll.
Funny... Is there something in the air? Not that I've talked much at all (if ever) with Mark Pilgrim, but these are all the same kinds of things I've been playing around with here. Maybe I should drop him a line :)
[ ... 85 words ... ]
From Mark Pilgrim:CBDTPA looks destined to die a quiet death in committee. But if anything like this bill ever actually passes, our entire society will instantly turn into Cuba after the embargo, where everybody holds on to their pre-2002 technology, fixing it up year after year, decade after decade, rather than pay for new crippled technology. (In Cuba I believe it was cars in particular; for us it would be computers.)
Funny, I have been considering exactly this. If all this DRM and "Secure" media gets legislated and forced upon the market, I'll likely not buy another electronic gadget for a long while, unless maybe it's a used pre-2002 device. Those, however will probably top the $1000+ range on eBay, unless resale is outlawed as well.
Forcing copy protection and "secure" media and "digital rights management" onto the market is idiocy. We don't want it. Really. It doesn't make anything nicer for us, no matter how much you use fuzzy happy words like "secure" (who's secure? me? nope. my investment in books, music, and movies goes down the drain).
And the stupid horror of it is... this will kill the market for technology toys dead. The current offering of electronic gadgetry is pretty nifty already. PCs are pretty damn fast now. I doubt the majority of people have outstripped the capabilities of the things they own now, if they have bought a PC, mp3 player, CD/DVD burner, PVR, or digital camera recently. If it turns out that all new stuff past a certain point has inconveniences and copy protection and requires more money to run and etc.. well, then I think people might just settle for what they have awhile longer. I really think that technolust and thirst for the next bigger and better thing will chill because it'd be more trouble than it's worth.
My faith in the intelligence of my fellow Americans, especially my elected officials, is teetering now. I've been pretty optimistic. I thought they'd be smart enough to realize these things by now, I never thought they'd get this far. But seeing that the RIAA, MPAA, and all the other money bloated fuckers are actually being taken seriously and not laughed off Capital Hill have me seriously worried. The government got stolen a long time ago, and I never wanted to believe it. Grr.
I just hope it hasn't slid over the cliff yet and all these bastards finally hang themselves with all the rope they've played out. I still hope that there's a sleeping giant of reason out amongst the sheep.
[ ... 426 words ... ]
Crossposted from my LiveJournal:
Checking out the info for the automaticwriter community again, and I'm thinking I might have an idea to try out. Not sure if it'd fit in the community, but I think it might.
I need to find the algorithm, but I remember playing with some things that would analyze a body of my writing, looking for word and punctuation correlation and frequency. It could then to a cut up across that body of my writing, use the correlations, and throw a new bit of text together which sounded very surreal but still sounded uncannily like me.
So that's one part of the idea. The other part is this: I monitor about 120 news sources on the web through Radio UserLand. What if I took a random sampling of content out of my daily stream and applied my writing style analysis to it to produce new content? That is, take the content of random writers in my news stream, but do a cut up and automatic re-assembly based on an analysis of my writing style.
I'm sure it'd produce a lot of crap, and I might want to apply a little manual wrangling to things, but it might just produce some interesting results.
[ ... 207 words ... ]
Some grumbling before I hit the sack for the night. Since January, when I bought RadioUserLand, I've been getting sucked into the platform. I resisted at first.. I mean why learning another language, especially one bound to a single, commecial platform? Well, the more I played with it, the more the platform looked elegant, and the $40 I spent on it was chump change for what it can do. I can see the foot-in-the-door when I start thinking if there's a way we can use Frontier at work.
So, I'm tinkering and playing... And I'm putting up with flakey things happening, which confuses me. Inexplicable delays, screen flashes, stuttery speed-up and slowdown of text entry. The PipeFilters app I'm working on is killing Radio on my iBook. Sometimes RadioUserLand crashes. I just can't see what's to exotic about what I'm doing in PipeFilters what would prepare me to think it would hobble Radio regularly.
Sometimes, when testing PipeFilters, RadioUserLand somehow manages to bring my iBook to such a grinding, HD thrashing halt, that the CPU Monitor no longer scrolls and I can't even get response from the Dock to kill Radio. My only hope in this situation is to have a Terminal ready with a kill command typed out, launch the script in Radio that only sometimes offends, and then hit enter if things wig out, hoping that within the next 30-90 seconds the Terminal will be able to get a slice of time to eke out the kill command.
Part of it might be the iBook itself. This thing, though pretty and nice, is just not meant to run OS X. It runs it, but I beat the crap out of it. It feels like a 486 laptop. I just switched to a dual 800 G4 Mac at work, and OS X is a dream there. Though... Radio still crashes from time to time.
The more these things happen, the more it starts to make me think maybe I should cut loose soon and take what I've liked about Radio and do some wheel reinvention and cloning in the Python-based things I was thinking about.
But I so want Radio to work well. It's got so many nice ideas in it. I'm just worried that there's too much bootstrap in there.
[ ... 557 words ... ]
I feel like I'm discovering SSI again, as if for the first time. I'm using it around here to piece together a few pages with dynamic elements, among other things. Seems like all I need most times for this, as opposed to a more general web app framework or CMS. I'm sure eventually I'll get tired of it after having run into all the problems everyone else in the world has, and roll my own CMS again. Maybe this time I'll stop before I get to that point and adopt someone else's before I get down to wheel re-invention work. :) But it's so fun.
Anyway, my latest tinkering with SSI can be seen on the right side of 0xDECAFBAD's front page: Sibling blogs.
So far, I've got my LiveJournal blog over there, along with my RadioUserLand weblog. Maybe in listing a few headlines over there, I can entice a few readers to my other spaces. LiveJournal is where I do most of my general blogging, link posting, and general grousing. (I think that's my new favorite word) The RadioUserLand weblog is just an experiment at this point, but it may eventually consume the whole site.
Basically, RadioUserLand is competing with server-side CGIs and SSIs at this point. Eventually, they will cooperate. After that, RadioUserLand may take over.
Anyway, enjoy RssDisplay if you like-- you can either download it, or PipelineTheWeb and use it straight from my site.
[ ... 239 words ... ]
Via Eric Freeman's Radio Weblog:
Tim O'Reilly: So often, signs of the future are all around us, but it isn't until much later that most of the world realizes their significance. Meanwhile, the innovators who are busy inventing that future live in a world of their own. ... these are the folks I affectionately call "the alpha geeks," the hackers who have such mastery of their tools that they "roll their own" when existing products don't give them what they need.
That's what I want to be when I grow up: an alpha geek.
Well, I already am an alpha geek, only just in fairly obscure circles. Wherever I've worked, I've become the ToolBuilder. I'm the guy who takes the stuff we have that never quite all works together, and I weld it together into some freakish kind of A-Team nightmare that lets the team crash through the brick walls.
And here at my current job, I've worked at seeing how far I can take the ThirdTimeAutomate rule. Where it's lead me (and this company) is to a component-based web application framework with automation support in building up the apps.
I've gotten the system to the point that a Design Tech (HTML-guy) can crank out a dozen promotions with the system in a day, with a large degree of customization. Occasionally, a Software Engineer may need to toss in an hour or two to write a custom component subclass or new component.
The components are built to be self-describing and, within certain circumstances, automatically collaborate. We can mix & match promotion aspects and they'll work to integrate themselves. The efficiency it's given us has allowed this company to survive the dot-com bust with a tiny number of employees and expense. Now that business is actually picking up, productivity is still so high that we don't need many more people yet. And it's kept me in a good job all through these rough times.
It's really good stuff, and I'm very proud of it. In a way, it's the culmination of my last 8 years or so of work on the web. The problem is... This technology will likely never leave this company. I've spent my past two years refining it, and it will probably never be seen outside the 2 dozen or so employees of this company, only 3-5 of whom really know what it's about.
Which brings me to things like this:Getting Noticed? from Eric Olsen (via Steve Ivy, et al.). "As the volume of blogs has ballooned well into six-figures, the need for links from ?star? blogs has become an absolute requirement to be noticed."
But I think this is how things go in the world in general. It's a big, big place. To be noticed in it takes some work.
So here I am, an alpha geek and a ToolBuilder spinning in my own circles, hope someday to have my name up in lights.
http://www.decafbad.com/twiki/bin/view/Main/ReleaseEarlyReleaseOften
[ ... 490 words ... ]
Psst. Another version bump. Playing around with breaking filters out into their own definitions, to be referred to by the pipelines instead of embedded in them. This way, once I get around to doing the web UI to manage everything, I can have filter creation, acquisition, and trading all done separately from pipeline management.
Haven't heard much feedback from anyone using the tool, if anyone's using it. So for now, it's a fun exercise in how to get a Radio Tool put together from A-Z. Still learning the idiom. And I like what I see thus far.
Now if only I had a faster Mac and Radio didn't die on me as much.
[ ... 114 words ... ]
Awhile back, Aaron was playing with a Memepool-izing web service I whipped up from his code.
Now I'm testing it out with my RadioUserLand PipeFilters tool:
Four score and seven episodes ago our slayer brought forth on this continent a bunch of dead vampires, conceived in the hellmouth, and dedicated to the proposition that all undead are destroyed equal.
[ ... 60 words ... ]
Just published a new version (v0.3.5) of my RadioUserLand Tool, PipeFilters:Added a 'shortcuts' filter to use the new Shortcuts variant of the glossary.Virgin data contains pipelines using the new shortcuts filter (you may wish to copy some of them to your pipeFiltersData)Added a to-do list to the pipeFiltersInfoCleaned up a few installation bugsCleaned up a few bugs in pipeFiltersSuite.sendDataThroughPipeline()Unfortunately, no web interface to manage pipelines yet.
[ ... 67 words ... ]
4/6/02; 6:51:52 PM by LMO -- Outline diffs and Jabber?
Is Jeremy Bowers doing outline diffs as a Jabber conference?
Screenshot (should open in browser)
If so... WOW.
4/6/02; 4:58:40 PM by LMO -- Comments in my buddy list
So I hope this doesn't break anything.
I did a "Get Info" on a few of my buddies in my list, and edited the author line to add some parenthetical comments. Just a note on why I'm interested in this buddy's outline.
It seems to work without a problem, and the note appears when next the buddy updates his or her outline.
Seems like this needs a more accessible UI. Like... how about allowing me to edit the names right in my buddy list?
4/6/02; 4:55:12 PM by LMO -- Auto-archiving script?
Just got around to splitting off the last week or so's archives into separate files. There's got to be a better way. I wonder how hard it would be to make a script that does it nightly, or at least with a high degree of automation after being pointed at a branch of my outline?
[ ... 187 words ... ]
Over at weblog.masukomi.org, she's musing about how one would share the spoils of a software project, say one that was built in an Open-Source-ish way. Maybe a metered Web Service.
Developer shares by which profits are broken up? How to allocate the shares? What should be given incentive?
Hop on over there and add some commentary.
[ ... 57 words ... ]
Is it just me, or is it mildly frightening that a Hello World app in any language or on any platform would call for 73 commits, 43 adds in CVS?
Yes. It is frightening. But... look at all the features!
(To be fair, yes I know that "hello world" is not the point. It's still funny.)
On with further Cocoon newbee wandering...
[ ... 63 words ... ]
Hmm, trying to see if my outline pings weblogs.com. (It does.)
Seems like a neat idea to subscribe to io.opml as a buddy. Let's hope its not neat like digital watches.
Also, I need me some automated outline log archiving and possibly some automated spool-to-weblog action going on here.
Oh, and my Radio weblog was broken. Now its not.
Spooky.
[ ... 61 words ... ]
Some point soon, I think I need to meddle with the site templates again and strip every adornment. Make them as simple as possible. It's fairly plain now, but I need to get it minimal-yet-not-plain. Too much light makes the baby go blind. Or something.
[ ... 46 words ... ]
Here's my attempt at DecafbadWiki ?RecentChanges in OPML Dave wanted to see some OPML coming out of Wikis. This could be a start. It's a bit dirty right now, too, since I doubt that all the dates it outputs are kosher. Radio seems to consume it happily though. Next thing is that I want to OPML-ize a wiki page, using the headings (H1-H6) as cues for structure and each paragraph as child headings One hiccup though: My script had to be *.opml, just claiming to provide text/x-opml wasn't good enough to be transcluded here. I wonder: If I subscribe to this as a buddy, will Radio embolden it on new wiki pages? It does, indeed. But, of course, although it is transcluded into my instant outline, wiki recent changes do not embolden my outline.
[ ... 191 words ... ]
From Radio UserLand's Outliner @ 4/4/02; 10:24:32 PMOutlog Current status: Online, working. 4/4/02; 10:11:30 PM by LMO Were I insane (perhaps criminally so), and if I knew elisp in emacs better, I would stick instant outlining into Emacs' outline-mode. Then we might truly have the "emacs of outliners". Or something like that.
4/4/02; 9:22:13 PM by LMO My cats demand my popcorn. The two of them work in tandem, one distracting and the other snatching. Astonishingly, they share the spoils.
4/4/02; 9:14:24 PM by LMO Concering Arboretum, Mark Paschal says: "No matter what I do, Les Orchard has done it first." Heehee. Funny, I've never had that said about me before :) I always feel like I'm behind. But, Arboretum as "emacs of outliners" is a boast / pipedream. The current state of affairs is not quite that. At present, it's more like My First Cocoa Program [tm] Actually, I think a Python/Tk (or maybe some other GUI toolkit, say ?WxWindows?) would have a better chance at making it to being a cross-platform "emacs of outliners".
4/4/02; 7:51:13 PM by LMO Been sick. Have to recover. Too many exciting things happening. Many many things I want to pick up and run with. Instant Outlining Arboretum needs to do it. I want diff for outlines. It'd also be neat to do some mining to conserve my attention span. Has someone mentioned my name (or a given pattern) again since the last time I read their outline? Maybe bold and italicize my buddy's name to tell me that I'm really interested in what they just posted. In IRC, using X-Chat, the name of a channel I'm in turns blue on changes, and turns red on changes and a mention of my nickname.
Maybe along with Cocoon, make OPML one of the serializations, with hierarchy determined by a sections/headings analgous to HTML's H1-H4 and ?DocBook's sect1-sect4
Let's see if anything breaks. The textareas in ?OmniWeb are suckily thin, will have to fix that in the templates. Trying out the disabling of line break conversion:
From Radio UserLand's Outliner @ 4/5/02; 12:35:49 AM
Wiki
Why do I like wiki?
An interface which steps out of one's way is a productive interface
Dead simple markup for humans
Dead simple collaboration & versioning
Dead simple, almost automated document structure
...and Cocoon
Seems like a natural. Transform from human-oriented markup shorthand to an intermediate XML format and run from there with the transformations.
...and Python
MoinMoin seems to have a bit of a primitive pipeline going on with formatter classes.
...and ?DocBook
We want to collaborate on book authoring at work.
... and OPML
Maybe along with Cocoon, make OPML one of the serializations, with hierarchy determined by a sections/headings analgous to HTML's H1-H4 and ?DocBook's sect1-sect4
[ ... 148 words ... ]
No, 0xDECAFBAD is not dead... it's just been left out of my pipeline stream. I need to work it back in, otherwise this place will never do what I want it to.
I've been doing most of my babbling over here on my Radio weblog and even more obscurely, over here in my Radio instant outline, not to mention over here on my LiveJournal.
Need to get all my tools and channels straight. :)
[ ... 75 words ... ]
Look at what Dave has done to me! My Radio weblog is sitting over here if you want to tune me in, and an explanation of the madness is over here.3/27/02; 1:25:43 AM by LMO This is pretty swanky. Swanky indeed. Instant messaging meets outlining. It seems that it's not quite there yet, but I understand that's not what this beta is about. But as a beta, this is a swanky mind bomb indeed. Especially if, as Dave says, we start to see who's watching whom in outliner land. This is what I want for all the weblogs. Hot hot hot. Now maybe I can get off my butt and work on Arboretum some more and get it in on this action. From what Dave's saying, anyone who can speak OPML (and I assume maybe XML-RPC and maybe Jabber) can play.3/27/02; 1:37:05 AM by LMO Of course, one other thing: Why didn't I pay attention to Frontier and UserLand sooner? :) This is what I've been trying to make with Perl, ?MySQL and friends for years now.3/27/02; 1:57:32 AM by LMO I really should be in bed by now, but I'm subscribing to outlines like a madman: Dave Winer, Scott Loftness, John Robb, Laurence Lee, Jake Savin, David Brown, masukomi, David Davies, and Jeremy Bowers I'm also thinking that there's some kind of unholy symmetry between me @ decafbad.com, my obsession with coffee, Dave @ userland.com, his affinity for coffee-- and of course, insomnia stemming from the fact that what you're doing at the moment is so much more fun than sleep.
[ ... 263 words ... ]
So.. What have I been working on? Well, XmlRpcFilteringPipes via RUPipeFilters in RadioUserLand. I'm soaking in it right now. So far, the text I'm writing will be piped through my local RadioUserLand instance, with filters on the built-in glossary and macro system. After that, I send my content out for a trip through the DecafbadWiki to pick up a few links from there.For example, these should be some wiki links: BootToTheHead, ?EnlightenedSelfinterest, WebChanges, WebIndexThis should be the time via the statement clock.now(): 3/26/02; 5:46:22 PMThis should be a link to something truly evil from the bowels of my RadioUserLand glossary: Dancing HamstersI've got the whole shebang working in RadioUserLand right now. The only thing keeping me back from a release is building a friendly-ish web interface on managing pipelines. Maybe I should say screw it to that for now and just release it. It's useful right now, and managing pipelines is a matter of editing the preferences database, which is a breeze for early adopters. There are even convenience methods to do it with. And in-the-moment usage of the system is easy: select your text, copy it into the clipboard, bring up Radio's tray or dock menu, pick Pipefilters->Apply Pipeline to Clipboard, and away you go.Maybe I'll do this tonight. I think it's incredibly useful, and odds are someone else will too.
Update @ 2:14am: Ooh, Dave linked to me. He called me weird. This makes me blush. If you're looking for the goods of which I speak, try coming back in about 8-10 hours. I've gotten sucked into playing with Dave's Instant Outlining bomb drop and have forgotten about packaging and uploading my own. Funny how I'd just posted a message to the radio-dev mailing list, jokingly demanding his goods. I go to dinner with my girlfriend, come back to find that he came through with it.
I'm going to bed now, the alarm clock rings too soon.
[ ... 320 words ... ]
Haven't managed to keep blogging here much, though I have been quite busy. Need to think how to make this space more interesting.
Part of what has been holding me back is the interface. I'm used to the style of LiveJournal, where I have a little ubiquitous client that I pop open, jot some notes as fast as I can type, and hit "Post". Here, with Movable Type, things seem a little more sluggish and raises the posting threshold just vaguely above my laziness factor.
But I can't quite get why. I have a bookmarklet that seems just as easy to use as the LJ client. I also have the Blogger API on MT to use, should I want to use one of those clients. Hmm.
I'm also holding out a bit for the tools I've been working on to tie my writing to my wiki. Rather than merge the wiki and the weblog, I'm working on putting the wiki into my textarea.
Holding out is what kept me from putting this site up for years, though.
I need to start blogging in the moment, and keep it flowing. Even if no one's really listening yet.
The other thing is that I'm messing with this division between this space an my LiveJournal. One's personal and the other is... not personal? This space at 0xDECAFBAD is just as personal to me, only it's less interesting to my normal group of friends over on LiveJournal. Seems like there needs to be a bit of a division, but maybe not the gulf between two entire sites' worth of distance.
Seems like I need a categorized UBERblog where all of my weblogging goes, with specialized feeds branched off from it. Seems to me that this is where Radio UserLand could come in, but I need some more tools to make it happen.
You see, although I want an uber-blog with categories, I don't want to leave my "legacy" LiveJournal, so I'd like to turn it into a mirror of a category, maybe with abbreviated notices of postings in other categories. Seems like I need to get a category-to-metaBlogger API tool working in Radio, along with a metaBlogger-to-LJ bridge working.
Until then, I just need to keep making a point to babble in here. It's not as if I don't have things to say from moment to moment.
[ ... 394 words ... ]
I think I need to look into SVG some more. It seems that these things might be interestingly combined:XmlRpcToWikiOPML to SVGTouchGraphWikiBrowserThe current graphical link browser above is a Java applet, but it seems that doing the same thing in SVG might be more interesting. One thing I don't know about SVG is, can one delay sending chunks of the graphic? That is, present a navigable map of the Wiki's pages and links, but not have to query and process the entire content of the wiki to send the SVG file. Just show the relevant parts on demand. Could be fun stuff there.
[ ... 103 words ... ]
Here's something I think could really benefit as an XmlRpcToWiki client: TouchGraph
I have it running right now on my Windows machine, playing around with navigating MeatballWiki, seeing the linkage connections that up until now I'd only seen in my head. It's really great to see them layed out in front of me, and to see them shift and expand an explode as I traverse from node to node. This is cool tech.
The XmlRpcToWiki connection comes in where this app uses some "low tech" methods. The XmlRpc interface explicitly defines getAllPages() and getPageLinks() methods that would be perfect for this app.
[ ... 103 words ... ]
I know everyone else in the world has blogged and linked to these, but:
John C Dvorak slammed and trivialized this. Sam Ruby explains why I've got a weblog on this front page, and what I eventually hope it does for me as I make this place worth visiting.
[ ... 50 words ... ]
I need to get more active with the blog on this site. I've been kind of holding back due to lack of a few blogging tools I wanted to work within (ie. WeblogMulticaster for one, GroupWeblogWithRadioUserLand for another), but I really need to start making this place more worth visiting.
So, if I can get my butt moving, I'll start babbling more into the Tech category and maybe create a few more categories. I'll also try giving access to the categories split out into their own RSS streams and maybe bring more of my personal spews over on http://deus-x.livejournal.com into the fold here.
[ ... 104 words ... ]
Yay! Today DaveWiner gave a shout out for this: RFC: ?MetaWeblog API. It's exactly, precisely, what I wanted. Not perfect, but allowing arbitrary metadata, with a preference toward RSS attributes, is pretty much what I wanted. It's basically what I was going to try to do in a hackish workaround way with in-blog-entry directives processed by a WeblogMulticaster.
Oh, and in other news, there's a quick and dirty implementation of the XmlRpcFilterService for Win32 in the wiki now. More work to do...
(Oh again, the content of this entry is a test of the pipeline hardcoded into the Win32 service. Not perfect yet, but getting interesting at least.)
[ ... 109 words ... ]
This was easier than I thought it would be: XmlRpcFilterService
Basically, this is my first application of the XmlRpcFilteringPipe. On the MacOsX side of things, I implemented a quick standalone service using Marcus Muller's XMLRPC Obj-C framework. On the filter side of things at 0xDECAFBAD, I added the filter methods to my XmlRpcToWiki interface I have running on the DecafbadWiki. So, now there's a filter named 'wiki' on the DecafbadWiki that I call with the XmlRpcFilterService under MacOsX.
The nutshell version of this is: I write something somewhere, select some of it, click "Appname -> Services -> XmlRpcFilterService -> Apply to Selection" in my menu (or use the hot key), and the selected text is filtered through my remote wiki to pick up links and filtering. In the context of a weblog entry, this means that what I write in the weblog is now bound to the wiki. Hell, I can even make my postings to message boards and replies to email pick up links to my wiki. Now that I think of this, I might want to have a selection of an alternate rendering for email, where the links appear at the end of the message as footnotes.
Anyway, it still needs a bit of work to make it more generally useful. It needs some preference panes to change and construct the filter pipe, support multiple pipes, and I need to bundle the XmlRpc frameworks up in the app for easy installation (or switch to Apple's built-in XmlRpc API). But the point is, it took me all of 2 hours between server and client side work to get this working, and it's already useful for me. I'll see soon if the sudden population of links in all of my communication from my laptop annoys anyone. :)
This is one solution for a WeblogWithWiki, but I still want to play around with making the WeblogMulticaster and enabling it to use XmlRpcFilteringPipes also.
And, somewhere, this figures into RadioUserLand.
[ ... 329 words ... ]
In case you're all wondering what I'm doing, I'm moving over to using Radio UserLand to manage my journal and weblogs. I got a tool called xManilaBloggerBridge which binds my Radio UserLand categories to sites that talk BloggerAPI, namely 0xDECAFBAD and my LiveJournal account (via Blogger-2-LiveJournal installed on my webserver). Sound convoluted? It is, and it's about to get even more convoluted.
The end result, though, is that I can write from one spot and publish to many sites, and write some more neato things to automatically process my writing as it goes on its way. (Such as, automatically create links to my wiki, where I maintain pages on long running ideas.)
I am a nerd. I'll try to keep the high nerdity on 0xDECAFBAD and not on my dreamspace. :)
[ ... 132 words ... ]
Okay, cheesy entry title.
Anyway, MailToRSS got mentioned on aaronland. Imagine my surprise when I see my name and blurbage come up on someone else's weblog in my Radio feed. Yeah, yeah, happens every day. But I'm happy to get this stuff noticed and found useful.
Thanks :)
[ ... 49 words ... ]
To steal a page from Dave, I think that this could be a potential mind bomb: The XmlRpcFilteringPipe.
I know I'm not the only one who's thought of it.
In the process of looking for "prior art" right now.
(Okay, yeah, that sounds pretentious. I just wanted to have Mind Bombs on my site, too. :) )
[ ... 58 words ... ]
Welcome RdFlowers!
One quick thought about the wiki: Is the registration requirement preventing anyone from editing my pages? I mostly have it enabled to tag authorship and let contributors set their own options.
Not that I have much in the way of contributors yet, but is this registration thing a major turn off?
Or, it could just be that not too many people even know this site is here yet. :)
[ ... 72 words ... ]
Spent a couple of hours updating the implementations of Main: XmlRpcToWiki. Now, the adaptors to XmlRpc for the three wiki engines (TWiki, ?UseModWiki, and MoinMoin) are mostly in synch, and feature complete as I can see for the moment.
Time to do something useful with them. I think I might push the WeblogMulticaster up a bit in priority. It'd be nice to get weblog posts dipped into the wiki by my blogger tool.
Okay, time for bed.
[ ... 78 words ... ]
Hmm. I've mused about replacing Movable Type with Slashcode and going in one direction on the web app dynamicity scale. What about replacing MT with RadioUserLand?
Might think about that some more. One thing is that it'd probably doom any multi-denizen wistful thinking I have about 0xDECAFBAD since Radio UserLand is a one-person blogging machine.
Or, I could just accept that MT does pretty much what I need. I just want to get this weblog included in on some of the tracking features Radio offers. Hmm.
[ ... 87 words ... ]
Oh yeah, and another new project idea: LiveJournalFriendsReplacementOne of the best features of LiveJournal are Friends. As a LiveJournal user, one may add other journals to one's list and see entries in those journals aggregated together in one spot, similar to what RadioUserLand does with RSS feeds. However, the Friends feature also allows you to see who has added you as a friend to their aggregation view. Furthermore, each Friend is a link to that person's journal and list of friends, allowing one to wander through and navigate the social network of watchers and watched.
RadioUserLand , and weblogs in general, need something as slick and explicit as this. Referral logs are too ephemeral. This is away of explicitly informing each other "I am watching you, and this is who watches me."
[ ... 133 words ... ]
Some quickies:Welcome, MarkPaschal!
I'm giving in and starting to hack on some ?UserTalk in RadioUserLand. Looking for some IMAP support for playing with MailToRSS. Not finding any yet, I'm toying with RepeaterProxy as my first foray into ?UserTalk so that I can use a companion DesktopWebAppServer behind Radio to enable Python web apps, such as components of Caffinate. Need to solve packaging issues once I decide to release and distribute this companion httpd.
Also thinking that WeblogMulticaster might make a decent RadioUserLand Tool.
Still have to get back to XmlRpcToWiki and get the three implementations I have in synch with the API spec. Right now they're diverging.
Okay, back to work.
[ ... 111 words ... ]
Uploaded a partial stab at XmlRpcToWiki for MoinMoin. Have to figure out how to map enumerated versions to MoinMoin's style of diffs, have to update all the implementations with a few changes to the API spec in general. But, I just wanted to get some things out there, even if they're in progress.
[ ... 54 words ... ]
Tweaking around some fonts, layout, etc. Silly me, I've been looking at all of this in Mozilla and haven't touched IE in a week or two. It wasn't pretty when I checked it out there. If anyone ran screaming from this site in funky horror after looking at it in IE, I offer my apologies. Now if only I can get MT to stop doing funky things with apostrophes.
Working on the site design itself more, stripped away the frames (MT's pings to weblogs.com didn't like 'em anyway), having more SSI fun, and generally trying to clean up the second level pages of the site (ie. individual story pages, etc.) Next, I should be making pages to each individual category, if I can figure out what kind of seconday sidebar &etc I want on those pages. Obviously something more understated than the major sidebar on the front page.
This is fun, my first website to actually be up and doing something, even if no one's paying attention yet :)
[ ... 170 words ... ]
It seems like Movable Type does pretty much everything I want it to do for a weblog, and the upcoming v2.0 looks even better. In one sense, I'm not satisfied with the fact that all it does it maintain a static set of pages rather than being a dynamic app... but then I think, do I really need anything more than that? I mean, the one dynamic thing I have on the front page is the recent wiki changes, and that's a server-side include (that almost seems retro to me). Seems to work fine.
The main reason I have a tiny doubt is just having checked out Slashcode again and remembering all the neato stuff it does, including its own wiki plugin. software.tangent.org uses Slashcode, but then they're Slashcode contributors over there if I recall.
I could see MT choking if I had tons of content. Say I update my site's templates again and it has to rebuild everything. Eh, that's a degenerate and least frequent case. And I've got the source, so I could pry my content out of it if I had to.
As things are, the template system is dead simple, and I've started creating categories. Everything Just Works. Maybe I'll go drop a donation in their hat next week...
[ ... 214 words ... ]
Hmm, looks like there's a site over here at TangentOrg that's doing a lot of what I keep thinking I want to do with 0xDECAFBAD. Looking for rolemodels. If you're out there (knocks on your screen), can you point me to any other weblog-ish sites that are kinda about software, kinda about some dude (or dudette), and kinda about the stuff that goes on out there?
I'm sure there're plenty, but I'm looking for not just weblogs, but weblogs that spin off things and make stuff and other crap that sticks around and gets improved, and all that.
Does this make any sense? It's time to go home.
[ ... 109 words ... ]
Hmm, does something like this fit into the "format" of 0xDECAFBAD? Sure, but I'll probably want to consider setting up some categories. Like general tech rant/commentary, 0xDECAFBAD project updates, site updates, etc.
From The Register: How to ?TiVO-ize your PCTiVO-like time shifting capabilities have come to the PC. At the Intel Developer Forum, Rakesh Agrawal, CEO of thirteen-man ?SnapStream, took his PVS software through its paces for The Register's pleasure.
Is it just me, or are these people are slow? Maybe it's just because of the new release of the SnapStream software (which I tried a few months ago, and hated, might be worth a try again), but people all over the blog world have been mentioning this as if it's something new. "TiVO killer on your PC! Check this out!"
The only reason for it I could see is if the SnapStream software has improved incredibly since the last time I played with it, and it's become so dead simple that my Mom can use it by making vague flappy gesticulations at the screen. The only semi-exciting thing I see in the SnapStream buzz is that they're planning on doing something with .NET web services, but no one's really talking about that facet of it.
Maybe they've all missed the availability of these products, but I've been using my ALL-IN-WONDER? RADEON for the past year and a half, before which I used a Voodoo 3 3500TV (which sucked ass), and before that I used a plain old ATI All-In-Wonder card. That's been since I got my first real PC in 1997.
I've been using these cards to record the few shows I care about, in limited fashion, until I got the Radeon card and things took off. With the AIW Radeon, I record straight to VCD format. I burn the VCD movies onto CDRW and watch them in my DVD player, just like I used to use my VCR. If I happen to like the show, I burn it to a real CD and file it away. It's not the greatest quality, but is pretty comparable to VHS, which is fine. If I want better quality, there's Super VCD which uses MPEG-2 to fit 30 minutes of DVD-quality video on a CD. Or... gasp I could get a DVD burner.
And then, there's the D-Link DSB-R100 PC FM USB Radio I've been using to record and archive FM radio shows, most notably Big Sonic Heaven. Oh yeah, and the Voodoo 3500TV was good for that, too. (But mostly, it sucked.)
My digital lifestyle's been kicking it for some time now. Hell, not even Apple's caught up to me yet, since I can't find Mac-OS-X-supported replacements for my cable and FM radio archival rig. If I had the money, I'd switch to 100% Apple in an eyeblink if they could seamlessly replace all the above.
Anyway. I'm done now.
[ ... 479 words ... ]
Brief server outage, swift support response from my friendly local host:It is always something with that wretched httpd. Afew days ago it was a php exploit, preventing the restart of apache, and now this. All the pids which run under httpd must be killed, in order for a restart to take effect. This does not happen automatically, so I must kill them all, manually and with extreme vengence.
[ ... 69 words ... ]
Hacked around tonight looking into the innards of MoinMoin and discovered that things are not all that bad in there. I've got most of a MoinMoin rendition of the XmlRpcToWiki done. I just have to figure out how to map the concept of numerical versions into editlog manipulations.
Whee, after this, that'll be 3 wikis I've thrown this thing at. No sweat. Next, I have to do something with it and prove that it hasn't just been TechQuaTech.
[ ... 79 words ... ]
I doubt that I have much of an audience yet, still, so I suppose this will be just thinking out loud... but hey, that's pretty much the express purpose of this site. The historical context is useful, nonetheless.
Speaking of the purpose of this site: what about the purpose of this weblog? Should this just be for general site news and calls-to-attention, or should I start all out nerdy musing about tech and what's going on out there? I'm thinking the latter, since any glance at the wiki's RecentChanges will get you that.
I have a half-thought notion that I might enfold more people into 0xDECAFBAD eventually, so I'd like to keep the place from being too centered on l.m.orchard, but seeing as I'm the only denizen here for now, it will be.
So, maybe I should elucidate a bit within the site purpose up there in the corner. This is a place for exposed thought processes about developing technologies. Developing being used in a double meaning here-- both as an adjective and as verb.
The purpose of 0xDECAFBAD lies in both discussing the state of and participating in the process of technology building.
How's that? Great. (Suggest refinements, if you like.) Now... "technology" is a fairly broad topic. What technology, exactly?
Seeing as I am the sole dictator of the site's direction so far, I will define this to be technologies that suit my fancy. This, however is no definition-- it's more of a redirection. A see also. So, what technologies, in particular? Here's a list off the cuff:
Collaboration
WritingOnTheWeb
InformationManagement
KnowledgeManagement
This probably needs some fleshing out. In general, the focus is on web and internet tech with a lean toward that which enables human beings to work with information and each other. Mainly, I'm interested in PowerToThePeople rather than TechQuaTech.
How's that for a start?
[ ... 310 words ... ]
Even more twiddling. Seriously thinking of moving the Wiki over to MoinMoin now that I've had a better look. It seems to support almost all of the features I use with TWiki, but looks to have a much cleaner design.
Did some poking tonight, and it looks like I could have yet another implementation of the XmlRpcToWiki for MoinMoin. That would bring me up to a total of 3 supported wikis. After that, I just need to keep them all in synch with the API as it shapes up over on the JspWiki site.
After I get the XmlRpcToWiki implemented for MoinMoin, I can work on the WikiWikiBridge between TWiki and MoinMoin to execute the conversion of content for migration.
The side effect of moving to MoinMoin in this way is that I'll end up with 3 wiki engines speaking XML-RPC, and one bridge between engines. Sounds like fun to me.
[ ... 152 words ... ]
Thinking that simple is better here, so I tossed out the big vertical sidebar navigation for a much simpler nav bar at the bottom. Also playing around with putting wiki changes in the sidebar.
Any thoughts? I think I'll stop twiddling with that for now and play around with getting a few more things released.
Okay, maybe one more tweak. This is not exactly like out-of-box Movable Type, but hopefully not annoying.
[ ... 79 words ... ]
Actually, I have been doing quite a bit. here's a quick update:
I had a go at doing something cool with CommentsInRadioUserland, but I don't think very many people noticed my hacky iframe tricks before a more elegant solution was baked into Radio. Well, I thought it was cool. :)
I released the XmlRpcToWiki for two Wikis, TWiki and ?UseModWiki. I'm aiming for MoinMoin next, and I might even be nutty and convert from TWiki to MoinMoin for usage here.
Started doing the dogfood thing and have been using MailToRSS (based on Caffinate) on a daily basis in my Radio UserLand feed. Seems pretty useful. Going to clean a few things up, upload some files, and bump those two projects up into the "Available" category and make a release.
I ripped the Wiki's style-sheet off and went back to plain old, unadulterated default style. I might try again with a few tweaks, but best to let wikis be.
Thinking I'm going to set aim on the WeblogMulticaster next.
I'll have more to write soon.
[ ... 175 words ... ]
It's worth noting that I'm trying a change in approach now to get my hacking morale up. I'm adopting a more UNIX-y approach and planning to write and release a number of smaller, interoperating utilities at first. They should be really easy to pipe together, like cat | grep | more. They should, at first, run just fine on my laptop Apache installation or out on the 0xDECAFBAD servers. Eventually I might write the overarching DesktopWebAppServer that provides another shell within which they can reside, but I have to get away from my year-long hermitage arcs of development where I make really cool things and get 75% of the way done and then abandon them.
Okay. Nevermind work, it's time to go home. Wheee!
(Grr, and ?TextRouter keeps "helpfully" escaping all my HTML tags with entities. Have to do more digging to work out how to stop that.)
[ ... 149 words ... ]
Oh yeah, and though I'm pretty sure I'm blogging into the void right now, would anyone out there happen to have some tips on how to make my site less ass ugly? :) I've just co-opted the Movable Type out-of-box style, but I think I'll need to move on from that eventually...
[ ... 53 words ... ]
It feels good to have my secret laboratory finally out in the open on the web, for all that I haven't had time to do much with it yet. Maybe I'll make a few releases tonight.
Over the past few days, amongst an unusual amount of social activity, I've been working on MailToRSS, and XmlRpcToWiki for TWiki and maybe UseModWiki.
Of course, as I'm working on that, I'm tossing around the idea of trashing my TWiki installation for a MoinMoin installation. Why? Because I'm starting to really dig Python, because MoinMoin is written in Python, and beyond that the design of MoinMoin seems very well thought out. Whereas TWiki seems a bit "evolutionary," to be charitable. :) I'm not sure yet. One good offshoot of this is that I thought of another idea to throw on my project list: WikiWikiBridge. Granted, I might never do it, but the whole point of this site is to just get all the ideas out there and see which survive and grow, rather than sitting on them because of my perfectionist tendencies.
Also, right now I'm attempting to use Simon Kittle's TextRouter app to post to my MovableType blog on decafbad.com. It seems awfully similar to what I want to do with WeblogMulticaster, and I'd even considered renaming that idea to something "Router" before I saw Simon's app. One of the big differences is that my WeblogMulticaster would be headless, assuming a semi-stupid BloggerAPI GUI program on the user's end, and taking care of all the "text routing" in a remote server or a DesktopWebAppServer installation. But, although rough around the edges right now, and not quite usable under MacOsX at the moment, it might be something I'll try hacking around with first. It's mostly a matter of where the intelligence lies: In the GUI app, or in a desktop server ala RadioUserland.
Anyway, to bring this babble to a close and full circle: I'm thinking of starting my DesktopWebAppServer project as a sort of alongside companion for RadioUserland. I could implement probably all of these things within Radio in ?UserTalk & etc, but I don't like it. I'm liking Python much better lately.
So, it would start out as a companion, and then maybe eventually be a full replacement and competitor for Radio. Maybe. Then again, I might be just lazy enough to decide to stick to complementing and not replacing Radio features, especially after I bought it. So Radio can post to a the WeblogMulticaster in my DesktopWebAppServer project with the BloggerAPI, and then the WeblogMulticaster can take it from there.
Oh and finally, where I want to go with the WeblogMulticaster and the XmlRpcToWiki is to filter weblog entries through whatever wiki engine I'm using. For example: You see all the links in this blog entry? Done by hand. Yes I'm that nuts. Mostly, I just wanted to be thorough in connecting this entry with the wiki on the site and to see how difficult it would be. This motivates me to make a WeblogMulticaster that talks to the XmlRpcToWiki. For a current discussion on this sort of weblog/wiki integration I want, look here: MeatballWiki:WikiLog.
Alright... back to work.
[ ... 529 words ... ]
It's been up for 49 days and has served about 8 people. It's running on a crappy lil 70Mhz HP Vectra PC I found in the dumpster.
It's 0xDECAFBAD BBS, my telnet BBS running Synchronet BBS!
Call on in, either via Java applet on the web (http://bbs.decafbad.com) or via direct telnet (telnet://bbs.decafbad.com:2323) But, it would sure be lots of useless old-school fun to get people playing on here :)
I haven't done a whole lot of work on it yet, other than putz around with an ANSI logo, and a few hours' nostalgic gathering and installing of BBS Door games (Legend of the Red Dragon, anyone?)
Let's see how long I can go before Comcast finds it and shuts me down, whee!
[ ... 123 words ... ]
I'm stalling. I'm procrastinating. I'm tweaking. I'm putzing around.
It's time to commit to Release Early, Release Often for once.
So, here it is. The "launch" of 0xDECAFBAD.com, my attempt at opening up the process, my process, in order to get some impetus to actually get a few of these things done.
Thus far, I've been working out of my own little cathedral cloister, spinning away at projects and technologies that never see the light of day, no matter how cool they are. But damn it, I'm tired of the old pattern, over and over again: Never being satisfied to release what I'm working on, only to see someone else release their own version of the Cool Thing, while I abandon my work to a discouraged oblivion.
And I do think I'm clever, and I do think I have a few cool ideas. Now it's time to put it out there and get made fun of.
So... welcome. Come on in.
[ ... 162 words ... ]
Heh, now I know I'm just blogging out into the ether right now to make sure everything's working, but it amuses me that I'm blogging about getting the blogger blogging. Maybe I should really be writing about this in my personal blog :)
[ ... 44 words ... ]
One customization I made to the front page blog in trying to be cute: coffee rings all over the place. Is it exceedingly annoying?
[ ... 25 words ... ]
I just got the wiki up and running. Now I have to clean a few things up since I copied the content up from an old backup of my personal wiki from my laptop. For now, things might not make as much sense as they should.
[ ... 47 words ... ]
This Movable Type default template is beautiful. I might change it, then again I might not. Sure it's the out-of-box experience, but hey. And this is a useless entry to try to flesh out the skin table.
[ ... 38 words ... ]